Modern Data Stack / モダンデータスタックというトレンドについて
- はじめに
- Modern Data Stack ?
- Modern Data Stack の特徴やメリット、関連するトレンド
- 各社ファウンダーが考える Modern Data Stack
- さいごに
- Further Readings
はじめに
Modern Data Stack というワードを最近よく目にするようになった。あまり日本語の情報も多くなさそうなのでその周辺情報をまとめてみる。
Modern Data Stack ?
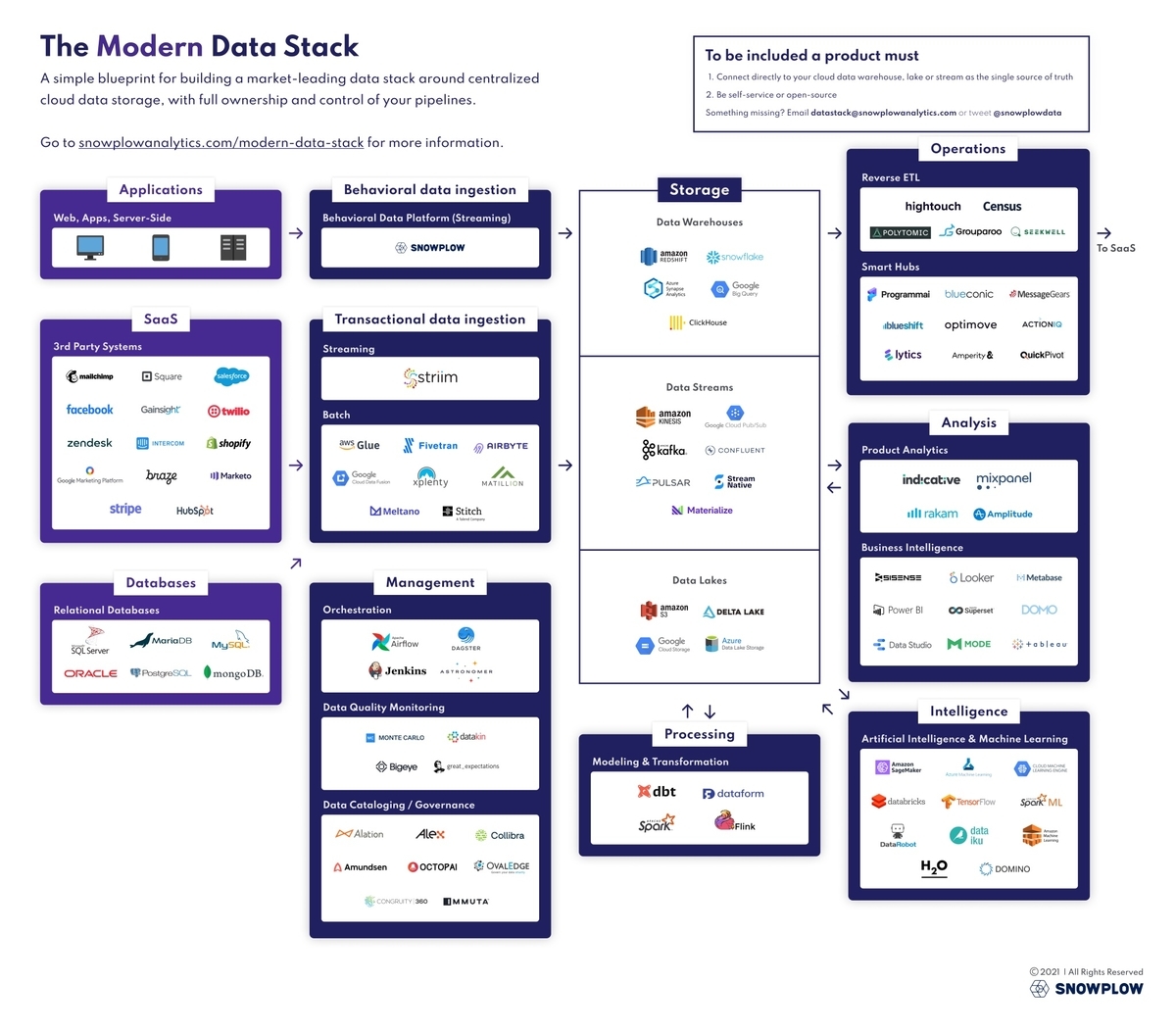
Modern Data Stack とは、10-20年くらい前からあるデータ処理関連のサービスやソフトウェアと比べて、現代の環境に相応しい設計やコンセプトを提案するような新しいサービス・ソフトウェア群自体、またそれに伴いデータをよりよく取り扱うための方法論や今後の行く末について議論が活発になっているというトレンドを表すバズワードである。 基本的にはツールとしてはクラウド化や周辺技術の進化により、スケーラビリティが高くなったり、特定用途に特化し技術的知識があまり要らなく簡単な設定のみで動く、低コストで要望を実現できるなど、利便性が向上しているという特徴がある。
2020 年からは Modern Data Stack Conference が fivetran 主催で行われていたりするので、アップデートにはその辺を参照すると良い。
Modern Data Stack の特徴やメリット、関連するトレンド
下記の Preset 社のブログ記事が情報量も多く面白かったので、以下ではこちらの記事をもとに、あわせて他の記事も参照して自分の感想も加えながらそのトレンドをまとめていく。ちなみにこの記事は、Airflow、Superset のクリエーターの Max Beauchemin 氏のものである。さすが。
データインフラのクラウドサービス化 / Data infrastructure as a service
Snowflake, BigQuery, Firebolt, その他 Managed Airflow サービスの登場など、各種データインフラはマネージドサービスとして提供されるようになっている。それにより、エンジニアがデータインフラを構築する場面は確実に減っている。 代わって、データエンジニアリングチームは、ツールの選択、統合、およびコストの抑制に今後ますます関与していく必要がある。
- 調達 / procurement
- 技術やベンダーの調査、コンプラインアンスや各種ポリシーや導入コスト対効果の評価
- インテグレーション / integration
- 異なるツール間のインテグレーションは大変
- コストコントロール / cost-control
- 従量課金制で青天井なサービスなんかを使う時は、実際に払っただけ価値が出ているかを考えないといけない
関連ツールがさまざま出てきている昨今、トレンドをキャッチアップして正しく技術選定することで結果には大きな差が生まれるだろう。組織に合わないツールを導入することでオペレーションコストや実費には何倍、何十倍もの差が生まれる。
データ連携サービスの発展
昔は各種 SaaS 上のデータを連携するためにコードを書いていたが、データ連携のための Fivetran などのサービスや Meltano や Airbyte みたいな OSS の登場によってそのような問題は解決された。現代でゼロからそのような連携の仕組みを自社開発する必要はない、という話。
ELT! ELT! ELT!
DWH の進化で分散処理が手軽になるにつれて、データのあるところで変換処理をするべきだという話。
ETL よりも ELT をしろってのは最近のトレンドではないが、ますます一般的になるはずってのはまあその通りだと思う。Spark において SparkSQL の重要性が増しているように、同じコンポーネントでデータの変換と分析という本来は異なるワークロードができることが当たり前になっていき、ますます ETL システムがデータベースみたいに振る舞うことが多くなっていく。ストレージとコンピュートの分離も進んでいるので、Spark とか Presto とかをみるとそうだよねという感じ。まだまだ、任意の処理を実行するって感じではないけど、UDF とか独自関数の発展をみると良くはなっている。このトレンドが dbt による ELT の管理というニーズとつながっている。
Reverse ETL
Reverse ETL については下記の記事で紹介したので割愛する。
Max Beauchemin は Reverse ETL をかつての Master Data Management (MDM) のサブセットであるみたいな紹介をしており、EAI とか EII とか勉強しても面白いかもよって言っている。
テンプレート化された SQL and YAML などによるデータの管理
ELT の一般化によって、データの管理はテンプレート化された SQL や YAML によって行われるようになってきている。 SQL はすでに標準化され成熟したインターフェイスであり、テンプレート化も容易で柔軟性も与えられるし、コード管理できCI/CDも適用可能であるためである。 この辺は k8s によりリソースの宣言的な管理が進むインフラ周りと同じ方向に進んでいる。 Connor’s McArthur’s 2018 talk “KISS: Keep it SQL, Stupid” がおすすめ。
そのようなトレンドがある一方で Max Beauchemin は、PHP + HTML が古びれていったように、SQL のテンプレート化による手法も表現の多様化には対応できなくなる可能性があると指摘している。例えば SQL のテンプレート化の問題点の一つとして、異なる SQL 方言間で reusable でないということを挙げている。ここにはまだ適切なプログラミングモデルが登場する余地がある。
セマンティックレイヤーの凋落と Headless BI
DWH 上のデータはスタースキーマやスノーフレークスキーマなど物理的な実体として存在する。そのまま利用するには各テーブル間の関係性などの知識が必要とされるために利用しにくい。そこで、DWH 上の物理的なデータをビジネスドメインの概念モデルに近づけ利用しやすくすることがセマンティックレイヤーの基本的な目的である(ざっくり)。
BIやDWHやETLツールなどのレイヤーがそのためソリューションを提供している(LookerのLookML、MicrosftのOLAP、TableuのLogical Layerなど)。複数の理由から(複雑すぎる、機能が製品をまたぐことができない、コード管理できないなど)それらの機能は決定的なものにならず、最近ではセマンティックレイヤーは非正規化され実体をもったデータとして(データマートとして)構築されることが多い。つまり、今日ではセマンティックレイヤーの実体はトランスフォームレイヤーに吸収されている。その結果、dbt などのツールが ELT の実行管理だけではなく、Data Lineanage など含めセマンティック管理の機能も搭載され、勢力が拡大している。
一方で、最近は Headless BI という概念も登場しており、セマンティックレイヤーの再興を促す動きもある。
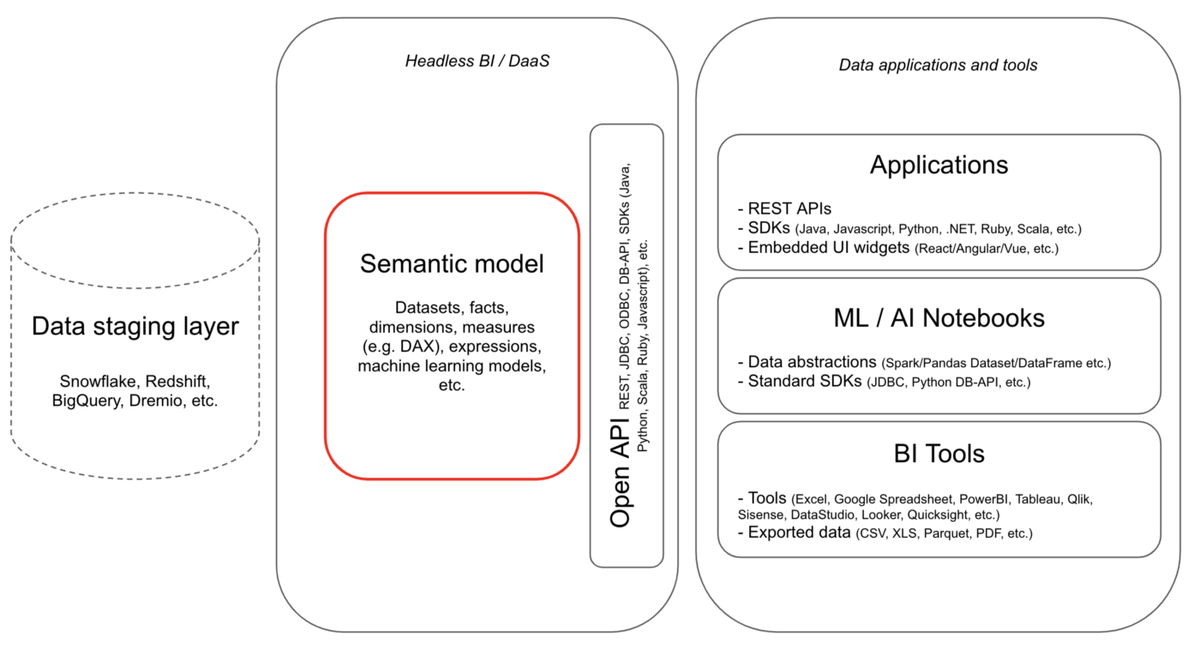
headless bi | base case capital
ちょうど今月リリースされた Supergrain は Headless BI を謳っており、コードによるセマンティックの管理と複数のインターフェイスによるデータをサーブする機能を提供する。
計算フレームワーク (Computation Frameworks)
上記で紹介した Supergrain のような Headless BI ツールにも関連するが、トランスフォームレイヤーに集約されたセマンティックの再利用性を高めることで、なんらかのドメインに特化したデータ変換フレームワークが登場してきている。
- metrics layer ( Airbnb's Minerva, Transform.co, MetriQL, Supergrain)
- feature engineering frameworks
- A/B testing frameworks
まだ、そこまでツール群が成熟している様子はないが、確かにメトリックの管理などはどの会社のデータ管理の中でも不可欠なものだし、それに特化した管理ソフトウェアが欲しいなと日々感じている(dbt にもメトリクス管理機能が実装されたっぽい)。
個人的にもこのレイヤーの発展は気になっているが、Max Beauchemin はこの概念を “data middleware”, “parametric pipelining” or “computation framework” と呼んでおり、また後で記事書くとのことで楽しみにしている。
分析プロセスの民主化、データガバナンスとデータメッシュの試み
Modern Data Stack は分析プロセスを民主化し、その結果、データを扱う仕事が遍く増える。ガバナンスの重要性が高くなるのは言うまでもない。この分野の製品は古くから存在するが(Collibra, Alation etc...)、エンタープライズに特化しており普遍的に使い勝手が良いものではなかった。そのため、スタートアップ各社は自社でそれ用のソフトウェアを作り運用するような状況が生まれていた。
- Linkedin: DataHub
- Lyft: Amundsen
- WeWork: Marquez
- Airbnb: Dataportal
- Spotify: Lexikon
- Netflix: Metacat
- Uber: Databook
要件に差はあるが需要があることは間違いないため、DataHub や Amundsen はスピンアウトし、マネージドサービスとして提供がなされはじめた(それぞれ Acryl Data, Stemma)
組織が大きくなるにつれ中央集権型のデータ管理は問題や労力が大きくなってくる。その結果、最近ではデータメッシュなどのキーワードも提起され、データの各エンドユーザーからなるそれぞれのドメインエキスパートがデータの品質・SLA に責任を持ち、組織全体にデータを提供する非中央集権型データガバナンスが模索されている。そのような組織では、データエンジニアリングチームは、組織の他のメンバーにベストプラクティスを指導、教育、および権限を与える上でその役割を果たすことになる。一方で、データがどのチームに所属するかなど自明でないことも多く、必ずしも簡単に導入できるものではないことに注意する必要がある。
プロダクト組み込み用データサービス
何らかの製品があったとき、ユーザーはその製品上のデータを利用することは必須である。それは REST API 経由かもしれないし、管理画面のダッシュボード経由かもしれない。一方で、基本的で一般的なニーズであるにもかかわらず、製品にそのようなデータ機能を組み込むための開発をする労力はとても大きい。この問題は単一の機能を持った製品が解決する問題というよりは、マネージド BI の Superset による組み込みダッシュボードの外部化、Supergrain のような Headless BI レイヤーによるデータと結びついたインターフェイスの提供など、各種アプリケーションの発展によるものになるのかもしれない。
リアルタイム
データをリアルタイムに活用できるようにするという夢は昔から語られている。製品内部で行うユーザーへのレポートをリアルタイムにできれば嬉しい、自社内のデータを簡単にイベントドリブンで利用、オペレーションに活用できたら嬉しい。ほぼリアルタイムのマテリアライズドビューをサポートしたPostgres互換のデータストアである Materialize 、CDC ベースのリアルタイムデータパイプライン構築サービス meroxa (マネージドDebezium?)など出てきているが、果たして今回は成功するのか。
Analytics Engineer の登場
これまでデータエンジニアはデータ基盤を管理し組織横断でデータ活用の面倒を見てきたが、今後はその需要の高まりに応じて、水平な役割を持つデータエンジニアのほかに特定のプロダクトやチームに紐づく Analytics Engineer として垂直の役割をする新しいロールが活躍できるだろうという話。その役割は、dbt Labs のブログ記事中によくまとまっている。
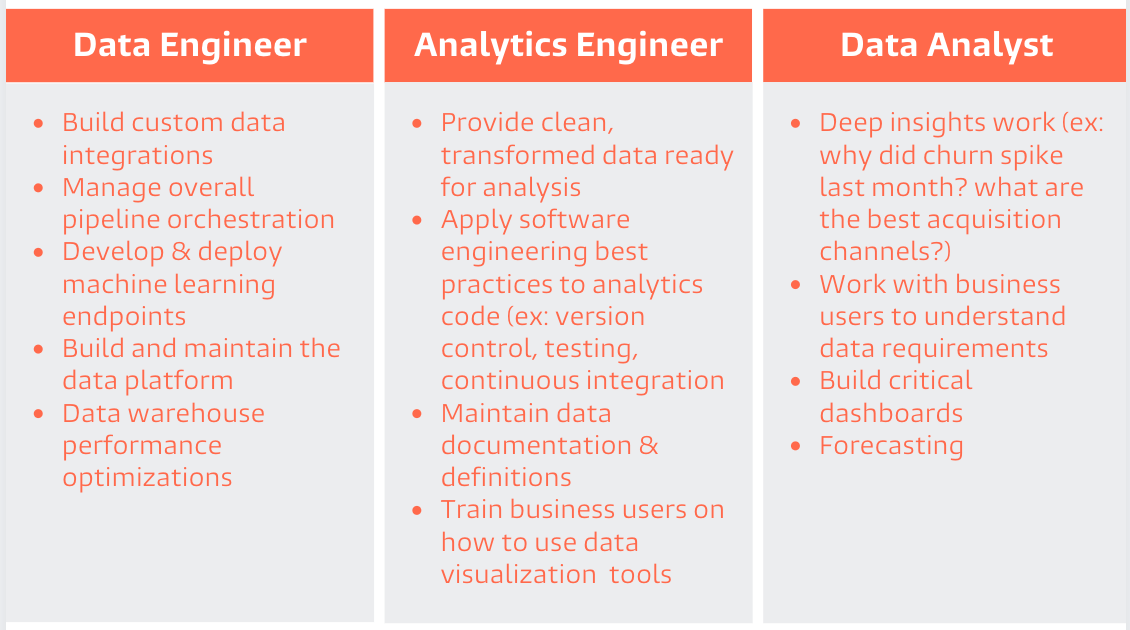 What is Analytics Engineering?
What is Analytics Engineering?
Web 開発において、フロント、バックエンド、フルスタックみたいな役割の違いがあるように、組織の中でのカバーする領域が異なるのは自然に思う。データ関連の職種はさまざま生まれつつある( “Data ops”, “data observability”, “analytics engineering”, “data product manager”, “data science infrastructure” etc...)。
各社ファウンダーが考える Modern Data Stack
最後に Modern Data Stack とは?という質問に対する各社ファウンダーの回答をまとめた記事を紹介する。 興味深いので是非読んでみて欲しい。
個人的には Census CEO の「データはプロダクト化される。そのためにデータチームをプロダクトチームのように“software-ification”するためのものがModern Data Stack」って見方が面白かった。
Data itself is turning into a product that serves all these various use cases, specifically because it is horizontal. So now the only way for a team to reach all the various stakeholders, if it's going to be horizontal, is to think and deliver like a product team. So to me, the Modern Data Stack is the “software-ification” of data organizations, turning what they do into an agile, business-like operational model.
Software Engineering の手法が進化していった後をついてデータ管理・活用の方法がこれから洗練されていくのだろう。
さいごに
ということで、Modern Data Stack についてまとめてみようと思ったら、思ったより長くなってしまったし細かいところで雑になってしまった。各論それぞれ掘り下げがいがあるのでまた記事にでもしたい。