Data Lineage したい
条件
- 現職で管理している現行のデータパイプラインである Treasure Workflow(managed digdag on TD)+ Presto に適用できること
- ウェブでメタデータのドキュメントが公開でき、社内に共有できること
- Data Lineage 的なデータの依存関係がわかること
dbt
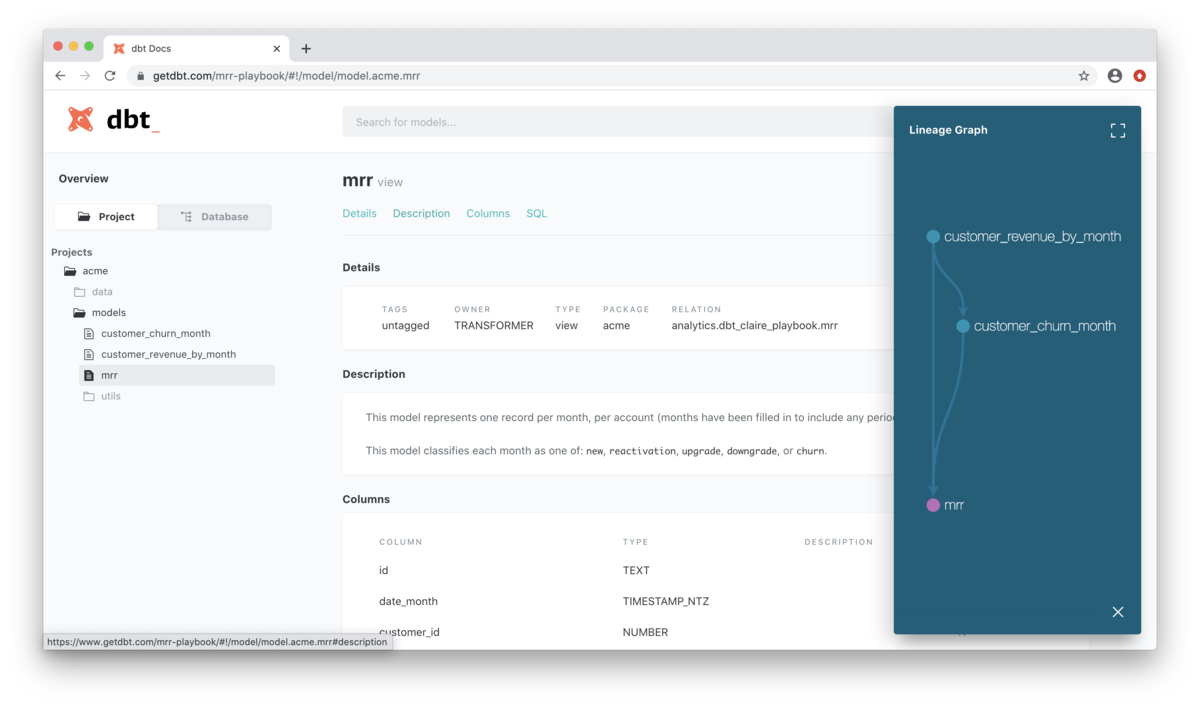
dbt は構築したプロジェクトとその内部のクエリを元にドキュメントを自動で生成してくれる。データの依存関係のDAGを可視化してくれるようで、良さそう。dbt docs serve というドキュメントサイトをホストする機能も提供しているが、現時点では本番稼働を想定していないものらしい。その代わりに dbt Cloud を使う、生成したドキュメントを S3 でホストするなどの方法を推奨している。
The dbt docs serve command is only intended for local/development hosting of the documentation site. Please use one of the methods listed below (or similar) to ensure that your documentation site is hosted securely!
しかし、dbt はデータを transform( ETL の T )することを主眼にしており、そのプロジェクト内部で管理するパラメータを埋め込んだクエリからリソースを materialize することを想定している。現行のデータパイプラインではクエリの実行に digdag の td opeartor (td>:) を使用しており、もし dbt を使うならその部分を置き換える必要がある。sh>: は提供していないため dbt CLI は使えず、Python API はまだ使用を推奨していないため現行のパイプラインとの共存は難しそうである。
Presto の adopter は partial support らしい。
Due to the nature of Presto, not all core dbt functionality is supported. The following features of dbt are not implemented on Presto: 1. Snapshots 2. Incremental models
Marquez
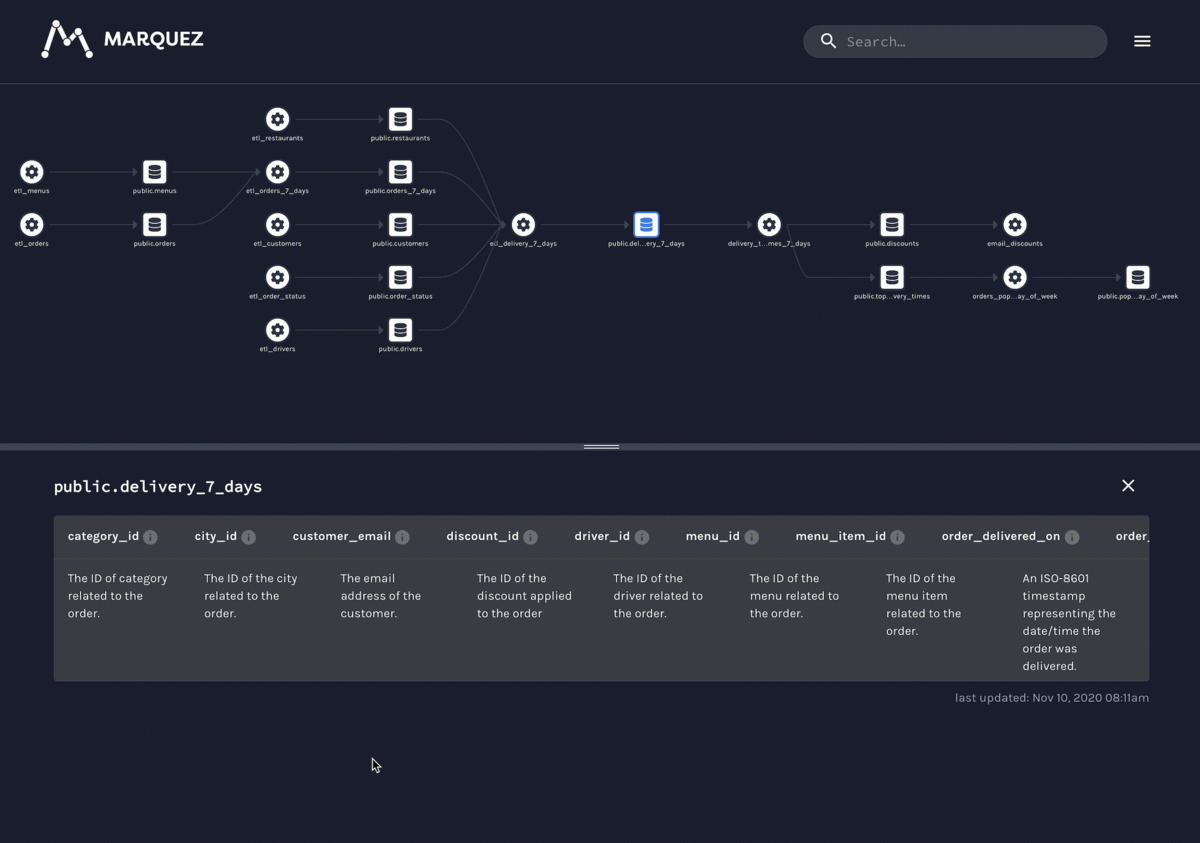
パイプラインとメタデータ管理が結合している dbt が使えなかったので疎結合っぽいアーキテクチャのが良いのかなと思い、思い出したのが WeWork の Marquez。こちらは、REST API を提供しており、Namespace、Source、Dataset、Job、Run などのリソースを登録すると可視化してくれる。これなら現行のパイプラインに適宜 REST API を叩く処理を追加するだけで実現できる。とてもシンプルな作りのアプリケーションで、ぱっと見 UI はこなれていなさそう。OpenLineage API の reference implementation らしい。
DataHub
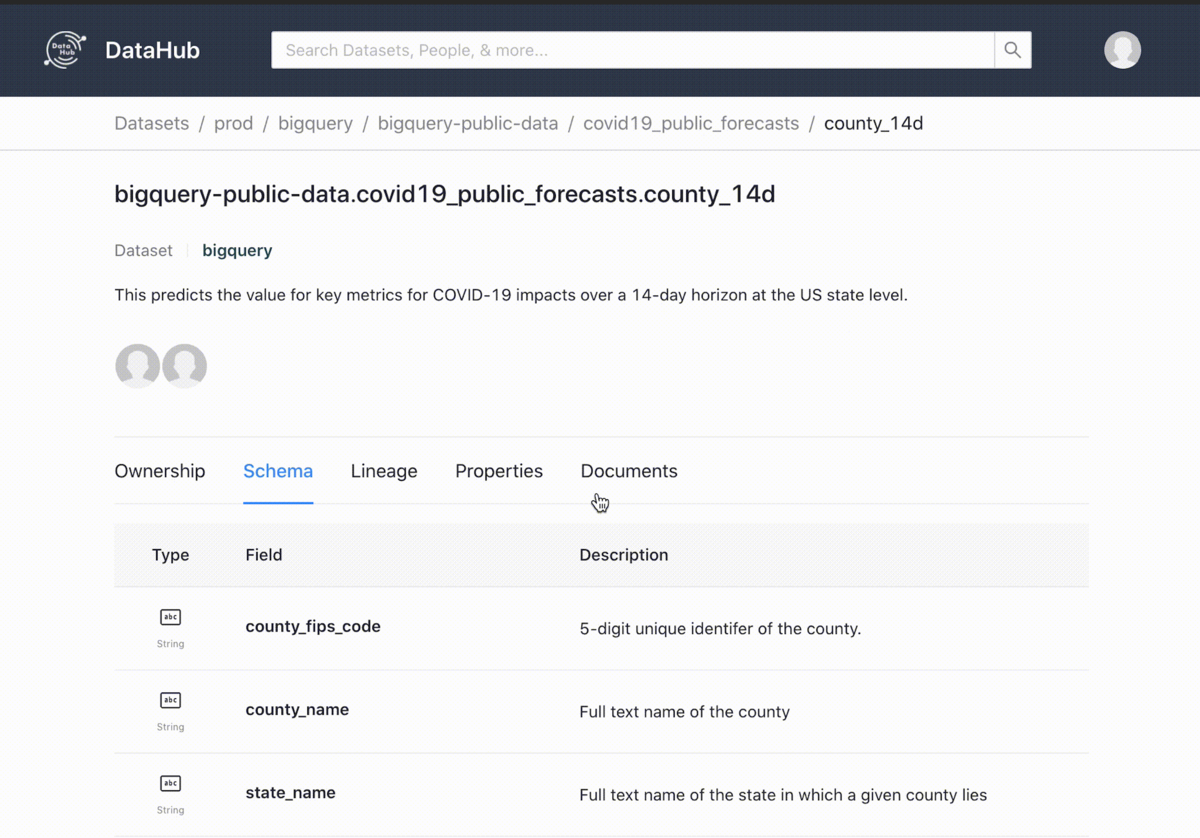 LinkedIn が開発した DataHub も push 型。HTTP と Kafka を通じてメタデータを格納できる。アーキテクチャが重厚でちょっと気軽に管理できる感じじゃないかな。Acryl っていう Managed な SaaS サービスも提供予定っぽい。
LinkedIn が開発した DataHub も push 型。HTTP と Kafka を通じてメタデータを格納できる。アーキテクチャが重厚でちょっと気軽に管理できる感じじゃないかな。Acryl っていう Managed な SaaS サービスも提供予定っぽい。
Amundsen
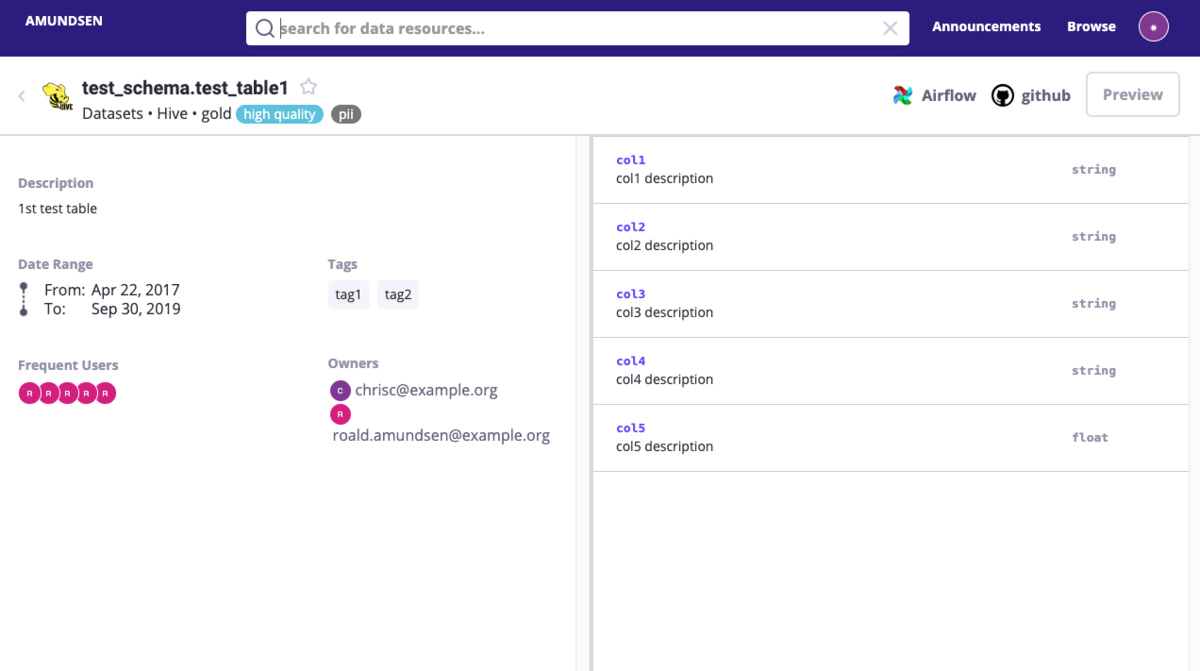
Lyft が開発した Amundsen はメタデータ管理 OSS の中でも割と活発に開発されている印象があるが、Data Lineage はスコープ外っぽい。
Tokern
Tokern って OSS はクエリをパースして column level の可視化をしてくれるらしい。機能はかなりシンプル。
SQLdep
SQLdep ってサービス?がクエリをアップロードすると良い感じに可視化してくれていたっぽいけれど、今はもう閉じちゃったのかな。
AlphaSQL
そういえば、AlphaSQL ってクエリ参照して依存関係可視化、Airflow DAG自動生成みたいなことやってるプロジェクトもあったなと思い出した。
感想
とまあ、ここまで適当にツール群を調べてみたが、結局自分がしたかったのはデータ依存関係とデータの説明をドキュメント化するのを良い感じに自動化したいってことだと気づいた。その場合、クエリをパースし、テーブルスキーマを参照して依存関係を含む何らかの設定ファイルを生成、そこにデータの説明を手動更新して、(dbt みたいに)静的 HTML を生成するようなツールがあれば良いのかな。