30年後読んでも面白いであろう海外SF小説10選
これはなに
ここ3-4年、散発的にSF小説を読むにつれSF小説好きとしての自認が徐々に強くなってきた。そこで、大した冊数もない自分の既読本の中から、特に面白いと思ったものを挙げて自分の考えをまとめる。
このリストの中で一番古い作品は1949年の一九八四年で、一番新しい作品は2019年の息吹だ。基本的には SF は新しいものが良い。科学技術の発展とともに生活様式や社会が変わり、想像力の土台となる常識が更新されていくからだ。一方で、それと同時に普遍的なテーマを取り扱った SF は古びれない。70年以上前に書かれた一九八四年やファウンデーションは今読んでも傑作である。特に銀河を旅するような遠未来を描くハードSFは、舞台が現代社会から時空間共に離れているため普遍的なテーマを選ばざるを得ず、その傑作は30年後読んでも今と変わらず面白いだろう。自分がハードSFを好んで読む理由と今回のリストにハードSFが多く含まれている理由がそれだ。
30年後読んでも面白いであろう海外SF小説10選
息吹 (テッド・チャン)
「あなたの人生の物語」を映画化した「メッセージ」で、世界的にブレイクしたテッド・チャン。第一短篇集『あなたの人生の物語』から17年ぶりの刊行となる最新作品集。人間がひとりも出てこない世界、その世界の秘密を探求する科学者の、驚異の物語を描く表題作「息吹」(ヒューゴー賞、ローカス賞、英国SF協会賞、SFマガジン読者賞受賞)、『千夜一夜物語』の枠組みを使い、科学的にあり得るタイムトラベルを描いた「商人と錬金術師の門」(ヒューゴー賞、ネビュラ賞、星雲賞受賞)、「ソフトウェア・オブジェクトのライフサイクル」(ヒューゴー賞、ローカス賞、星雲賞受賞)をはじめ、タイムトラベル、AIの未来、量子論、自由意志、創造説など、科学・思想・文学の最新の知見を取り入れた珠玉の9篇を収録。
https://www.amazon.co.jp/dp/4152098996/
あなたの人生の物語(テッド・チャン)
地球を訪れたエイリアンとのコンタクトを担当した言語学者ルイーズは、まったく異なる言語を理解するにつれ、驚くべき運命にまきこまれていく…ネビュラ賞を受賞した感動の表題作はじめ、天使の降臨とともにもたらされる災厄と奇跡を描くヒューゴー賞受賞作「地獄とは神の不在なり」、天まで届く塔を建設する驚天動地の物語―ネビュラ賞を受賞したデビュー作「バビロンの塔」ほか、本邦初訳を含む八篇を収録する傑作集。
https://www.amazon.co.jp/dp/4150114587/
三体(劉 慈欣)
物理学者の父を文化大革命で惨殺され、人類に絶望した中国人エリート女性科学者・葉文潔(イエ・ウェンジエ)。失意の日々を過ごす彼女は、ある日、巨大パラボラアンテナを備える謎めいた軍事基地にスカウトされる。そこでは、人類の運命を左右するかもしれないプロジェクトが、極秘裏に進行していた。 数十年後。ナノテク素材の研究者・汪淼(ワン・ミャオ)は、ある会議に招集され、世界的な科学者が次々に自殺している事実を告げられる。その陰に見え隠れする学術団体〈科学フロンティア〉への潜入を引き受けた彼を、科学的にありえない怪現象〈ゴースト・カウントダウン〉が襲う。そして汪淼が入り込む、三つの太陽を持つ異星を舞台にしたVRゲーム『三体』の驚くべき真実とは?
https://www.amazon.co.jp/dp/B08KWLBML3
ファウンデーション(アイザック・アシモフ)
銀河系宇宙を支配する大銀河帝国に、徐々に没落の影がきざしていた。ひとたび銀河帝国が崩壊すれば、各太陽系は小王国に分裂し、人類はふたたび原始の暗黒時代に逆行する運命にあった。このとき現われた天才的な歴史心理学者ハリ・セルダンの予言は? 巨匠の最高傑作たる未来叙事詩三部作。ヒューゴー賞受賞作。新訳決定版。
https://www.amazon.co.jp/dp/4488604110/
ハイペリオン(ダン・シモンズ)
28世紀、宇宙に進出した人類を統べる連邦政府を震撼させる事態が発生した!時を超越する殺戮者シュライクを封じこめた謎の遺跡―古来より辺境の惑星ハイペリオンに存在し、人々の畏怖と信仰を集める“時間の墓標”が開きはじめたというのだ。時を同じくして、宇宙の蛮族アウスターがハイペリオンへ大挙侵攻を開始。連邦は敵よりも早く“時間の墓標”の謎を解明すべく、七人の男女をハイペリオンへと送りだしたが…。ヒューゴー賞・ローカス賞・星雲賞受賞作。
https://www.amazon.co.jp/gp/product/B00EQ0Q78O
エンダーのゲーム(オースン・スコット・カード)
地球は恐るべきバガーの二度にわたる侵攻をかろうじて撃退した。容赦なく人々を殺戮し、地球人の呼びかけにまったく答えようとしない昆虫型異星人バガー。その第三次攻撃に備え、優秀な艦隊指揮官を育成すべく、バトル・スクールは設立された。そこで、コンピュータ・ゲームから無重力訓練エリアでの模擬戦闘まで、あらゆる訓練で最高の成績をおさめた天才少年エンダーの成長を描いた、ヒューゴー賞/ネビュラ賞受賞作!
https://www.amazon.co.jp/dp/4150119279/
竜の卵(ロバート L.フォワード)
ほんの数日間のファーストコンタクトの様子を書きながら、同じ時間に進んでいく、外宇宙文明の歴史小説でもある奇妙なSF。 それを実現させるために、人類の100万倍の速度で生きる「チーラ」とよばれる中性子星人が登場。 彼らの一生が人類の15分であるため、直接のコンタクトはほぼ不可能であるが、それでも互いを理解するために行われる通信。 そして、ついに10秒間の物理的なファーストコンタクトが実現する・・・。 ロバート L.フォワード 竜の卵 - かせいさんとこ
https://www.amazon.co.jp/dp/4150104689/
ブラインド・サイト(ピーター ワッツ)
突如地球を包囲した65536個の流星の正体は、異星からの探査機だった。調査のため出発した宇宙船に乗り組むのは、吸血鬼、四重人格の言語学者、感覚器官を機械化した生物学者、平和主義者の軍人、そして脳の半分を失った男。彼らは人類の最終局面を目撃する―。ヒューゴー賞・キャンベル記念賞・ローカス賞など5賞の候補となった、現代ハードSFの鬼才が放つ黙示録的傑作!
https://www.amazon.co.jp/dp/4488746012/
星を継ぐもの(ジェイムズ P.ホーガン)
月面調査隊が真紅の宇宙服をまとった死体を発見した。すぐさま地球の研究室で綿密な調査が行なわれた結果、驚くべき事実が明らかになった。死体はどの月面基地の所属でもなく、世界のいかなる人間でもない。ほとんど現代人と同じ生物であるにもかかわらず、5万年以上も前に死んでいたのだ。謎は謎を呼び、一つの疑問が解決すると、何倍もの疑問が生まれてくる。やがて木星の衛星ガニメデで地球のものではない宇宙船の残骸が発見されたが……。
https://www.amazon.co.jp/dp/448866301X/
一九八四年(ジョージ・オーウェル)
“ビッグ・ブラザー”率いる党が支配する全体主義的近未来。ウィンストン・スミスは真理省記録局に勤務する党員で、歴史の改竄が仕事だった。彼は、完璧な屈従を強いる体制に以前より不満を抱いていた。ある時、奔放な美女ジュリアと恋に落ちたことを契機に、彼は伝説的な裏切り者が組織したと噂される反政府地下活動に惹かれるようになるが…。二十世紀世界文学の最高傑作が新訳版で登場。
https://www.amazon.co.jp/dp/B009DEMC8W/
雑記: 読む本の選び方
今昔含めて世界で出版されたSF小説は膨大な数ある。人生は有限で、面白い本、自分に合った本を優先的に読みたい。そのためこんな感じで自分が読むSF小説をフィルタすることで、ある程度クオリティを担保している。
- 翻訳物: 翻訳されたものは当地で売れた、翻訳者と編集者のお眼鏡にかなったなど、一定のクオリティが期待できる。大森望さん訳の本は特に信頼できる
- 受賞歴: ヒューゴー賞、ネビュラ賞、ローカス賞などのSF関連の賞を複数取得していると基本的にクオリティが高い
- その他: 人がブログ記事や書籍中で紹介しているもの、何らかのランキングに載っているもの
上記の条件下にあるような本を手に取り、あらすじを見て気になるものを選んでいる。 もちろん日本のSFも読むし例外はあるので、結局は自分の直感に従う。
おわりに
この中で普段SFを読まない人、時間がない人に一冊だけ勧めるとしたらテッド・チャンの息吹を勧める。一番好きな作家を一人挙げろと言われたらテッド・チャンを挙げるだろう。この中で順位を着けるなら、上位三つは息吹、ハイペリオン、ファウンデーションだ。
ファウンデーションはAppleTV+でドラマ化されたのを見たが、小説とは別物になっていた(映像は良かったが、脚本が微妙な出来だった)。砂の惑星デューンの映画化は小説に割と忠実に作られていたが、それでも映像作品は派手な動きと音楽、見たことのない画を楽しむもので、小説とは楽しみかたが違うなと感じた。長大なストーリーと緻密な設定や世界観を楽しむには小説の方が向いており、上記リストにはそんな感じの作品が多い。
SF小説を読むことは、想像力は豊かにし、柔軟な思考を育んでくれる。その他の文学と同様に社会の一面を切り取り啓蒙したりもする。近年ではSFに注目したビジネス書も出版されるなどその効用に注目されていたりもする。
しかし、個人的には、SF小説にはそんなビジネスの道具として効能を求めるようなつまらない期待はせずに、好奇心を刺激し、自分の常識を揺さぶってくれるような強烈なエンタメとしてのSF小説との出会いを今後も楽しみにしていきたいと思う。
Modern Data Stack / モダンデータスタックというトレンドについて
- はじめに
- Modern Data Stack ?
- Modern Data Stack の特徴やメリット、関連するトレンド
- 各社ファウンダーが考える Modern Data Stack
- さいごに
- Further Readings
はじめに
Modern Data Stack というワードを最近よく目にするようになった。あまり日本語の情報も多くなさそうなのでその周辺情報をまとめてみる。
Modern Data Stack ?
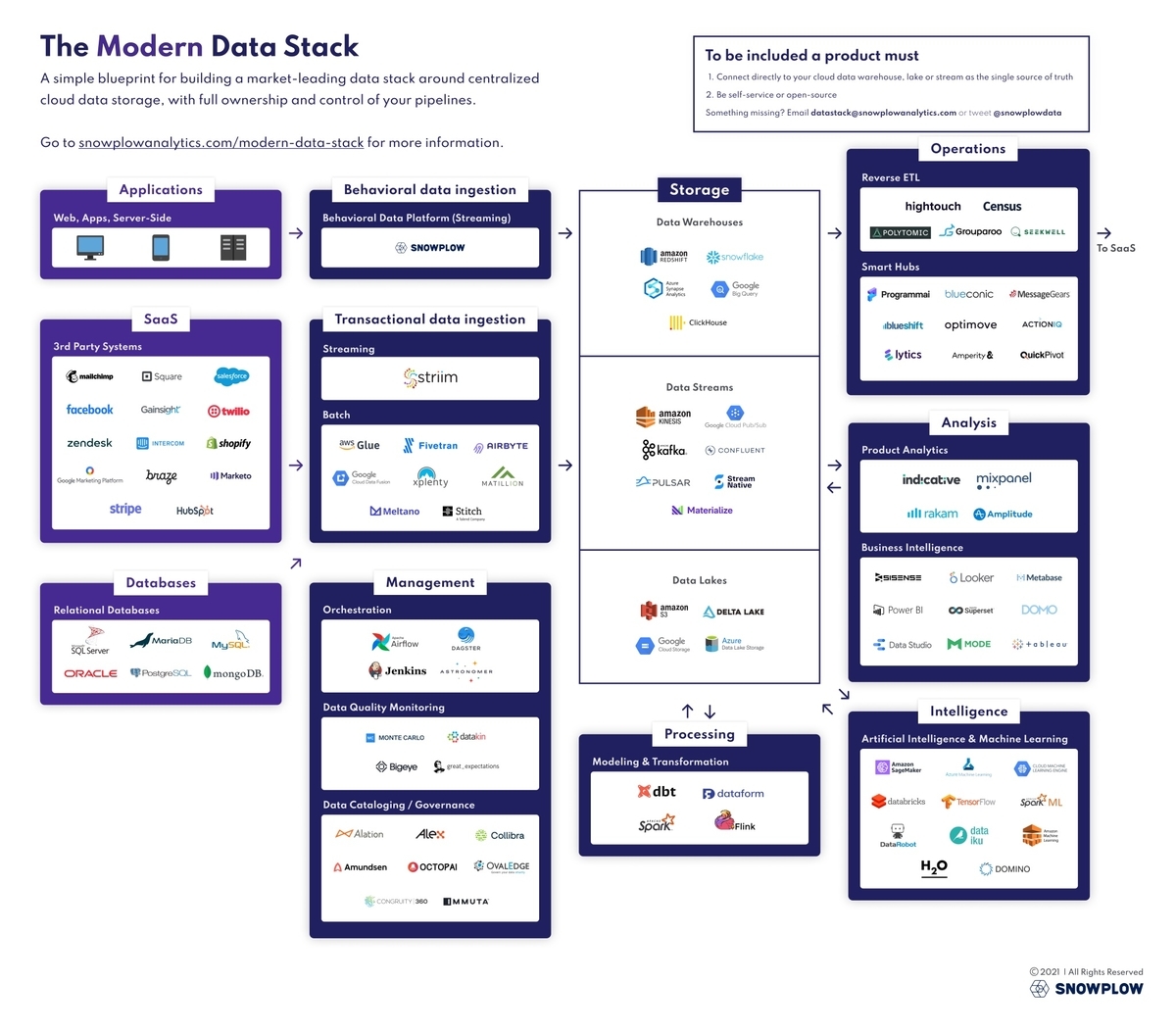
Modern Data Stack とは、10-20年くらい前からあるデータ処理関連のサービスやソフトウェアと比べて、現代の環境に相応しい設計やコンセプトを提案するような新しいサービス・ソフトウェア群自体、またそれに伴いデータをよりよく取り扱うための方法論や今後の行く末について議論が活発になっているというトレンドを表すバズワードである。 基本的にはツールとしてはクラウド化や周辺技術の進化により、スケーラビリティが高くなったり、特定用途に特化し技術的知識があまり要らなく簡単な設定のみで動く、低コストで要望を実現できるなど、利便性が向上しているという特徴がある。
2020 年からは Modern Data Stack Conference が fivetran 主催で行われていたりするので、アップデートにはその辺を参照すると良い。
Modern Data Stack の特徴やメリット、関連するトレンド
下記の Preset 社のブログ記事が情報量も多く面白かったので、以下ではこちらの記事をもとに、あわせて他の記事も参照して自分の感想も加えながらそのトレンドをまとめていく。ちなみにこの記事は、Airflow、Superset のクリエーターの Max Beauchemin 氏のものである。さすが。
データインフラのクラウドサービス化 / Data infrastructure as a service
Snowflake, BigQuery, Firebolt, その他 Managed Airflow サービスの登場など、各種データインフラはマネージドサービスとして提供されるようになっている。それにより、エンジニアがデータインフラを構築する場面は確実に減っている。 代わって、データエンジニアリングチームは、ツールの選択、統合、およびコストの抑制に今後ますます関与していく必要がある。
- 調達 / procurement
- 技術やベンダーの調査、コンプラインアンスや各種ポリシーや導入コスト対効果の評価
- インテグレーション / integration
- 異なるツール間のインテグレーションは大変
- コストコントロール / cost-control
- 従量課金制で青天井なサービスなんかを使う時は、実際に払っただけ価値が出ているかを考えないといけない
関連ツールがさまざま出てきている昨今、トレンドをキャッチアップして正しく技術選定することで結果には大きな差が生まれるだろう。組織に合わないツールを導入することでオペレーションコストや実費には何倍、何十倍もの差が生まれる。
データ連携サービスの発展
昔は各種 SaaS 上のデータを連携するためにコードを書いていたが、データ連携のための Fivetran などのサービスや Meltano や Airbyte みたいな OSS の登場によってそのような問題は解決された。現代でゼロからそのような連携の仕組みを自社開発する必要はない、という話。
ELT! ELT! ELT!
DWH の進化で分散処理が手軽になるにつれて、データのあるところで変換処理をするべきだという話。
ETL よりも ELT をしろってのは最近のトレンドではないが、ますます一般的になるはずってのはまあその通りだと思う。Spark において SparkSQL の重要性が増しているように、同じコンポーネントでデータの変換と分析という本来は異なるワークロードができることが当たり前になっていき、ますます ETL システムがデータベースみたいに振る舞うことが多くなっていく。ストレージとコンピュートの分離も進んでいるので、Spark とか Presto とかをみるとそうだよねという感じ。まだまだ、任意の処理を実行するって感じではないけど、UDF とか独自関数の発展をみると良くはなっている。このトレンドが dbt による ELT の管理というニーズとつながっている。
Reverse ETL
Reverse ETL については下記の記事で紹介したので割愛する。
Max Beauchemin は Reverse ETL をかつての Master Data Management (MDM) のサブセットであるみたいな紹介をしており、EAI とか EII とか勉強しても面白いかもよって言っている。
テンプレート化された SQL and YAML などによるデータの管理
ELT の一般化によって、データの管理はテンプレート化された SQL や YAML によって行われるようになってきている。 SQL はすでに標準化され成熟したインターフェイスであり、テンプレート化も容易で柔軟性も与えられるし、コード管理できCI/CDも適用可能であるためである。 この辺は k8s によりリソースの宣言的な管理が進むインフラ周りと同じ方向に進んでいる。 Connor’s McArthur’s 2018 talk “KISS: Keep it SQL, Stupid” がおすすめ。
そのようなトレンドがある一方で Max Beauchemin は、PHP + HTML が古びれていったように、SQL のテンプレート化による手法も表現の多様化には対応できなくなる可能性があると指摘している。例えば SQL のテンプレート化の問題点の一つとして、異なる SQL 方言間で reusable でないということを挙げている。ここにはまだ適切なプログラミングモデルが登場する余地がある。
セマンティックレイヤーの凋落と Headless BI
DWH 上のデータはスタースキーマやスノーフレークスキーマなど物理的な実体として存在する。そのまま利用するには各テーブル間の関係性などの知識が必要とされるために利用しにくい。そこで、DWH 上の物理的なデータをビジネスドメインの概念モデルに近づけ利用しやすくすることがセマンティックレイヤーの基本的な目的である(ざっくり)。
BIやDWHやETLツールなどのレイヤーがそのためソリューションを提供している(LookerのLookML、MicrosftのOLAP、TableuのLogical Layerなど)。複数の理由から(複雑すぎる、機能が製品をまたぐことができない、コード管理できないなど)それらの機能は決定的なものにならず、最近ではセマンティックレイヤーは非正規化され実体をもったデータとして(データマートとして)構築されることが多い。つまり、今日ではセマンティックレイヤーの実体はトランスフォームレイヤーに吸収されている。その結果、dbt などのツールが ELT の実行管理だけではなく、Data Lineanage など含めセマンティック管理の機能も搭載され、勢力が拡大している。
一方で、最近は Headless BI という概念も登場しており、セマンティックレイヤーの再興を促す動きもある。
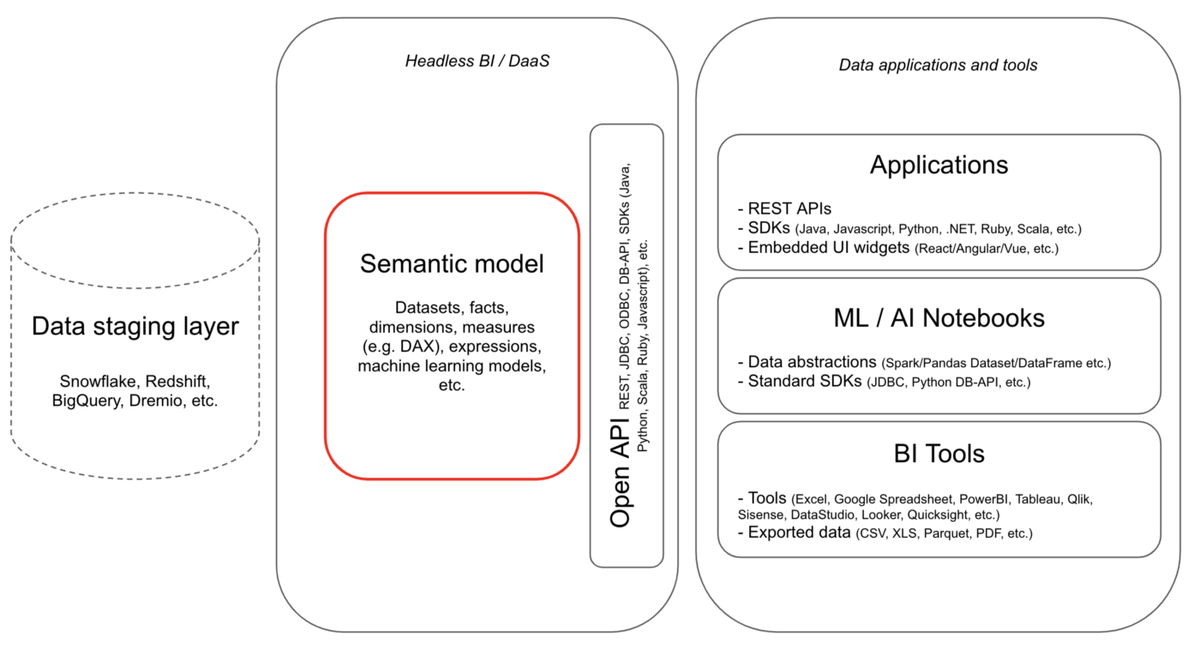
headless bi | base case capital
ちょうど今月リリースされた Supergrain は Headless BI を謳っており、コードによるセマンティックの管理と複数のインターフェイスによるデータをサーブする機能を提供する。
計算フレームワーク (Computation Frameworks)
上記で紹介した Supergrain のような Headless BI ツールにも関連するが、トランスフォームレイヤーに集約されたセマンティックの再利用性を高めることで、なんらかのドメインに特化したデータ変換フレームワークが登場してきている。
- metrics layer ( Airbnb's Minerva, Transform.co, MetriQL, Supergrain)
- feature engineering frameworks
- A/B testing frameworks
まだ、そこまでツール群が成熟している様子はないが、確かにメトリックの管理などはどの会社のデータ管理の中でも不可欠なものだし、それに特化した管理ソフトウェアが欲しいなと日々感じている(dbt にもメトリクス管理機能が実装されたっぽい)。
個人的にもこのレイヤーの発展は気になっているが、Max Beauchemin はこの概念を “data middleware”, “parametric pipelining” or “computation framework” と呼んでおり、また後で記事書くとのことで楽しみにしている。
分析プロセスの民主化、データガバナンスとデータメッシュの試み
Modern Data Stack は分析プロセスを民主化し、その結果、データを扱う仕事が遍く増える。ガバナンスの重要性が高くなるのは言うまでもない。この分野の製品は古くから存在するが(Collibra, Alation etc...)、エンタープライズに特化しており普遍的に使い勝手が良いものではなかった。そのため、スタートアップ各社は自社でそれ用のソフトウェアを作り運用するような状況が生まれていた。
- Linkedin: DataHub
- Lyft: Amundsen
- WeWork: Marquez
- Airbnb: Dataportal
- Spotify: Lexikon
- Netflix: Metacat
- Uber: Databook
要件に差はあるが需要があることは間違いないため、DataHub や Amundsen はスピンアウトし、マネージドサービスとして提供がなされはじめた(それぞれ Acryl Data, Stemma)
組織が大きくなるにつれ中央集権型のデータ管理は問題や労力が大きくなってくる。その結果、最近ではデータメッシュなどのキーワードも提起され、データの各エンドユーザーからなるそれぞれのドメインエキスパートがデータの品質・SLA に責任を持ち、組織全体にデータを提供する非中央集権型データガバナンスが模索されている。そのような組織では、データエンジニアリングチームは、組織の他のメンバーにベストプラクティスを指導、教育、および権限を与える上でその役割を果たすことになる。一方で、データがどのチームに所属するかなど自明でないことも多く、必ずしも簡単に導入できるものではないことに注意する必要がある。
プロダクト組み込み用データサービス
何らかの製品があったとき、ユーザーはその製品上のデータを利用することは必須である。それは REST API 経由かもしれないし、管理画面のダッシュボード経由かもしれない。一方で、基本的で一般的なニーズであるにもかかわらず、製品にそのようなデータ機能を組み込むための開発をする労力はとても大きい。この問題は単一の機能を持った製品が解決する問題というよりは、マネージド BI の Superset による組み込みダッシュボードの外部化、Supergrain のような Headless BI レイヤーによるデータと結びついたインターフェイスの提供など、各種アプリケーションの発展によるものになるのかもしれない。
リアルタイム
データをリアルタイムに活用できるようにするという夢は昔から語られている。製品内部で行うユーザーへのレポートをリアルタイムにできれば嬉しい、自社内のデータを簡単にイベントドリブンで利用、オペレーションに活用できたら嬉しい。ほぼリアルタイムのマテリアライズドビューをサポートしたPostgres互換のデータストアである Materialize 、CDC ベースのリアルタイムデータパイプライン構築サービス meroxa (マネージドDebezium?)など出てきているが、果たして今回は成功するのか。
Analytics Engineer の登場
これまでデータエンジニアはデータ基盤を管理し組織横断でデータ活用の面倒を見てきたが、今後はその需要の高まりに応じて、水平な役割を持つデータエンジニアのほかに特定のプロダクトやチームに紐づく Analytics Engineer として垂直の役割をする新しいロールが活躍できるだろうという話。その役割は、dbt Labs のブログ記事中によくまとまっている。
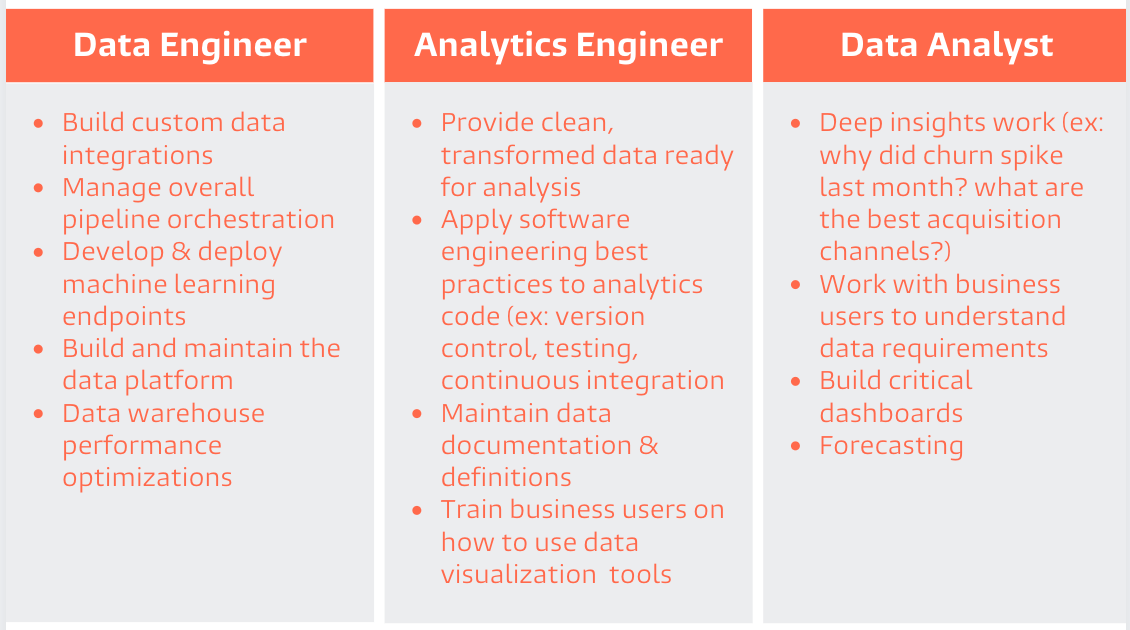 What is Analytics Engineering?
What is Analytics Engineering?
Web 開発において、フロント、バックエンド、フルスタックみたいな役割の違いがあるように、組織の中でのカバーする領域が異なるのは自然に思う。データ関連の職種はさまざま生まれつつある( “Data ops”, “data observability”, “analytics engineering”, “data product manager”, “data science infrastructure” etc...)。
各社ファウンダーが考える Modern Data Stack
最後に Modern Data Stack とは?という質問に対する各社ファウンダーの回答をまとめた記事を紹介する。 興味深いので是非読んでみて欲しい。
個人的には Census CEO の「データはプロダクト化される。そのためにデータチームをプロダクトチームのように“software-ification”するためのものがModern Data Stack」って見方が面白かった。
Data itself is turning into a product that serves all these various use cases, specifically because it is horizontal. So now the only way for a team to reach all the various stakeholders, if it's going to be horizontal, is to think and deliver like a product team. So to me, the Modern Data Stack is the “software-ification” of data organizations, turning what they do into an agile, business-like operational model.
Software Engineering の手法が進化していった後をついてデータ管理・活用の方法がこれから洗練されていくのだろう。
さいごに
ということで、Modern Data Stack についてまとめてみようと思ったら、思ったより長くなってしまったし細かいところで雑になってしまった。各論それぞれ掘り下げがいがあるのでまた記事にでもしたい。
Further Readings
CREを一年やってみたサマリー
転職して一年経過した
CREとしてTDに転職して、一年経過したので今の所感とどんなことやったのかをまとめる。
一人目ロールのCRE
前々職ではAWSインフラに詳しくなって、前職でデータ基盤の開発・運用をした。データ基盤の開発運用は基本的には保守的な活動である。次の職では、会社のKPI改善をより直接サポートできるような領域をやっていきたいと思い、これまでの知見を生かしてデータ基盤の上のレイヤーの活用領域を出来れば良いなと思っていた。TDで募集していたCRE職は、サポートチーム内の一人目ロールで自由度が高く、期待されることも希望に近かったためちょうど良かった。Pre IPOのグローバルSaaS企業の求人はそんなに多くはない。
とりあえずの基本方針として、ICであり特に指示できるメンバーもいないため、各チームのニーズを受けて自分の動ける範囲で手を動かし、まずは短期的に結果が出るタスクに注力した。徐々に触れる領域を増やしていきながら、その中で成果が出て引き合いが強いものに集中的に時間を使い、目に見える成果を積んで信頼を稼いだ。
多分にもれず、TDのCREはGoogleが当初提唱したカスタマーフェイシングなSREっぽいロールとはちょっと違う。直接的・間接的にカスタマーのためになることなら何でもやるプロダクト開発はしないエンジニアロール的な感じである。Data Engineer みたいにデータ基盤の開発・運用に軸足があるでもなく、Analytics Engineer みたいに分析業務に特化しているわけでもなく、データとシステム化でさまざまなオペレーションをエンハンスしたりするような雑多な仕事をしているので、ラベルはCREよりただのSysDEや素直にSoftware Engineerでも良いのかもしれない。きっと企業規模が大きくなると各チームに専属のSoftware Engineerがアサインされるんだけど、今はそこまで大きくないから色々面倒を見ているだけかもしれない。
所属しているのはカスタマーサポートチームだけれど、雑多に色々なチームと一緒に仕事をしている。やってきたことは、具体的には以下の通りである。
やったこと
カスタマーサクセス領域
- カスタマーヘルスダッシュボードの構築
- カスタマーサクセスチーム向けに任意のカスタマーの状況やその推移を一覧できるダッシュボードを構築している。CSOpsやっているカスタマーサクセスマネージャー(CSM)が主に要件をまとめ、自分がそれを元にデータを集め、データマートを作って提供した。既存データの把握やワークフローの引き継ぎ、項目追加のパイプラインの改善など、諸々スピーディに対応した。
- ツールとしてはTDをそのまま利用していて、Digdagでワークフローを書いて、PrestoでTransformしている。
- TDには独立したデータチームが存在しており社内データを整備してくれていたため、自分は簡単なデータマートを用意するだけでスムーズに導入できた。
- カスタマー向けメール通知の実装
- インターナル向けSlack通知の実装
- 担当カスタマーの利用状況になんらかの変化があったときに Slack でメンションされるようなもので、必要なデータを揃えながらひとつひとつ実装を進めている。アクションに繋がる通知を用意するのはなかなか簡単ではない。
- 将来のカスタマー利用量予測
- CSMがカスタマーとコミュニケーションをする際に利用することを想定した予測値を計算した。上記のインターナル向けの通知やダッシュボードでの表示に利用することを想定しており、そこまで複雑なモデルで高い精度を目指すものでないので、簡単に線形回帰で PoC してみてぱっと見で使えそうなところだけ導入することにした。
カスタマーサポート領域
- 地道なデータ整備
- サポートに利用する必要があるけど開発者しか確認できないような状況にあるようなデータを、サポートでも利用できるように整備する日々の活動もデータチームと協力しながら行っている。
- Hive バージョンマイグレーション状況確認用のダッシュボード
- カスタマーのマイグレーション状況を確認するためのもの。サポートチームメンバーでも全然対応できるんだけど、データ追加が必要で全般的に把握している自分が対応するみたいに分業できるとまあ効率が良いでしょう。
- サポートチーム向けの社内ツールを開発するサイドプロジェクト的なもの
プロダクト領域
- PM向けダッシュボード
- ProductOps メンバー主導で、プロダクト開発サイクルで使われるメトリックのためのパイプラインを用意した。さまざまなメトリックとダッシュボードを作成したが、実際のところ現時点で有効活用されておらず、これは用途に目を向けない要件定義が原因だったと反省している。次回からは要件定義段階から深く食い込めないものにはコミットしないくらいでも良いかもしれない。
- 簡単なプラットフォーム活用状況分析
- feature flag の有効化数の推移から、ファネル分析や、有効化されていない機能や特定機能がどれだけ稼いでいるかを可視化した。プロダクト開発の優先順位決定に利用できるものかと思っている。
- カスタマーとデータ共有をするためのソリューション開発
- UX の改善にはプロダクトの改善や開発へのコミットが近道である。現在所属するサポートチームはカスタマーフェイシングな機能開発ノウハウがあまりないため、試行錯誤、紆余曲折ありながら苦労して進めている。
その他オペレーション領域
- bot 開発
- 各種社内メンバーのオペレーションを改善するため、bot を開発していくつか機能を実装した。
- TDにはクエリの実行結果を簡単に可視化する機能がないため、Job ID を渡すとクエリ結果を使ってグラフを描いてくれる機能を用意した。
- その他、Box上のファイルが更新されたら通知する機能やTableauのチャートをSlackに通知する機能など(この同様の機能は後にTableauによってサポートされた)。
PoCした。初めて bolt 使って bot 作ったけど楽しい。 pic.twitter.com/aFBtGXz1IV
— 🐘 (@satoshihirose) June 18, 2021
できなかったこと・今後やっていきたいこと
- Cost・Performance 観点での利用方法の最適化やフィードバック
- 実行されている無駄な処理を見つけてそれを無くすことができればカスタマーもプラットフォームもハッピーである。この辺できてないなーって言ったら、同僚がアイディアを出してくれて早速今月から動き始めることができたので、二年目はその辺もっとやっていきたい。
- プロダクト改善活動
- 自分はプロダクトを開発するエンジニアではないけれど、やっぱりCXを改善するにはプロダクトが良くなることが一番なので、その辺にうまく貢献するやり方を見つけられれば良いな。必要な労力もそれだけ大きいため片手間ではできないという実感はある。
まとめ
一通り自分が覚えている範囲でこの一年に試みたことを挙げてみた。上手くいったものと上手くいかなかったものがある。CREとして一人目ロールであり、ニーズベースでさまざま雑多な取り組みに関わっていったが、もうちょっと反省点やCREロールのあり方を整理をして、次の一年間に活かしていきたい。
[PR] 求人
最後は、求人の宣伝になります。今はタイミングが良いのでお話し聞くだけでもお気軽にどうぞ〜。現時点では CRE とか Data Engineer みたいなポジションは空いてないかもしれないですがそのうち空くかもしれません。チーム間の異動やロケーションの異動も割と目にするので、フレキシブルにキャリア考えている人にとってもいい環境なんじゃないかなと思います。
今どんな感じか気になる人はカジュアルにvideo chatしますのでお気軽にDMください〜。 Careers - Treasure Data https://t.co/crCSOHaPj6
— 🐘 (@satoshihirose) November 4, 2021
最近SREチームへの留学やUKへの異動が決まったメンバーがいたり将来の柔軟な働き方を検討できるグローバグで数百人程度の規模のSaaS企業で英語を使いながらサポートエンジニアをするキャリアはいかがでしょう。[PR]
— 🐘 (@satoshihirose) October 28, 2021
Treasure Data - Technical Support Engineer (Japan) https://t.co/Om4huU5Y3o https://t.co/UiC3vbm1bv
行ってみたいリゾートホテル3選、2021年夏
新婚旅行でバリに滞在したときの体験が良かったので、人生で財布に余裕ができたらまたリゾートホテルに滞在したいなと思っていたが、コロナ禍で目処が立たなくなってしまった。時間もあり Apple TV 4K も少し前に購入したので、滞在するとしたらどこが良いかなーと YouTube をザッピングしていたりしている。実現性はともかくこのリゾートホテルに行きたいなと思ったところを紹介する。
Maldive | Soneva Fushi
モルディブの海は一度見てみたい。モルディブには死ぬほどホテルがあるが、その中でも独特の哲学を表現している Soneva リゾートが気に入った。
About Soneva | Discover Soneva's SLOW LIFE philosophy
ホテルとは関係ないが、上記動画元の YouTuber の他の映像もクオリティが高くて良い。
Saint Lucia | Jade Mountain Resort
カリブ海の島国、セントルシアにあるリゾートホテル。山と海を同時に臨むダイナミックな情景が良い。上記動画中のオープンエアーの壁がない部屋に泊まってひたすら景色を眺めたい。
Bali | THE APURVA KEMPINSKI BALI
バリ島のヌサドゥアエリアに 2019 年にオープンしたホテル。とても背の高いロビーとそこからの眺め、水槽に囲まれたレストランがとても印象的。やっぱりスケールの巨大な建築は良い。
感想
上記でわかるように、青い海、白い砂浜みたいな典型的なビーチリゾートが好きなようだ。高原とか雪山、みたいなリゾートも世の中にはあるが、やはりリゾートは水平線を臨む南の島が良い。
dbt on Treasure Data with dbt-presto の動作確認をした
サマリー
- dbt が Treasure Data で動くか試してみた。
- 結果としては dbt-presto の修正が必要そうで現状のままでは動作しないことが確認できた。
- 果たして dbt-presto に Treasure Data に合うようなモードを追加するのが良いか、 dbt-athena のように別なプラグインとして提供するのが良いか。
dbt on Presto
以前の記事で少し触れたように dbt は Presto 用のプラグイン dbt-presto を用意しており、現時点では一部機能のみ使用することが可能である。
Due to the nature of Presto, not all core dbt functionality is supported. The following features of dbt are not implemented on Presto: 1. Snapshots 2. Incremental models
Trino でも問題なく動くようだ。
Trino + dbt = a match in SQL heaven? | by Victor Coustenoble | Geek Culture | Medium
動作確認手順
インストール
dbt, dbt-presto をインストールし、プロジェクトを作成する。
$ python3 -m venv venv $ source venv/bin/activate $ pip install dbt-presto $ dbt --version installed version: 0.20.0 latest version: 0.20.0 Up to date! Plugins: - presto: 0.20.0 $ dbt init dbt-td-sample --adapter presto Running with dbt=0.20.0 Creating dbt configuration folder at /Users/satoshi.hirose/.dbt With sample profiles.yml for presto Your new dbt project "dbt-td-sample" was created! If this is your first time using dbt, you'll need to set up your profiles.yml file (we've created a sample file for you to connect to presto) -- this file will tell dbt how to connect to your database. You can find this file by running: open /Users/satoshi.hirose/.dbt For more information on how to configure the profiles.yml file, please consult the dbt documentation here: https://docs.getdbt.com/docs/configure-your-profile One more thing: Need help? Don't hesitate to reach out to us via GitHub issues or on Slack -- There's a link to our Slack group in the GitHub Readme. Happy modeling!
接続情報の追加
Treasure Data への接続方法を確認しながら ~/.dbt/profiles.yml を修正する。
JDBC Driver for Presto - Product Documentation - Treasure Data Product Documentation
td:
target: dev
outputs:
dev:
type: presto
method: none # optional, one of {none | ldap | kerberos}
user: <your api key>
password: dummy
database: td-presto
host: api-presto.treasuredata.com
port: 443
schema: satoshihirose
threads: 1
dbt debug の実行
dbt debug を試してみるとエラーが発生する。
$ cd dbt-td-sample $ dbt debug --profile td Running with dbt=0.20.0 dbt version: 0.20.0 python version: 3.9.6 python path: /Users/satoshi.hirose/work/dbt-td-sample/venv/bin/python3.9 os info: macOS-11.2.3-x86_64-i386-64bit Using profiles.yml file at /Users/satoshi.hirose/.dbt/profiles.yml Using dbt_project.yml file at /Users/satoshi.hirose/work/dbt-td-sample/dbt-td-sample/dbt_project.yml Configuration: profiles.yml file [OK found and valid] dbt_project.yml file [OK found and valid] Required dependencies: - git [OK found] Connection: host: api-presto.treasuredata.com port: 443 user: 7060/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx database: td-presto schema: satoshihirose Connection test: ERROR dbt was unable to connect to the specified database. The database returned the following error: >Runtime Error error 400: b'<html>\r\n<head><title>400 The plain HTTP request was sent to HTTPS port</title></head>\r\n<body>\r\n<center><h1>400 Bad Request</h1></center>\r\n<center>The plain HTTP request was sent to HTTPS port</center>\r\n</body>\r\n</html>\r\n' Check your database credentials and try again. For more information, visit: https://docs.getdbt.com/docs/configure-your-profile
どうやら https で接続していないことが問題のようだ。
確認をすると dbt-presto は auth が none の時は http 接続をするようハードコードされており、設定などでは対応できないようだ。プラグインのコードを https に書き換えて先に進む。
接続することは確認できた。
(venv) [/Users/satoshi.hirose/work/dbt-td-sample/dbt-td-sample]dbt debug --profile td Running with dbt=0.20.0 dbt version: 0.20.0 python version: 3.9.6 python path: /Users/satoshi.hirose/work/dbt-td-sample/venv/bin/python3.9 os info: macOS-11.2.3-x86_64-i386-64bit Using profiles.yml file at /Users/satoshi.hirose/.dbt/profiles.yml Using dbt_project.yml file at /Users/satoshi.hirose/work/dbt-td-sample/dbt-td-sample/dbt_project.yml Configuration: profiles.yml file [OK found and valid] dbt_project.yml file [OK found and valid] Required dependencies: - git [OK found] Connection: host: api-presto.treasuredata.com port: 443 user: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx database: td-presto schema: satoshihirose Connection test: OK connection ok
dbt run の実行
次は dbt run を実行してみるとエラーが発生する。トランザクション周りで問題が発生している。
(venv) [/Users/satoshi.hirose/work/dbt-td-sample/dbt-td-sample]dbt run --profile td
Running with dbt=0.20.0
Found 2 models, 4 tests, 0 snapshots, 0 analyses, 145 macros, 0 operations, 0 seed files, 0 sources, 0 exposures
Encountered an error:
Runtime Error
Runtime Error
PrestoUserError(type=USER_ERROR, name=NOT_SUPPORTED, message="Nested transactions not supported", query_id=20210727_130455_32322_s2qyv)
デバッグログを確認してみると、information schema は取得できているっぽいが、start transaction が失敗しているっぽい。TD のコンソールでクエリの実行状況を見ても同様の事象が確認できる。
$ dbt --debug run --profile td
...
2021-07-27 13:05:20.472157 (MainThread): Acquiring new presto connection "model.my_new_project.my_first_dbt_model".
2021-07-27 13:05:20.480174 (MainThread): Acquiring new presto connection "model.my_new_project.my_second_dbt_model".
2021-07-27 13:05:20.539955 (MainThread): Sending event: {'category': 'dbt', 'action': 'load_project', 'label': '728c6762-9aca-4330-bc3b-3840456a8980', 'context': [<snowplow_tracker.self_describing_json.SelfDescribingJson object at 0x10ceeac40>]}
2021-07-27 13:05:20.543735 (MainThread): Sending event: {'category': 'dbt', 'action': 'resource_counts', 'label': '728c6762-9aca-4330-bc3b-3840456a8980', 'context': [<snowplow_tracker.self_describing_json.SelfDescribingJson object at 0x10ceead00>]}
2021-07-27 13:05:20.543977 (MainThread): Found 2 models, 4 tests, 0 snapshots, 0 analyses, 145 macros, 0 operations, 0 seed files, 0 sources, 0 exposures
2021-07-27 13:05:20.544701 (MainThread):
2021-07-27 13:05:20.544973 (MainThread): Acquiring new presto connection "master".
2021-07-27 13:05:20.545602 (ThreadPoolExecutor-0_0): Acquiring new presto connection "list_td-presto".
2021-07-27 13:05:20.555404 (ThreadPoolExecutor-0_0): Using presto connection "list_td-presto".
2021-07-27 13:05:20.555564 (ThreadPoolExecutor-0_0): On list_td-presto: select distinct schema_name
from "td-presto".INFORMATION_SCHEMA.schemata
2021-07-27 13:05:20.555703 (ThreadPoolExecutor-0_0): Opening a new connection, currently in state init
2021-07-27 13:05:27.149112 (ThreadPoolExecutor-0_0): SQL status: OK in 6.59 seconds
2021-07-27 13:05:27.153038 (ThreadPoolExecutor-0_0): On list_td-presto: Close
2021-07-27 13:05:27.154223 (ThreadPoolExecutor-1_0): Acquiring new presto connection "list_td-presto_satoshihirose".
2021-07-27 13:05:27.159687 (ThreadPoolExecutor-1_0): Opening a new connection, currently in state closed
2021-07-27 13:05:28.579790 (ThreadPoolExecutor-1_0): Error while running:
handle.start_transaction()
2021-07-27 13:05:28.580094 (ThreadPoolExecutor-1_0): PrestoUserError(type=USER_ERROR, name=NOT_SUPPORTED, message="Nested transactions not supported", query_id=20210727_130528_32356_s2qyv)
2021-07-27 13:05:28.580380 (ThreadPoolExecutor-1_0): Error while running:
macro list_relations_without_caching
2021-07-27 13:05:28.580660 (ThreadPoolExecutor-1_0): Runtime Error
PrestoUserError(type=USER_ERROR, name=NOT_SUPPORTED, message="Nested transactions not supported", query_id=20210727_130528_32356_s2qyv)
2021-07-27 13:05:28.581073 (ThreadPoolExecutor-1_0): On list_td-presto_satoshihirose: Close
...
どうやら TD が start transaction をサポートしていないのが原因のようだ。
プラグインの start transaction を発行している箇所をコメントアウトして実行してみる。
dbt-presto/connections.py at cc834028f8120784829cc66733007dbabcec1a30 · dbt-labs/dbt-presto · GitHub
先に進んだ。次は、View が作れないことが原因のエラーのようだ。
$ dbt run --profile td Running with dbt=0.20.0 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 145 macros, 0 operations, 0 seed files, 0 sources, 0 exposures 22:14:14 | Concurrency: 1 threads (target='dev') 22:14:14 | 22:14:14 | 1 of 2 START table model satoshihirose.my_first_dbt_model............ [RUN] 22:14:22 | 1 of 2 OK created table model satoshihirose.my_first_dbt_model....... [OK in 8.54s] 22:14:22 | 2 of 2 START view model satoshihirose.my_second_dbt_model............ [RUN] 22:14:24 | 2 of 2 ERROR creating view model satoshihirose.my_second_dbt_model... [ERROR in 1.47s] 22:14:24 | 22:14:24 | Finished running 1 table model, 1 view model in 16.26s. Completed with 1 error and 0 warnings: Runtime Error in model my_second_dbt_model (models/example/my_second_dbt_model.sql) PrestoUserError(type=USER_ERROR, name=NOT_SUPPORTED, message="This connector does not support creating views", query_id=20210727_131423_32607_s2qyv) Done. PASS=1 WARN=0 ERROR=1 SKIP=0 TOTAL=2
TD は View をサポートしていないため、View ではなくテーブルを作成するように設定を変更する。
dbt_project.yml の materialized の箇所を view から table に書き換える。
models:
my_new_project:
# Applies to all files under models/example/
example:
materialized: table
dbt run の実行に成功した。
dbt run --profile td Running with dbt=0.20.0 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 145 macros, 0 operations, 0 seed files, 0 sources, 0 exposures 22:17:24 | Concurrency: 1 threads (target='dev') 22:17:24 | 22:17:24 | 1 of 2 START table model satoshihirose.my_first_dbt_model............ [RUN] 22:17:33 | 1 of 2 OK created table model satoshihirose.my_first_dbt_model....... [OK in 8.63s] 22:17:33 | 2 of 2 START table model satoshihirose.my_second_dbt_model........... [RUN] 22:17:40 | 2 of 2 OK created table model satoshihirose.my_second_dbt_model...... [OK in 7.42s] 22:17:40 | 22:17:40 | Finished running 2 table models in 27.49s. Completed successfully Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
コンソールを確認すると、サンプルのテーブルが作成されていることがわかる。
二つのテーブルが作成された。
 テーブルに追加されたデータ。
テーブルに追加されたデータ。
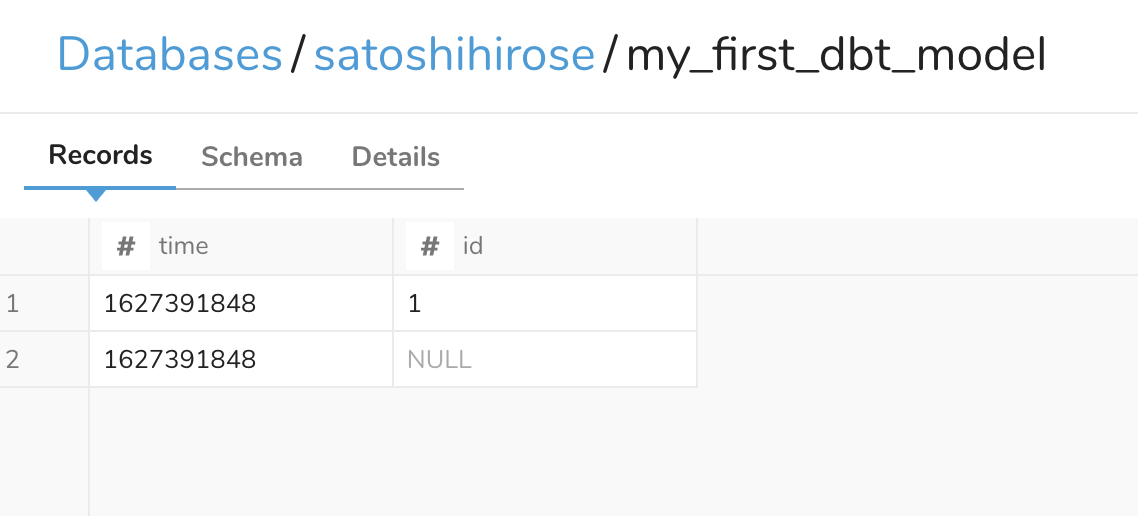
結果としては dbt-presto の修正が必要そうで現状のままでは動作しないことが確認できた。
修正が必要な箇所は
- http 接続がハードコードされている箇所
- start transaction が実行される箇所
1 は新しいモードを追加することで簡単に修正できそうである。2 については、設定などで start transaction の実行を回避できないか調査していたが、dbt 本体にも実行を指定している箇所があるなど簡単な修正では対応できないように感じた。果たして dbt-presto に Treasure Data に合うようなモードを追加するのが良いか、 dbt-athena のように別なプラグインとして提供するのが良いか。
リバースETLはデータパイプラインの何を変えるのか
はじめに
リバース ETL という概念が提起されて、そのための SaaS も生まれており、面白いと思うので所感をまとめる。
Reverse ETL ?
自分が最初に Reverse ETL という言葉に触れたのは、Redpoint Ventures の Astasia Myers が 2021-02-23 に書いたこの記事だった。
彼女はどんなものをリバース ETL と呼んでいるかというと
Now teams are adopting yet another new approach, called “reverse ETL,” the process of moving data from a data warehouse into third party systems to make data operational.
とまあ難しいことはなく、データウェアハウスからサードパーティシステムにデータを移動させるプロセスのことをそう呼んでいる。 記事を参照すると、すでに Hightouch, Census, Grouparoo(open source), Polytomic, Seekwell などのリバース ETL 用のサービスが生まれているうようだ。
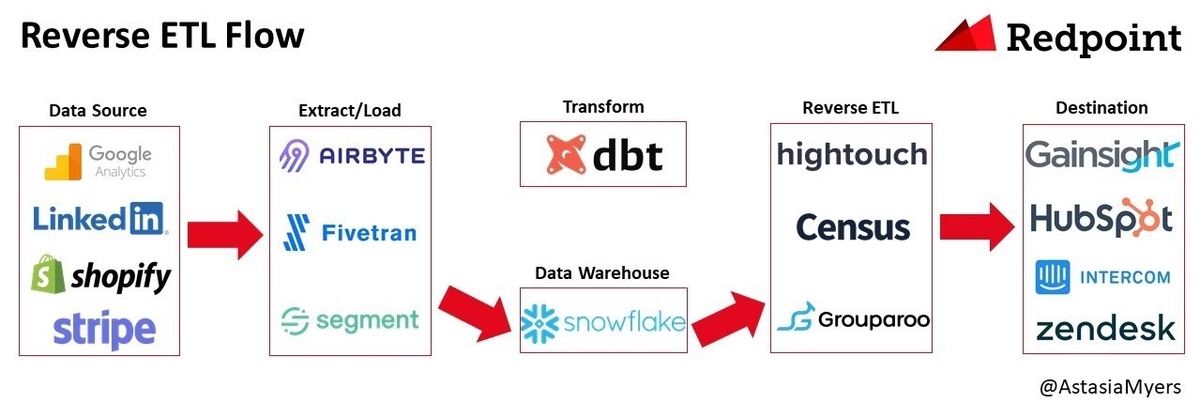
リバース ETL が提起された背景には、各事業者においてデータウェアハウスやさまざまな SaaS 活用が進んだため、データウェアハウスのデータを SaaS に活用するためのデータパイプラインが複雑化、多様化したという状況があるだろう。そのため、そのようなパイプラインを用意しようとすると、データエンジニアがさまざまな SaaS の API を調べて個別に実装する必要があり、コストが大きかった。
その integration は Embulk や Airlfow などではプラグイン化され、取り回しはそれまでよりしやすくなったが、Reverse ETL を謳うサービスを使うことで状況はより良くなるかもしれない。
拡張された ETL パイプライン
Census のブログ記事中の、データ活用サイクルを表現した図が面白い。
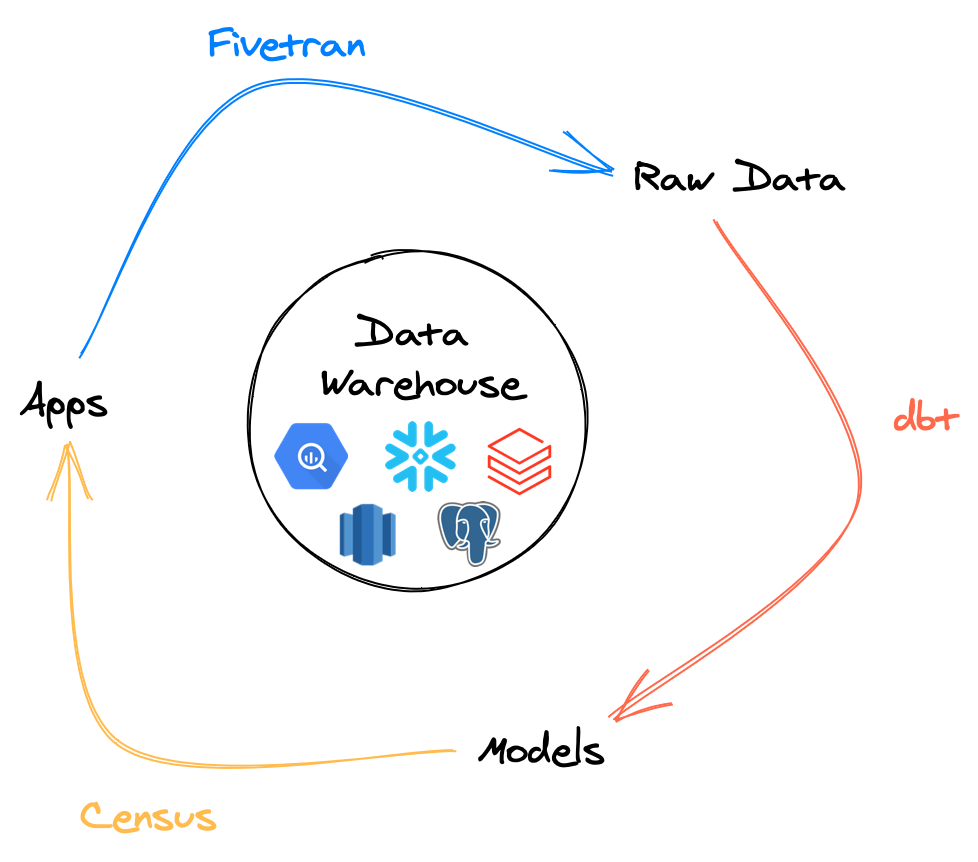
それぞれの矢印が
- Forward ETL: Fivetran による、App(データソース)からデータウェアハウスまでデータを ETL するプロセス。(Forward ETLは今自分が考えた用語)
- Transform: dbt による、データ変換プロセス
- Reverse ETL: Consus による、データウェアハウスから App(データ活用アプリケーション)までデータを ETL するプロセス。
を表現している。
従来の ETL では、データ活用の手続きにおいて、データソースからデータウェアハウス上の最終成果物までの移行過程が ETL として表現されていた。 上記の図では、それがデータソース(App)から SaaS 上の最終成果物(App)までのひと続きの ETL として表現されている。この表現はシンプルでわかりやすく、良く抽象化されている気がする。これまでの、データウェアハウスまでで完結していた ETL は、上記のサイクルにおける特殊形にすぎない。
ETL パイプラインの発展過程
上述の ETL パイプラインのサイクルに関して、その進化の過程を実装者の観点から考えてみると、このような感じだろうか。
- 第一段階(全て自前実装)
- Forward ETL: エンジニアが実装する
- Transform: エンジニアが実装する
- Reverse ETL: エンジニアが実装する
- 第二段階(in/outのプラグイン化やアプリ側の対応が進む)
- 第三段階(in/outのサービス化)
- Forward ETL: サービスを利用し、データ利用者が設定する
- Transform: エンジニアが実装する
- Reverse ETL: サービスを利用し、データ利用者が設定する
すんなりとこんなに綺麗には分かれないとは思うが、この最後の段階の何が嬉しいかというと、それぞれの責任分界点とインターフェイスがはっきりすることだと思う。
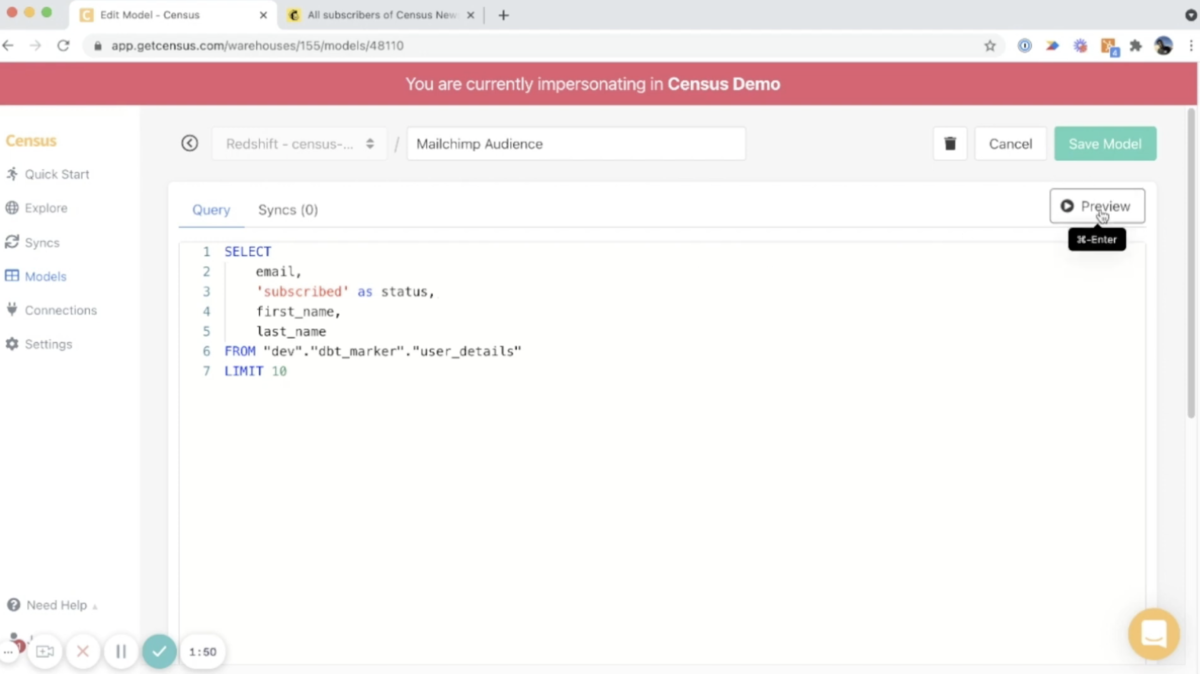
たとえばリバース ETL サービスのひとつである Census は、この写真のように、接続したデータウェアハウスのテーブルを使って Model を定義することで、それを元にリバース ETLの設定(データウェアハウスからアプリへの ETL の設定)を行うことができる。
つまり、データエンジニアは、データウェアハウス内にテーブルを用意するだけで済むようになる。あとはデータ利用者が良しなに活用してくれる。必死に各社 SaaS の API 使用を調べて実装する必要はない。Forward ETL の設定は、データ利用者が設定する動機がなさそうなので、データエンジニアがオーナーになるかもしれない。しかし、理想的にはデータエンジニアはデータウェアハウスへのインプットおよびアウトプット処理を実装せずに済むようになり、データウェアハウスの中だけで完結する世界に生きられるというわけだ(そしてそれは dbt を使うだけで十分ということだ)。
さいごに
リバースETLの概念とデータパイプラインにおけるリバース ETL の意義を紹介した。個人的には、このようなサービスが成立することが驚き(現職の Treasure Data はデータプラットフォームの一部としてそれら input/output どちらの integration も提供している)であり、嬉しくもある(データエンジニアリングの仕組みや知見にニーズがあることだと思うので)。
また、Forward ETL と Reverse ETL はひとつのサービスとして統合できないのだろうかという疑問がある(メンテコストが大きすぎるのだろうか)。
なんにせよ食いっぱぐれないようにやっていきましょう。
Data Lineage したい
条件
- 現職で管理している現行のデータパイプラインである Treasure Workflow(managed digdag on TD)+ Presto に適用できること
- ウェブでメタデータのドキュメントが公開でき、社内に共有できること
- Data Lineage 的なデータの依存関係がわかること
dbt
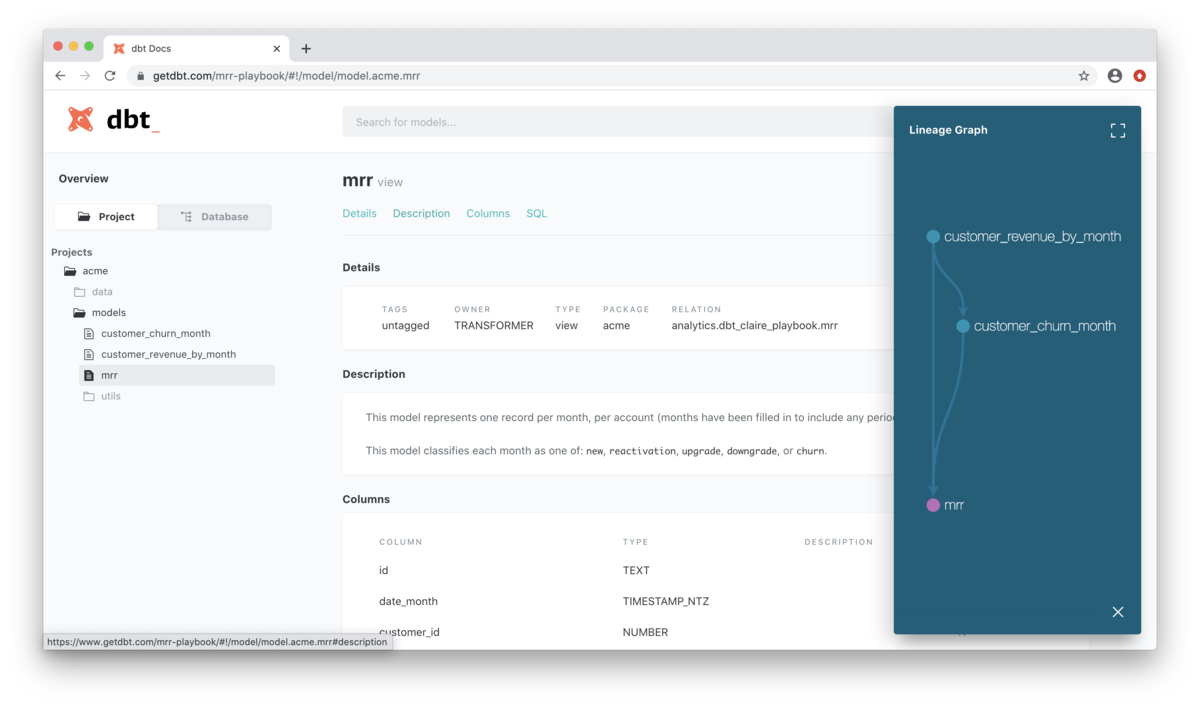
dbt は構築したプロジェクトとその内部のクエリを元にドキュメントを自動で生成してくれる。データの依存関係のDAGを可視化してくれるようで、良さそう。dbt docs serve というドキュメントサイトをホストする機能も提供しているが、現時点では本番稼働を想定していないものらしい。その代わりに dbt Cloud を使う、生成したドキュメントを S3 でホストするなどの方法を推奨している。
The dbt docs serve command is only intended for local/development hosting of the documentation site. Please use one of the methods listed below (or similar) to ensure that your documentation site is hosted securely!
しかし、dbt はデータを transform( ETL の T )することを主眼にしており、そのプロジェクト内部で管理するパラメータを埋め込んだクエリからリソースを materialize することを想定している。現行のデータパイプラインではクエリの実行に digdag の td opeartor (td>:) を使用しており、もし dbt を使うならその部分を置き換える必要がある。sh>: は提供していないため dbt CLI は使えず、Python API はまだ使用を推奨していないため現行のパイプラインとの共存は難しそうである。
Presto の adopter は partial support らしい。
Due to the nature of Presto, not all core dbt functionality is supported. The following features of dbt are not implemented on Presto: 1. Snapshots 2. Incremental models
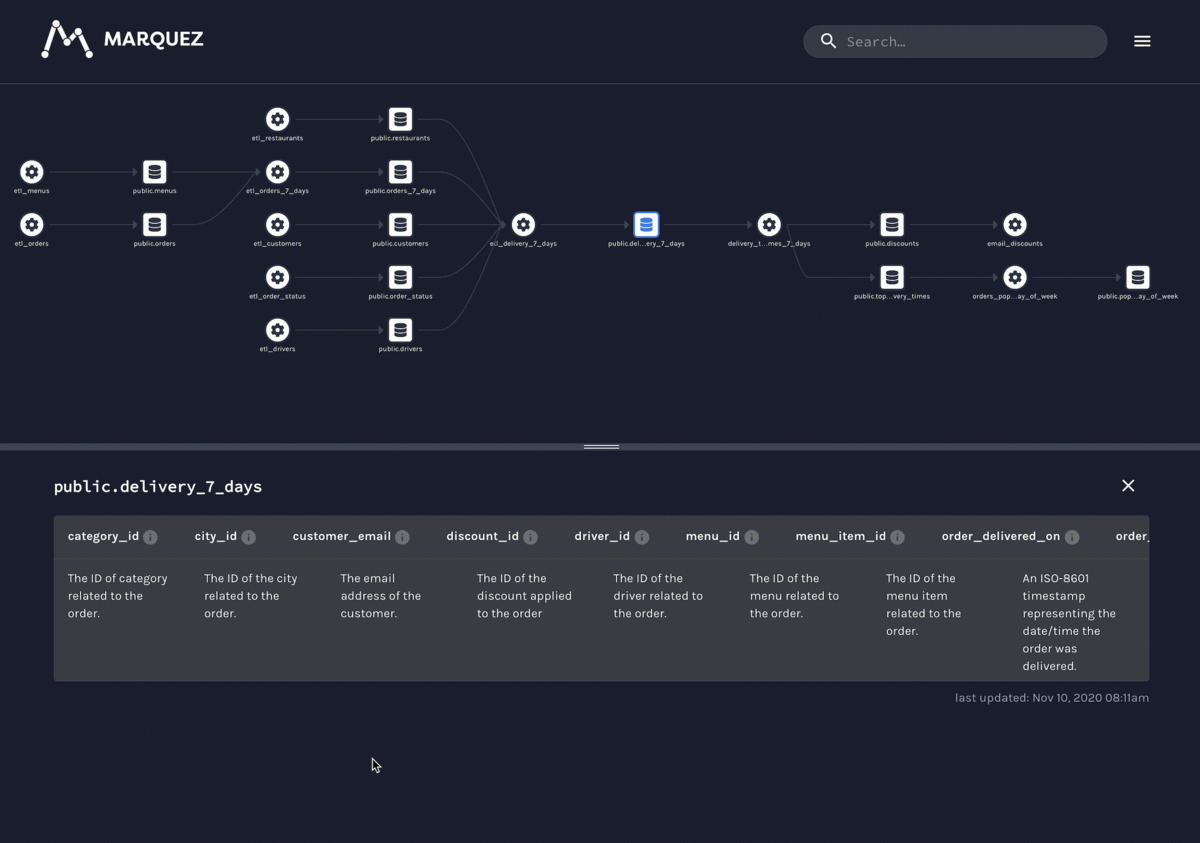
Marquez
パイプラインとメタデータ管理が結合している dbt が使えなかったので疎結合っぽいアーキテクチャのが良いのかなと思い、思い出したのが WeWork の Marquez。こちらは、REST API を提供しており、Namespace、Source、Dataset、Job、Run などのリソースを登録すると可視化してくれる。これなら現行のパイプラインに適宜 REST API を叩く処理を追加するだけで実現できる。とてもシンプルな作りのアプリケーションで、ぱっと見 UI はこなれていなさそう。OpenLineage API の reference implementation らしい。
DataHub
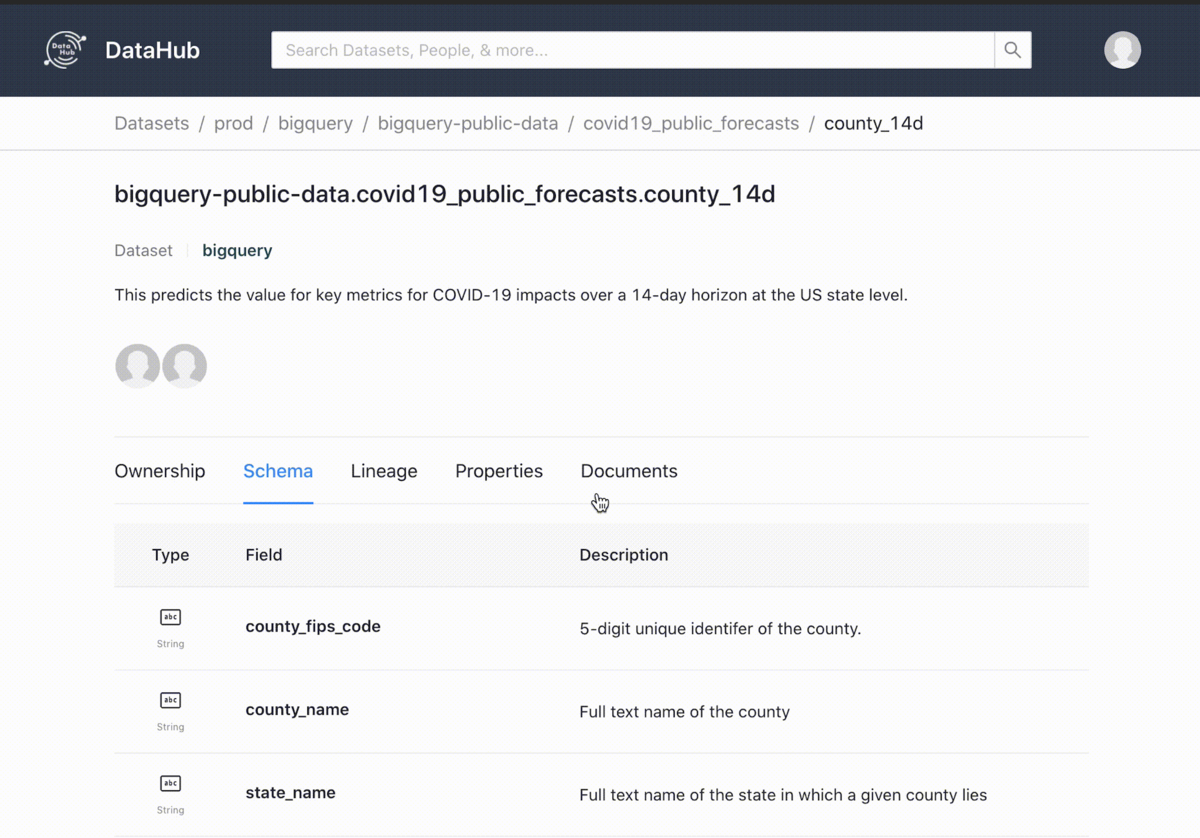 LinkedIn が開発した DataHub も push 型。HTTP と Kafka を通じてメタデータを格納できる。アーキテクチャが重厚でちょっと気軽に管理できる感じじゃないかな。Acryl っていう Managed な SaaS サービスも提供予定っぽい。
LinkedIn が開発した DataHub も push 型。HTTP と Kafka を通じてメタデータを格納できる。アーキテクチャが重厚でちょっと気軽に管理できる感じじゃないかな。Acryl っていう Managed な SaaS サービスも提供予定っぽい。
Amundsen
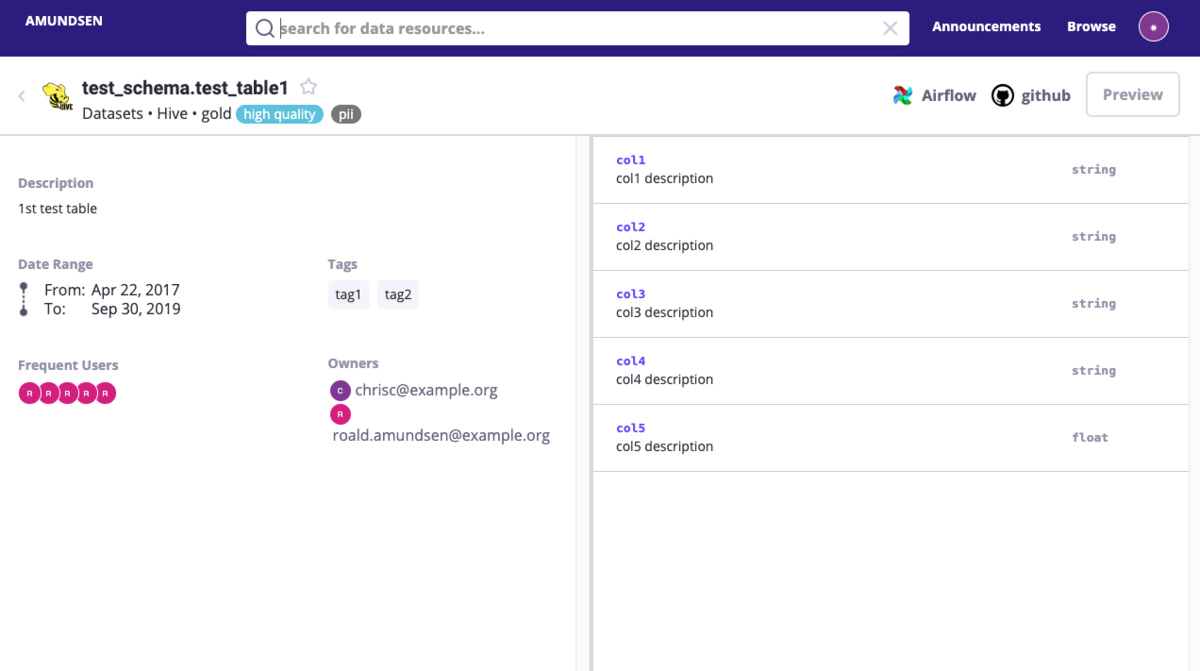
Lyft が開発した Amundsen はメタデータ管理 OSS の中でも割と活発に開発されている印象があるが、Data Lineage はスコープ外っぽい。
Tokern
Tokern って OSS はクエリをパースして column level の可視化をしてくれるらしい。機能はかなりシンプル。
SQLdep
SQLdep ってサービス?がクエリをアップロードすると良い感じに可視化してくれていたっぽいけれど、今はもう閉じちゃったのかな。
AlphaSQL
そういえば、AlphaSQL ってクエリ参照して依存関係可視化、Airflow DAG自動生成みたいなことやってるプロジェクトもあったなと思い出した。
感想
とまあ、ここまで適当にツール群を調べてみたが、結局自分がしたかったのはデータ依存関係とデータの説明をドキュメント化するのを良い感じに自動化したいってことだと気づいた。その場合、クエリをパースし、テーブルスキーマを参照して依存関係を含む何らかの設定ファイルを生成、そこにデータの説明を手動更新して、(dbt みたいに)静的 HTML を生成するようなツールがあれば良いのかな。