Xでお気に入りした論文や記事を自動で要約してメールを送る
背景
基本的に情報はSNSから取得していて、特にXを利用している。最近はAI関連の論文に触れる機会を増やしていて、気になるタイトルの論文や記事は一旦はお気に入りはしているが、数も多くあらためてそれを開き直すことがなかなか億劫になってしまっている状況だった。勝手にお気に入りしたポストのリンク先の論文や記事を要約して取り掛かりやすくするような仕組みが欲しいなと思ったので作った話をまとめる。
仕組み
データ取得
まず、Xでお気に入りした情報をAPIを使って取得しようとすると毎月のサブスクリプションが必要で $200 などかかる。
IFTTTなら月額 $2.99 でイベントドリブンな連携ができたので、それを使うことにした。
ポストをお気に入りしたイベントをトリガーにできる。
LLMの処理
取得したXのポストの情報をLLMに渡して要約させたい。ChatGPTやGeminiで試してみたが、XのURLからそのポストの内容を読み取ることはXが制限しているからかできないようだった。 ポストのテキスト情報をそのまま渡す、もしくは画面のスクリーンショットを撮って渡す、といった方法も考えたが下記のような状況も考慮したいので断念した。
- お気に入りしたポストに論文や記事のURLが含まれておらずスクリーンショットのみが含まれており、URLはそのポストへのリプライに含まれている
- お気に入りしたポストだけでなく、そのスレッドに複数連投された投稿全てを渡したい
- お気に入りしたポストだけでなく、その引用元のRTも参照させたい
Xが開発しているGrokならば上記の状況も対応できるか試したところ、ポストのURLを渡すだけで、その引用・リプライポストも勝手に情報として取得してくれていそうなので、Grokを使うことにした。
IFTTTにはカスタムコードを実行できる仕組みがなさそうなので、何かを用意する必要がある。 お金もかからないし、Google Sheetにお気に入りしたポストのデータを溜めてApps ScriptでGrokを呼び出してメールすることにした。
Apps Script
コードはLLMに適当に要件を伝えて書いてもらった。
スクリプト実行のトリガーは時間主導で5分ごとに実行する。シートの編集をトリガーにするような設定もあったが、調べたところIFTTTによる更新ではトリガーできないみたいなので断念して定期実行にした。
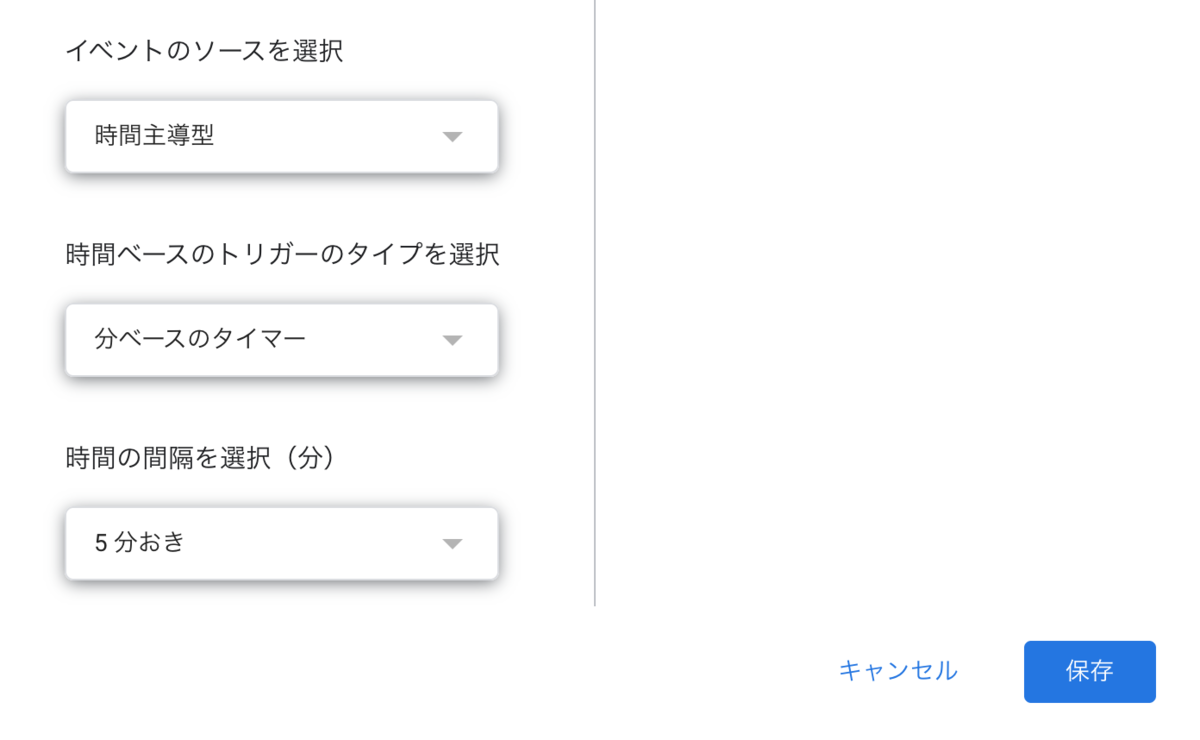
最後に処理した行を状態としてスクリプトプロパティに持たせて、定期実行で追加された行だけ処理させるようにする。
const props = PropertiesService.getScriptProperties();
const lastProcessedStr = props.getProperty(PROP_KEY_LAST_ROW);
プロンプトは適当に設定した。
const systemPrompt =
'あなたは有能なAI・LLMのResearcher・Engineerです。' +
'与えられたURLのリンク先の内容や、その周辺情報をWeb検索ツールを用いて理解し、' +
'「何が興味深い情報か」を日本語でわかりやすく要約してください。';
const userPrompt =
'次のURLはX(旧Twitter)のポストのURLです。内容を確認し、そこに含まれるリンク先の情報や周辺情報をWeb検索ツールで調べるなどして、情報を日本語でまとめてください。' +
'原文が英語だったら翻訳したものを出力に含めてください。情報全体をまとめたタイトルを出力の最初にしてくだい。一連のthreadに含まれるポストの場合は、そのURLのポストを特に取り上げてください。一連のthreadに含まれる外部URLは関連情報として出力に含めてください。YouTubeなど動画コンテンツの場合は、文字起こし情報がないか、動画をまとめた記事がないかを検索し、なければその周辺情報をまとめるだけで良いです。\n' +
'出力はURLリンクの記述方法を含めてHTML形式でお願いします。画像はHTMLで表示できるように埋め込んでください。\n' +
'URL: ' + url + '\n';
toolは、ウェブ検索とX検索を有効にして、reasoning_effortを高く設定。
const payload = {
model: XAI_MODEL_NAME,
input: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userPrompt }
],
tools: [
{ type: 'web_search' },
{ type: 'x_search' }
],
reasoning_effort: 'high'
};
Apps Script普段使わないから知らなかったけど、メール送信が簡単に実行できるのが嬉しい。
MailApp.sendEmail({
to: MY_EMAIL,
subject: subject,
body: body,
htmlBody: body
});
どんなメールになるか
結果、Xのポストをお気に入りしたら5分程度で下記のようなメールが送られてくるようになった。

元のポストはこちら
Beyond Memorization
— DailyPapers (@HuggingPapers) 2025年12月25日
Exposes popularity bias in VLMs: 34% higher accuracy on famous vs ordinary buildings, showing memorization trumps understanding. YearGuessr benchmark with 55K building images from 157 countries reveals critical reasoning flaws. pic.twitter.com/sS4FSSFWeL
最後に
これで、論文や気になった記事を読む心理的ハードルが下がって、過去に気になった記事をメールボックスで検索できるようになり、便利になった。このGrokの呼び出しセットアップだと、一回のAPI実行に10円くらいかかり、ちょっと高く感じるので、コスト削減が次の課題か。上記の方法より良いやり方があれば教えてください。
最後に気になる論文を見つけるのに参考になるXアカウントを紹介して終わりにします。
Text-to-SQLのコモディティ化とデータ活用の民主化
はじめに
ikki-sanのデータ活用の民主化へのコメントをそうだなと思いながら読んで、最近自分もそんな感じの領域のことをベンダー所属のプロダクトマネージャーとしてやっているので、考えていることをまとめてみる。
この数年間で「データの民主化」はイマイチ進まなかった印象ですが、その原因は「SQLの習得難易度」によるところが大きい。そこに関しては生成AIで相当解決されるはずなので、今後はデータの民主化がスタンダードになると予想しています。
— ikki / stable代表 (@ikki_mz) 2025年4月7日
データ活用と生成AI
これまで社内に蓄積された構造化されたデータを取得・操作するにはSQLおよびデータベースの理解が必要であり、その理解がない人たちは誰かにデータの取得を依頼するか、ダッシュボードやスプレッドシートなど誰かが作ったUIを介してデータを利用するしかなかった。そのような状況は、データを活用するまでオーバーヘッドが大きかったり、定型化されたデータ活用のレールから外れることができないなど、制限が多かった。
そこで、セルフサーブBIやセマンティックレイヤーの概念が登場したり、各社データカタログやOBTを導入したり、色々な工夫が行われてきた。少しずつ状況は変わってきているが、生成AIの普及がその現状を大きく変えることは間違いない。
具体的には、対話型UIにより自然言語でAIに要件を伝えるとそれに見合ったデータ(もしくはさらに求めるグラフやインサイトまでも)がSQLを書かずとも得られるようになってきている。そのような機能は、さまざまなサービスで実装され、利用されはじめている。 例えば、DWHレイヤーだとSnowflakeのCortex AgentsやDatabricksのGenieなど、BIレイヤーだとTableauのTableau Agent、ThoughtspotのSpotter、データカタログレイヤーだとInformaticaのCLAIREやAlationのALLIE AIなどだ。 そして昨年末のMCPの登場により、MCPサーバーを用意することでさまざまなデータベースをLLMから操作できるようにもなってきている。
構造化されたデータと生成AI
ここで、SnowflakeのCortex Agentsの仕組みを見てみると、内部はCortex AnalystとCortex Searchに分かれる。それぞれが、構造化データ(テーブル)の操作と非構造化データ(ドキュメント)の操作を担当している。
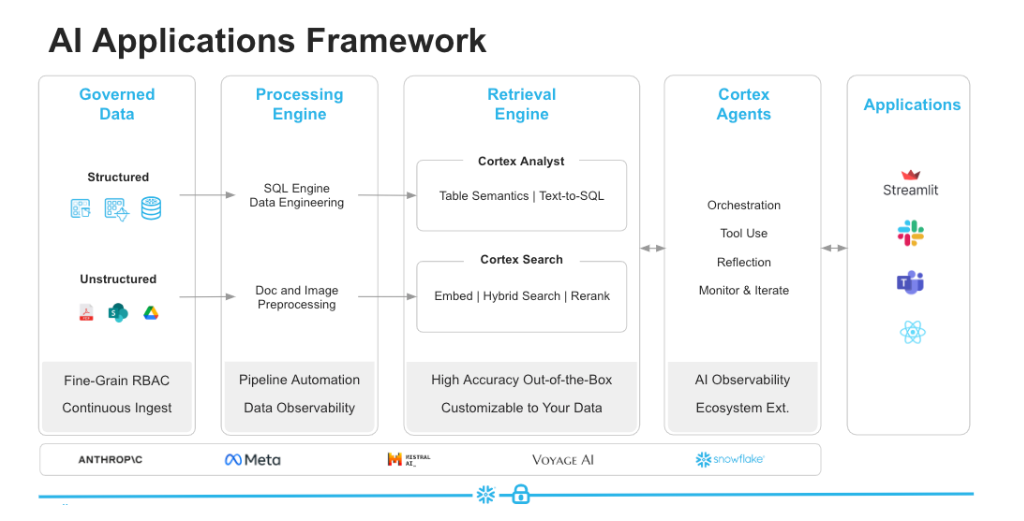
Cortex Analystの動作には事前にセマンティックモデルと呼ばれるものを定義する必要がある。 このセマンティックモデルというものは、実態はテーブルに紐づくさまざまなメタデータを集めたYAMLファイルだ。 これをAIが参照することでデータのセマンティックス(意味)を理解し、利用できるようになる。具体的には以下のように様々なメタデータをYAMLで定義・管理ができる。
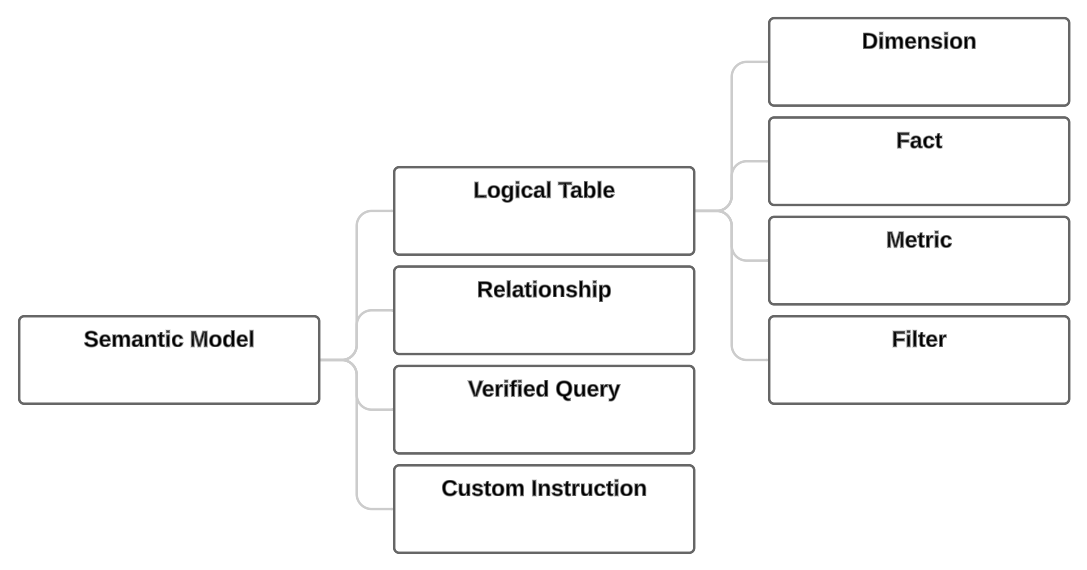
Cortex Analyst semantic model specification | Snowflake Documentation
SnowflakeのCortex Analystの例を挙げたが、他のシステムでも似たような仕組みになっていることが多い。 システムがデータを使いやすいように構造化されたが故にコンテキストが削ぎ落とされ、生成AIからはそのままでは利用しにくくなっているというのはパラダイムシフトっぽい状況で面白い話だなと思う。
AIのアウトプットを正確にするためにはそのようなメタデータやセマンティクスの管理が重要なことは間違いない。 そして、セマンティックといえばセマンティックレイヤーの話題になるが、セマンティックレイヤーを導入すればそのままLLMがその意味を理解して喋れるようになり、それを契機にセマンティックレイヤーの普及が進むような未来があるのかもしれない。
また、MCPはと言えば、データベースを操作するようなサーバーの実装では、list と execute_query で頑張るような実装していることが多く、まだ良い感じにクエリを書いてもらうにはユーザーから目的のデータが含まれるテーブルを指定するなりが必要でデータベースの構造理解がないユーザーが利用しにくかったり、大量のテーブルが存在する状況では壁があるという印象だ(そんなことないよという場合はぜひ教えてください)。
事例
Uber社などすでにLLMで社内のデータを操作するような内製の仕組みの導入が成功している企業も存在し、その企業内部での工夫を公開しているので先人たちからどのような要素が重要なのかを学ぶことができる。 基本的にはText-to-SQLをどのように頑張るかという話である。
Uber
Uberでは内製のデータプラットフォーム上で自然言語でクエリを作成できるようになっており、クエリ作成の業務効率化を実現している。
1 日あたり平均約 300 人のアクティブ ユーザーが利用しており、そのうち約 78% が、生成されたクエリによって、ゼロからクエリを作成する場合よりも時間が短縮されたと回答しています。
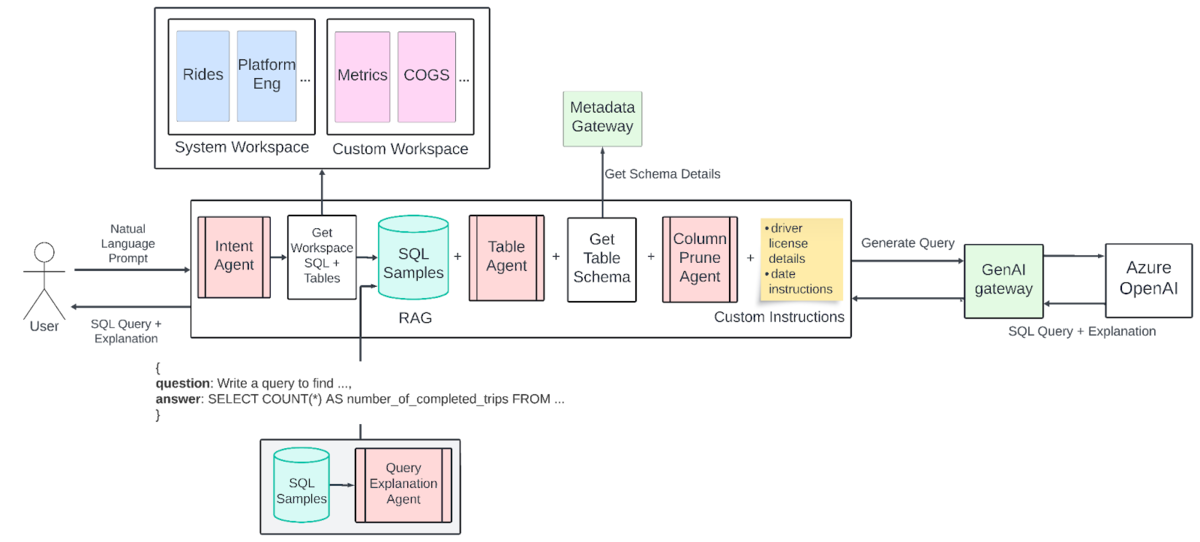
初期バージョンでは、自然言語での問い合わせに対して、社内に構築したRAGから
を取得し、社内の独自日付フォーマットについての処理などのカスタムインストラクションと合わせてプロンプトを作って、SQLを作成するという設計だったようだ。
しかし、ただユーザーの質問文をRAGに投げても適切なテーブル情報を取得するのが難しい、列数が200などのテーブルがありそのようなテーブルをプロンプトに含めるとトークン数の制限にかかる、など問題があった。
そこで、新しいバージョンのアーキテクチャでは、
- 広告やモビリティなどの問い合わせ内容についての分類を事前に作成し、RAGへの検索前に問い合わせ内容を分類することで、RAGの検索範囲を限定する
- AIがSQL生成に利用するテーブルが想定のものと合っているかユーザーに確認するプロセスを挟む
- LLMに与える列を間引くプロセスを追加する
ような工夫を行なっている。
その一連のフロー図は下記になっている。この記事からは、図に出てくるサンプルクエリやメタデータやドメイン知識の管理をどのように行なっているからはわからない。
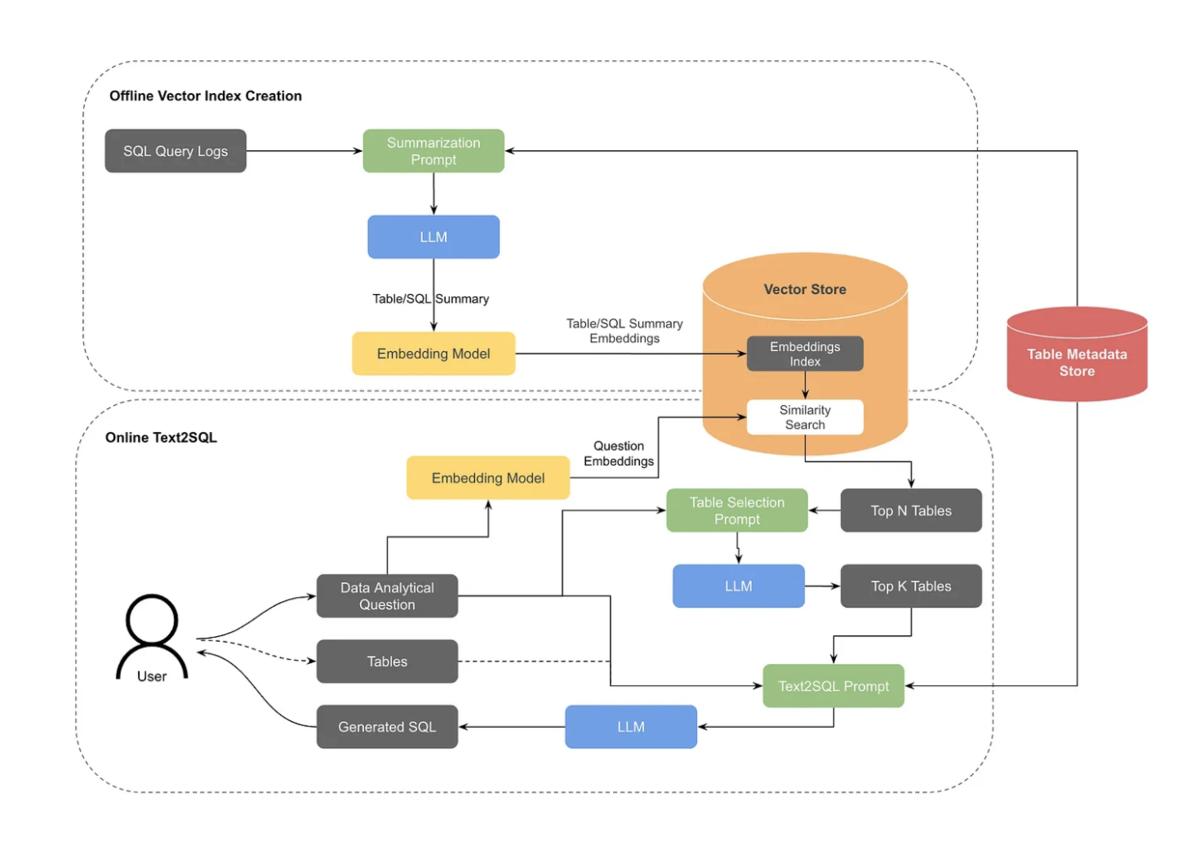
LinkedInもLangChainとLangGraphを使って、SQL BotというAIアシスタント機能を実現している。さまざまな部門で数百人の従業員が現在使用しているようだ。
記事では、工夫した点を5つの戦略として紹介している。具体的には下記の5つだ。
- 戦略1: 品質の高いテーブルメタデータとパーソナライズされた検索
- 戦略2: ランキング、執筆、自己修正のための知識グラフとLLM
- 戦略3: 豊富なチャット要素によるユーザーエクスペリエンス
- 戦略4: ユーザーカスタマイズのオプション
- 戦略5: 継続的なベンチマーク
説明されているフローはUberのそれよりはもうちょっと複雑になっている。
DataHubを使用して、テーブル スキーマ、フィールドの説明、カテゴリ ディメンション フィールドの上位 K 値、パーティション キー、およびメトリック、ディメンション、属性へのフィールドの分類を検索します。
SQL Bot の UI でユーザーからドメイン知識を収集します。
クエリ ログからの成功したクエリを使用して、テーブル/フィールドの人気度や共通テーブル結合などの集計情報を導き出します。
社内 Wiki と DARWIN のノートブックからサンプル クエリを組み込みます。DARWIN のコード品質はさまざまであるため、ユーザーによって認定されたノートブックと、最新性と信頼性に関する一連のヒューリスティックを満たすノートブックのみを組み込みます。たとえば、実行回数が多いユーザーがタイトルを付けた最近作成されたノートブックを優先します。
まず、LinkedInではDataHubというOSSのデータカタログツールとDARWINというデータ分析プラットフォームを内製して運用しており、質問に答えるための継続的なメタデータの管理と参照を行なっている。
膨大な量のテーブル (LinkedIn では数百万に上ります) と、ユーザーの質問に埋め込まれた暗黙のコンテキストです。アクセスの人気度を調べることで、テーブルの量を数千にまですばやく絞り込むことができます。
テーブルが大量にあるという課題は、LinkedInでは人気度のようななんらかのスコアをもとに間引くような工夫をしているようだ。
当初のプロトタイプでは、すべての質問に SQL クエリで回答していましたが、ユーザーが実際に望んでいたのは、テーブルの検索、データセットに関する質問、参照クエリの確認、クエリ構文に関する一般的な質問でした。現在では、意図分類を使用して質問を分類し、回答方法を決定しています。
SQLの生成のほかに、テーブルの検索やデータセットに対する質問、クエリの確認や一般的な質問など多様なユースケースがあったことも示唆的だ。
そして、LinkedInでもUberと同様に利用するテーブルをユーザーに選ばせるインターフェイスを採用しているようだ。その際に、表示するテーブルについては、その説明、データセットが「認定済み」か「人気」かを示すタグ、月間平均アクセス頻度、よく結合されるテーブル、および詳細情報のための DataHub へのリンク などを表示しユーザーが判断しやすいようにしているようだ。また、スタンドアロンアプリにするより、ウィンドウ内でクエリを実行できるようにすることで利用率が5-10倍になったと言っていて、合わせてUIの重要性を伝えている。
たとえば、「昨日の平均 CTR はいくらでしたか?」という質問は、従業員がメール通知、広告、または検索品質のどれに興味があるかによって異なる回答をする必要があります。これに対処するために、組織図に基づいてユーザーの既定のデータセットを推測します。
また、かなり応用的に感じるが、質問をした従業員の組織情報に応じてLLMへのインプットを変えるような仕組みになっているようだ。
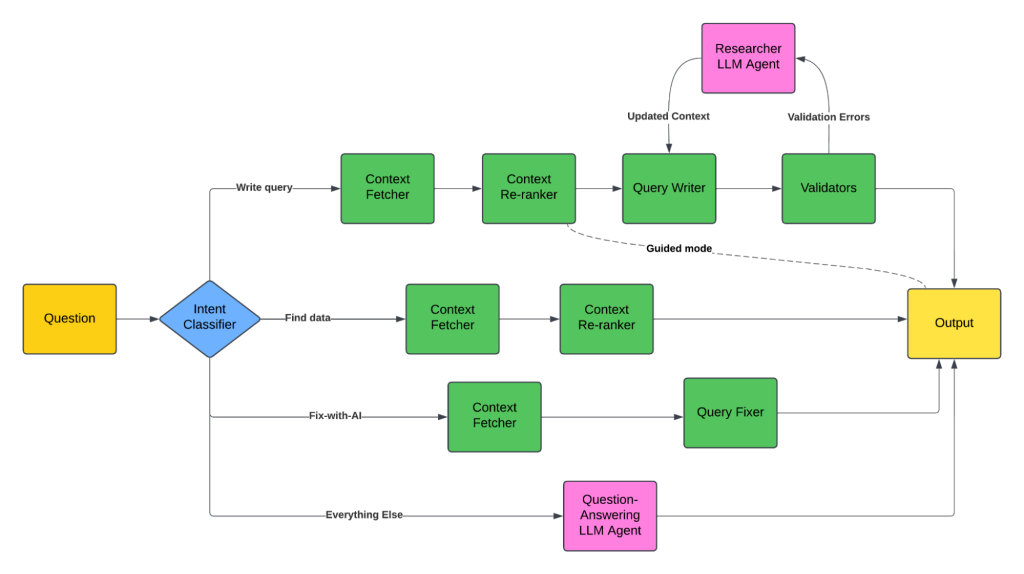
さいごの事例はPinterestだ。別な方が書いた解説記事もあるので合わせてご参照ください。 Pinterest社で運用されているText-to-SQLを理解する
Pinterestのフローはこちら
Pinterestでは下記のような工夫をしている。
- 正しいwhere句を生成するために、低カーディナリティな列についてはカテゴリ値をLLMに与える
- トークン節約のため
また、他社と同様にRAGを構築しているが、そこにあらかじめ
- テーブルの要約情報
- クエリの要約情報
を生成し追加することで検索の精度をあげているようだ。
さいごに
データ活用の民主化を実現するAI活用の事例を見てきた。今後周辺ツールの発展により積み重ねられた知見がコモディティ化し、業務にデータを使うまでのハードルは下がっていくだろう。もちろんその際に正しくデータマネジメントを行うことの重要性が増すことも間違いない。
ちょうどタイムリーにガートナーによる企業のAI活用とデータ管理に関する記事が出ていた。今後このようにAIが社内データを利用できるようにきちんと管理できる企業とそうでない企業の差は生まれていくだろう。引き続き、変わっていく環境にめげずについていきましょう。
AI-Readyデータを整備できた企業は大きな競争力を手に入れることができる。エモット氏によると、AIがビジネスの成果にもたらす影響ついて尋ねたガートナーの調査でも、データがAI向けに準備できている企業の「貢献している」との回答は、準備できていない企業とくらべ、「売上」「コスト」「リスク」「生産性」のいずれでも約20ポイント多いという。
生成AI時代のデータカタログについてという記事を書きました
来年はもっと生成AI関連に時間使っていきたい。
データエンジニアがプロダクトマネージャーになることについて考えること
こちら trocco® Advent Calendar 2023 のシリーズ2の11日目の記事です。 qiita.com
データエンジニアからプロダクトマネージャーへのキャリアパス?
自分がそうだったという、かなりポジショントークと希望的観測込みの考えではあるが、データエンジニアからプロダクトマネージャーは割と有りなキャリアパスなんじゃないかという気が最近している。
データエンジニアとして満足していたりその専門性をまだまだ突き詰めて行きたいと思っている人はこんなことを考える余地はないかもしれないが、誰かのキャリア検討の一助になれば、とそう思う理由について言語化してみる。ちなみに、ここではSaaSとかインターネットサービスを提供している企業におけるプロダクトマネージャーを想定している。
理由1: データリテラシーが高く技術に強い
データリテラシー、技術に強いことは、プロダクトマネジメントする上でもかなり活きる。プロダクトマネージャーとして、toCでもtoBでも社内のデータを活用して状況を分析したり、プロダクト開発上の仮説を立てるのは日常的なことだ。社内のデータの構造をすぐに把握してSQLを書いてデータを抽出したり、最悪自分でデータを取得する仕組みを作れることは大きな強みになる。
さらに、データリテラシーだけでなく一般的なWeb技術に通じているケースも多い。データを処理するシステムがそういう技術に依拠していたり、データの生成元がそのようなシステムになっていたり、ユーザーが操作するウェブのUIについて考えることも多いためだ(最近はどこもSaaSを使って自前でホスティングするみたいな経験は少なくなっているのかもしれないけれど)。
理由2: 社内のさまざまなステークホルダーとコミュニケーションを取り、プロジェクトマネジメントができる
また、泥臭いプロジェクトマネジメントができることも強みになる。データエンジニアは日々データ利用者のことを考えながら基盤構築のプロジェクトを進めていたり、データセットやデータツールのマイグレーションをしていたり、それらの計画を立てたり、そのためのコミュニケーションをさまざまステイクホルダーと行っていたりする。プロダクトマネージャーにおいてもさまざまな職種の人とコミュニケーションを取ることは必須で、そのプロセスは同様だ。
理由3: 社内のデータに詳しい(ドメイン知識がある)
最後に、社内のデータに詳しくなることを通じて、結果的に業界のドメイン知識に詳しくなるのもプロダクトマネージャーになることには有利に働く。 技術にしか興味ない人やあまりデータ活用レイヤーに業務領域が被らない人はその限りではないのかもしれないが、データエンジニアとしてデータの活用を支援する立場となるとやはりそのデータがどのようなものでどのように活用されるかについての知見は溜まってくるんじゃないかなと思う。
さいごに
データエンジニアの職務領域は各社様々なので、上記の理由に当てはまらないデータエンジニアはいるとは思う(Hadoopクラスターの運用を専門としている人など)。一番ハードルが高そうなのは理由3かな。プロダクトマネージャーになるためにあと必要なのは、ビジネスや組織に対する興味関心とユーザーを喜ばせようとする気持ちとかか。
自分がデータエンジニアからプロダクトマネージャーになったのは、データを使って事業とかプロダクトを良くしたいと思ったときに、自分がPMをやった方が効果的なんじゃないかと思ったからだ。特定のドメイン・プロダクトが好きで、同じような気持ちになったりする人は少なからずいるんじゃないかなーと思ったりするので、そういう人はちょっと検討してみてください。
[PR] troccoというプロダクトのPMを募集しているのでデータエンジニアやってる方でご興味ある方は、お気軽にご連絡ください。
特にエンジニアリングに必須ではない図書40冊 後編
はじめに
前回の続きで、リストアップしていた会社で働いていくなかで役に立ちそうな残りの20冊を紹介する。 satoshihirose.hateblo.jp
特にエンジニアリングに必須ではない図書20冊 仕事編
Snowflake、ServiceNowを率いてきたフランク・スルートマンのとても経営哲学本。プロ経営者としてIT業界の一線を走り続けてきた著者の哲学が経験を元に明快に説明されている。テック業界に居る人なら読んで損はない名著。 著名VC、マーク・アンドリーセン・ホロウィッツのベン・ホロウィッツが過去の経験を赤裸々に語っていてその体験の困難さ(ハードさ)に恐れ入るための本。経営者って大変だなという気持ちになる本。

これは昔に書評を書いていた。ベン・ホロウィッツの「HARD THINGS」を読んだ - satoshihirose.log
誰しも転職や異動などキャリアアップしていく際に責任範囲が変わったりして苦労することはあると思うが、そのようなタイミングでどういう心構えでどのような振る舞いをすると良いかが述べられていてとてもためになる。 SaaS製品を伸ばしていく際に必要なメトリックに関する知識や分析事例が整理されていて入門書として最適。 原題はCulture Map。グローバル企業に勤めていたりすると多様な背景を持つ人たちと一緒に働かなきゃいけなくて苦労することもある。読むと自分の認知の仕方が相対的に見られるようになる。 邦題は微妙だが、原題はRadical Candor(徹底的な率直さ)で、このCandorの大事さはBill Campbellの伝記などでも触れられていたりして頻出のキーワードだと思う。改めて自分のコミュニケーションの方法を見直したくなる本。 ストーリー仕立てでうまくいくチームとはどういうものか、そういうチーム作りのプロセスについて説明している本。現実は必ずしもうまくいくばかりではないと思うが、ストーリー仕立てだからこそ感情移入してしみじみ読めてしまう良い本。 マッキンゼーの採用の仕組みについて語っている本。リーダーシップというのは全員に求めて良いものであるというのは自分はAmazonに勤めている時に実感したものだが、本書でもそれが説明されているパートがありそこが良かった。 会社勤めしていると自分の要求を通したい場面は多々あると思う。日本人はネゴシエーションが下手だと言われていたりするが、そういう場面で知っていると使えるかもしれないようなテクニックや考え方が説明されていて勉強になった。 すでにSaaSやっている会社での共通言語になっていると思うのでこのプロセスを採用するかにかかわらず読んでいて損はない。とても効率的だなとは思う一方、やり切るには大変。 自分は営業というロールにはあまり関わってこない人生だったが、どのような営みが行われているかについて学ぶのに良い本だった。 顧客ロイヤリティを上げるには何が必要か、というところを改めて考えさせられる良い本。Effortless Experienceという考え方はSREのToilをなくす的な考え方でもあるなとも感じる。 GainsightのCEOが書いたカスタマーサクセスがこれ一冊で理解できる本。カスタマーサクセスという考え方がなぜ必要になったか普及したかなどSaaSの運営上その背景を含めて理解できる良い本。 SmartNewsで働いていたころから圧倒的にプロフェッショナルだなと思っていた西口さんが顧客起点の経営というテーマを語った本。あらためて顧客起点でビジネスを作っていくってところで襟が正される。 PMFってよく使われる言葉だけど具体的に何?ってのをいちから説明してくれる本。自分は読むまでCPF、PSF、SPFなどプロダクトの他のステータスについては知らなかったので、読んで良かった。 DHHがベースキャンプをどういう哲学で運営しているかが垣間見える本。こういう考え方のもと従業員が働ける会社があっても良いなと思わせてくれる。 Just for Funというタイトルが良い。リナックスがどういう風につくられてきたかの歴史が知れる本。 強い組織カルチャーがある会社ってときに割と言及される高級ホテル運営のリッツ・カールトン。確かにその顧客フォーカスの哲学は学ぶところがあるなと思った本。 東京にもある高級リゾートホテルグループのアマンの創業についての歴史ノンフィクション。仕事とは本当に関係ないけど、ひとは高級ホテルの何に高額を払うのだろうかというところを改めて考えさせられるし、アマン泊まってみたくなる。 最後に、妻に何かおすすめないかと聞いたら教えてくれた本。現代でも通じる読みやすい日本語がどういうものかについて説明されているとのこと。


: シリコンバレー式ずけずけ言う力")



 マーケティング・インサイドセールス・営業・カスタマーサクセスの共業プロセス")




の教科書 良い市場を見つけ、ニーズを満たす製品・サービスで勝ち続ける")
")
")


")
さいごに
合計40冊紹介した。どれも良い本なので読んでみてください。
特にエンジニアリングに必須ではない図書40冊 前編
はじめに
ITエンジニア必読本10選、みたいな記事は定期的に生まれ、バズる。 みんな興味があり自分の体験や意見がそれぞれあるからかなと思う。現代ではIT技術職の仕事も多岐にわたるので全てのひとのお眼鏡に適うのは難しい。 先週はエンジニアリングの必須図書40冊という記事が盛り上がっていた。
選書は個性が出るから面白い。また、その人と背景が似通っているほど刺さりやすい。 一方、日頃からアンテナを張っていないと、自分に合った良い本を知る機会はあまり無い。
ということで、自分と似た背景を持つ人(30代テック・スタートアップ業界関係者)向けにあまりエンジニアリングに関連しない書籍をおすすめする記事があっても良いなとふと思ったので、自分が過去に読んできた中で面白いと思った本を並べる。
特にエンジニアリングに必須ではない図書20冊
Sci-Fi
")
普段SF小説を読まない人に一冊おすすめするならこれ。全ての短編が素晴らしい。

仮説と検証を繰り返して問題を解決していく科学的な営みが物語にめちゃくちゃ上手く盛り込まれている。地味だから映像作品では描きにくい要素だと思うので、映像化されるだろうけれど書籍で読むのがおすすめ。
")
三体の作者による短編集。短編も良い。どれも良いけど、資本主義が進んだ結果その星の全ての資源がひとりの人間に所有された世界がでてくる話が印象に残っている。
")
全4冊読まないと一区切りしないのでめちゃ長いけど、SFの全てが詰まっている。訳も素晴らしい。

さまざまなテーマをSF作家がどう描いてきたのかってテーマごとに書籍が良い感じ紹介されているので、広くいろんなジャンルのSF小説を知りたい人におすすめ。
投資・金融・経済
日本もデフレから脱却したし、投資は身を守るために必要だ。経済や金融の話がわかればニュースも理解できて世の中の見え方も変わってくる。

")
どちらも版が重ねられ更新されている株式投資の入門書の定番。投機ではない株式投資がどういうものか、読むとある程度理解できる。


株式投資をするときに企業の価値ってのがどういう風に見積もられているのかって話がなんとなく分かる。
")
資本主義の限界はずっと叫ばれているが、そのような社会問題に対して経済学がどのようにアプローチして研究されているかが分かって面白い。

資本主義は倫理観点から批判されるが、正しい状況とはどんなものか、どうしたらもっと良くなるのかといかということを改めて考えるきっかけになる。
")
")
リーマン・ショックの発生が臨場感豊かに詳細に描かれていて金融ドラマとしてとても面白い。
生活

働きたくない人のための本。まあそういう状況を作り出すためにはもちろん労力が必要なんだけど、その実践が具体的で面白かった本。
")
新型コロナに罹患したし、そういえばウィルスについて何も知らんなと思って手に取った本。生命と物質の境界線やその奇妙な働きについてわかりやすく説明されていた。
")
デジタルデトックスしたくなるし、完全に断つのは無理にしてもアテンションエコノミーに自覚的になる本。

あまり日常生活で思いを馳せることのない「実在とは?」みたいな疑問を物理学がどうアプローチするかという話でとても好奇心をそそられる。2022年のノーベル賞をとったベル不等式の破れがなんとなく理解できた気になる本。

体に良い食事はどんなものか、これまでの研究で分かったことをまとめた書籍。歯切れの悪いところも科学的っぽい態度で良い。
:「老いない」科学の最前線 (NewsPicksパブリッシング)")
死から少しでも逃れるにはどうしたら良いかの研究をまとめた本。寿命は所与のものっぽい考えだったけど、こういう研究があるんだなーって面白かった。

ビル・ゲイツが気候変動による災害に対してわれわれが何をできるかその考えをまとめた書籍。定量的に考えているので自己満足以上の結果を出すための活動はどんなものか説明していて勉強になった。
まとめ
本当は40選ということで40冊選んだんだけれど、紹介するの大変だったので半分に減らしました。誰か興味があれば後半もやります。
もし選書が気に入ったらコーヒーおごってください。Buy Me a Coffee
なぜ使われないダッシュボードが作られるかという話
はじめに
最近、ビジネスダッシュボードの設計・実装ガイドブックという書籍が出版された。今まであまりなかった視点から書かれたデータに関する本で面白く読んだ。

作ったダッシュボードの利用が進まず、虚しさを覚えた経験がある人は多いと思う。どうしてそうなってしまうのか、自分の経験を元にまとめたいなと思ったのでまとめる。
なぜ使われないダッシュボードが作られるか
なぜ作られたダッシュボードが使われないかと言うと、基本的にはそのダッシュボードがそんなに必要なものではないからだ(社内周知がうまくない、ツールの使い方がわからない人が多いなどの理由もあったりするがここでは無視する)。 必要のないダッシュボードが作られてしまう状況に関しては、以下の原因があると思うのでそれぞれ考えていく。
- ダッシュボードがなぜ必要かの理解が不十分なまま作り始めてしまうから
- アウトカムより目に見えるアウトプットに人は安心するから
- そもそも人のニーズを捉えたプロダクトを作ることは難しいから
1. ダッシュボードがなぜ必要かの理解が不十分なまま作り始めてしまうから
仕事の中でダッシュボードを利用したことがある人は多く、何らかデータが見たいとなった時にそれをダッシュボード化すると便利かもしれないと思う気持ちがうまれるはわかる。一方、ダッシュボードを利用したことある人と比べダッシュボードを作成したことのある人は少なく、そのなんとなくの感覚のままダッシュボードの作成が決定されてしまうことは多い。しかしながら、ダッシュボードというのはデータの分析・可視化にとっての万能ツールではなく、ダッシュボード化すべき対象や状況というというのは限られるため、希薄な目的意識の元では簡単に無用の長物ができあがってしまう。
この失敗はよく語られているところだが、その対策はなぜダッシュボードが必要なのかを明確にする要求定義フェーズをしっかり設けることだ。ダッシュボードに向かない具体的な状況や要求定義をどう進めるかなどについては、前述の書籍に記載があるので参照すると良い。ダッシュボードというものは一般的に何をするためのもので、あなたがしたいことは何で、そのしたいことのために本当にダッシュボードは必要なのかという話をダッシュボードを作る前にステークホルダーの間でしっかりすると良いだろう。すると、ダッシュボードではなく他の何かで十分満たされることが判明することもあるだろうし、不必要なダッシュボードが作られることは減るはずである。
上で述べたようなケースは、データのスペシャリストがダッシュボード活用の性質を理解して適切に利用者の要求を捌ける前提があることに注意が必要だ。 世の中にはデータチームの中でもそこまで知見がある人ばかりではなく、利用者の要求にそのまま従いダッシュボードを作成してしまうことも多い。まあ失敗しても死ぬわけではないし実務を重ねながら学ぶことも多いだろう。
2. アウトカムより目に見えるアウトプットに人は安心するから
また、ダッシュボードの作成依頼を受けた人に専門知識があった上でダッシュボードの必要性に疑義を感じたとしても、要求者の依頼にそのまま従うような場合も十分にあリえる。
なぜなら、データチームにとってダッシュボードを作ることはそれが仕事の一部であり、人を説得してまで作らないという選択をするよりも作る選択をする方が短期的には安全で楽だからだ。依頼者はもちろんそれが必要だと信じているから依頼をしてくるのであり、自分の考えが伝わらないリスクとか面倒なエンジニアだと思われるリスクをとり何のアウトプットもない状況より、例え使われない可能性があるとしてもダッシュボードを作るという選択をして何かしらアウトプットを得ることを選ぶことは、まあ人間として自然な心情かもしれない。
これは、インセンティブとかジョブセキュリティとかの話かと思う。これを防ぐには、使われないダッシュボードを作ることにペナルティを課すとか、全く評価しないとかアウトプットよりアウトカムを評価する、ダッシュボード作成以外の仕事も増やすようにする、とかが考えられるが、まあ組織的な工夫が必要だろう。
3. そもそも人のニーズを捉えたプロダクトを作ることは難しいから
前述の書籍の内容は、クライアントからお金をもらったプロジェクトの話で、そのようなケースではそもそも重要でないプロジェクトは俎上に上がりにくい。一方で、世の中クリティカルな仕事ばかりではないため、やはりそれが作るべきダッシュボードかを見極める力は重要だ。前述のようにダッシュボードの要求定義をして、作成するエンジニア(あなたや私)がまあその要求は妥当だと思ったとして、実際にそのダッシュボードが利用者に響くものかはわからない。依頼者はただのダッシュボード利用者の代表であり(そうでない場合もある)、依頼者の想定が間違っていることも十分にあり得るからだ。
成功しないスタートアップが世を占めることからわかるように、使われる製品を作るのはとても難しい。ダッシュボードもデータプロダクトの一種である。アウトカムにこだわるなら一般的なプロダウトマネジメントのプロセスに従ってダッシュボードをマネジメントすることを考えても良いかもしれない。