はじめに
たまたま steampipe のサポートプラグインを見たら、結構充実していた。ちょっと調べたら dbt-steampipe プラグインも作られており、これを使ってクラウドサービス関連のデータ収集が dbt 上で管理できれば便利なんじゃないかと思ったので検証してみた。
Steampipe とは何か
Steampipe はいろんなクラウドサービスの API をラップして SQL でデータ取得できるインターフェイスを用意してくれる OSS。SQL のインターフェイスは PostgreSQL を立てることで提供している。
Steampipe is the universal interface to APIs. Use SQL to query cloud infrastructure, SaaS, code, logs, and more.
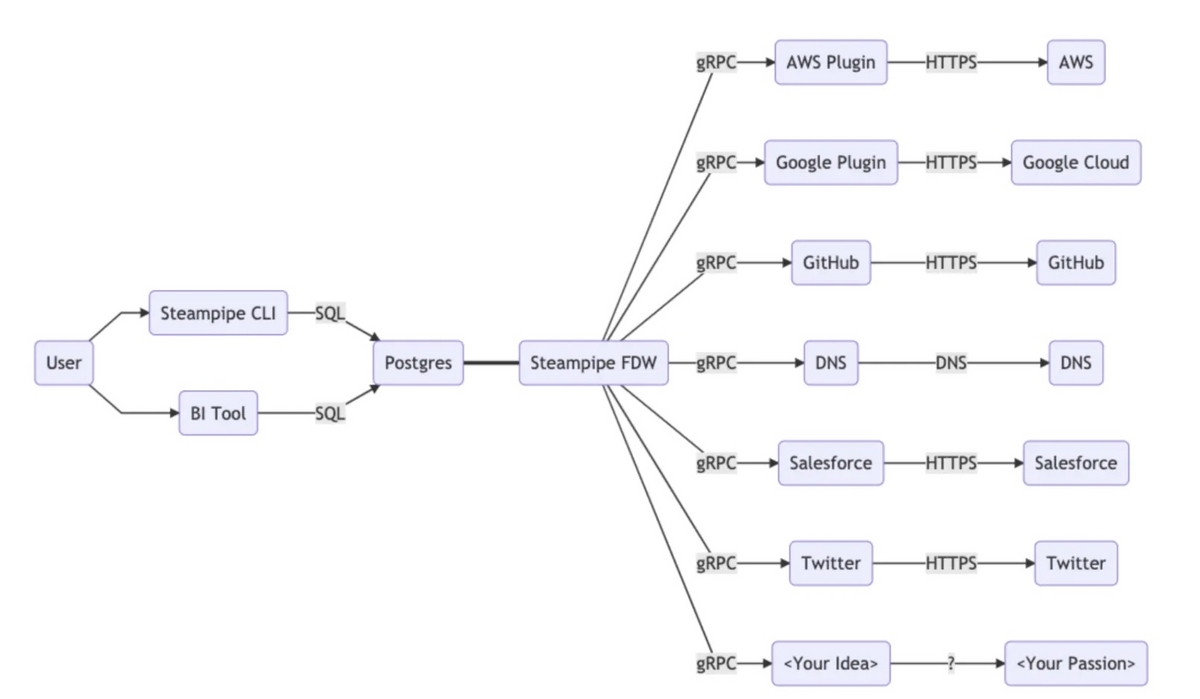
Developers | Documentation | Steampipe
ちなみに HCL でダッシュボードを構築・管理する機能も開発されていて割と面白い。
dbt-steampipe を動かしてみる
dbt-steampipe プロジェクトをクローンして、 Getting Started に従って steampipe が動くコンテナを立ち上げる。
docker compose build steampipe docker compose up
steampipe でクエリできるか確認する。. でコマンドを補完してくれる。無事に起動して steampipe が用意している gcp 用のテーブルは確認できたが、 credential 情報がなかったのでクエリには失敗した。
$ docker compose exec steampipe steampipe query
Welcome to Steampipe v0.16.4
For more information, type .help
> .tables
==> gcp
+---------------------------------------------------------+--------------------------------------------------------------+
| table | description |
+---------------------------------------------------------+--------------------------------------------------------------+
| gcp_audit_policy | GCP Audit Policy |
| gcp_bigquery_dataset | GCP BigQuery Dataset |
| gcp_bigquery_job | GCP BigQuery Job |
| gcp_bigquery_table | GCP Bigquery Table |
...
+---------------------------------------------------------+--------------------------------------------------------------+
To get information about the columns in a table, run .inspect {connection}.{table}
> select * from gcp_bigquery_table;
Error: rpc error: code = Internal desc = hydrate function listBigQueryDatasets failed with panic /home/steampipe/.config/gcloud/application_default_credentials.json: no such file or dir (SQLSTATE HV000)
gcloud auth application-default login を実行して credential を生成。改めてクエリしたが、次は gcp 上のプロジェクトを指定していなかったので失敗した。
$ docker compose exec steampipe steampipe query Welcome to Steampipe v0.16.4 For more information, type .help > select * from gcp_bigquery_table; Error: googleapi: Error 404: Not found: Project your-project, notFound (SQLSTATE HV000)
steampipe のコネクション情報は dbt-steampipe/conf/config.spc で指定されている。
connection "gcp" {
plugin = "gcp"
project = "your-project"
credentials = "/home/steampipe/.config/gcloud/application_default_credentials.json"
}
example の例ではこのようになっているが、 project を書き換えて再度実行する。
$ docker compose exec steampipe steampipe query Welcome to Steampipe v0.16.4 For more information, type .help > select * from gcp_bigquery_dataset +------+-----------------+-------------------------------------------+------------------+----------------------+-------------+--------------------------+---------------------------------+-----------> | name | dataset_id | id | kind | creation_time | description | etag | default_partition_expiration_ms | default_ta> +------+-----------------+-------------------------------------------+------------------+----------------------+-------------+--------------------------+---------------------------------+-----------> ... +------+-----------------+-------------------------------------------+------------------+----------------------+-------------+--------------------------+---------------------------------+----------->
クエリに成功した。
次は dbt-steampipe を使った dbt の実行。まずは dbt の依存性をインストール。
$ pip install -r requirements.txt
中を見ると dbt-postgres を用意している。
dbt-postgres==1.3.0
と思ったら、dbt-core 1.4 以下では python3.11 はサポートされていないようだった。 なので普通に pip で dbt-postgres をインストールして 1.4.5 を入れた。やっと dbt-steampipe の example を実行する。
$ cd steampipe_example $ dbt seed --full-refresh ... $ dbt run 13:36:57 target not specified in profile 'default', using 'default' 13:36:57 Running with dbt=1.4.5 13:36:57 Found 2 models, 0 tests, 0 snapshots, 0 analyses, 291 macros, 0 operations, 1 seed file, 427 sources, 0 exposures, 0 metrics 13:36:57 13:36:58 Concurrency: 1 threads (target='default') 13:36:58 13:36:58 1 of 2 START sql table model public.bq_billable_bytes .......................... [RUN] 13:37:01 1 of 2 OK created sql table model public.bq_billable_bytes ..................... [SELECT 0 in 2.88s] 13:37:01 2 of 2 START sql table model public.top_most_expensive_bq_jobs ................. [RUN] 13:37:01 2 of 2 OK created sql table model public.top_most_expensive_bq_jobs ............ [SELECT 0 in 0.18s] 13:37:01 13:37:01 Finished running 2 table models in 0 hours 0 minutes and 3.68 seconds (3.68s). 13:37:01 13:37:01 Completed successfully 13:37:01 13:37:01 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
exmaple の profile.yml はローカルの postgres を指しているようだ。
default:
outputs:
default:
type: postgres
host: localhost
user: steampipe
password: steampipe
port: 9193
dbname: steampipe
schema: public
threads: 1
なので接続して確認する。
$ psql -h localhost -p 9193 -U steampipe -d steampipe
Password for user steampipe:
psql (14.7 (Homebrew), server 14.2)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
steampipe=> \d
List of relations
Schema | Name | Type | Owner
--------+---------------------------------------------------------+---------------+-----------
gcp | gcp_audit_policy | foreign table | root
gcp | gcp_bigquery_dataset | foreign table | root
...
gcp | gcp_sql_database_instance_metric_cpu_utilization_hourly | foreign table | root
gcp | gcp_storage_bucket | foreign table | root
public | bq_billable_bytes | table | steampipe
public | bq_pricing | table | steampipe
public | top_most_expensive_bq_jobs | table | steampipe
(87 rows)
steampipe が用意している gcp 用のテーブル以外に、example プロジェクトで dbt の model として用意されている bq_billable_bytes と top_most_expensive_bq_jobs がテーブルとして生成されていることが確認できた。
aws プラグインを使って aws のコストデータを取得する
aws プラグインを試してみる。
例えば aws のコスト管理するような状況を想定して、コストデータを取得してみる。
docker-compose.yml を確認すると、既にインストール対象になっている。credential は ~/.aws/credentials を参照させているようだ。
services:
steampipe:
build:
context: .
args:
PLUGINS: aws gcp
command: ["service", "start", "--foreground", "--show-password"]
ports:
- 9193:9193
volumes:
- ~/.aws/credentials:/home/steampipe/.aws/credentials:ro
- "~/.config/gcloud/:/home/steampipe/.config/gcloud/"
- ./conf:/home/steampipe/.steampipe/config
environment:
- STEAMPIPE_DATABASE_PASSWORD=steampipe
conf/config.spc に下記を追加してコンテナ再起動。(ここでprivateは~/.aws/credentialsに追加されているプロファイル名である)
connection "aws" {
plugin = "aws"
profile = "private"
}
aws のコスト関連のテーブルはいくつか用意されているが、今回は aws_cost_usage を incremental に追加するよう sql ファイルを用意する(本当はユーザー定義タグごとに集計したデータも見たかったが、現時点でサポートしていないみたい。PRはあるのですぐにサポートされそうではある)。models/example/aws_cost_usage.sql に下記のようなクエリを追加する(granularityと二つのdimensionは要指定らしい)。
{{
config(
materialized='incremental'
)
}}
select
*
from aws.aws_cost_usage
where granularity = 'DAILY'
and dimension_type_1 = 'SERVICE'
and dimension_type_2 = 'OPERATION'
{% if is_incremental() %}
and period_start > (select max(period_start) from {{ this }})
{% endif %}
dbt runをする。
dbt run 03:04:28 target not specified in profile 'default', using 'default' 03:04:28 Running with dbt=1.4.5 03:04:29 Found 3 models, 0 tests, 0 snapshots, 0 analyses, 291 macros, 0 operations, 1 seed file, 427 sources, 0 exposures, 0 metrics 03:04:29 03:04:29 Concurrency: 1 threads (target='default') 03:04:29 03:04:29 1 of 3 START sql incremental model public.aws_cost_usage ....................... [RUN] 03:05:00 1 of 3 OK created sql incremental model public.aws_cost_usage .................. [SELECT 9617 in 30.90s] 03:05:00 2 of 3 START sql table model public.bq_billable_bytes .......................... [RUN] 03:05:01 2 of 3 OK created sql table model public.bq_billable_bytes ..................... [SELECT 0 in 0.95s] 03:05:01 3 of 3 START sql table model public.top_most_expensive_bq_jobs ................. [RUN] 03:05:01 3 of 3 OK created sql table model public.top_most_expensive_bq_jobs ............ [SELECT 0 in 0.25s] 03:05:01 03:05:01 Finished running 1 incremental model, 2 table models in 0 hours 0 minutes and 32.71 seconds (32.71s). 03:05:01 03:05:01 Completed successfully 03:05:01 03:05:01 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
成功した。postgres に繋いで生成されたテーブルを確認してみる。
$ psql -h localhost -p 9193 -U steampipe -d steampipe
Password for user steampipe:
psql (14.7 (Homebrew), server 14.2)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
steampipe=> \d
...
public | aws_cost_usage | table | steampipe
public | bq_billable_bytes | table | steampipe
public | bq_pricing | table | steampipe
public | top_most_expensive_bq_jobs | table | steampipe
steampipe=> \x
Expanded display is on.
steampipe=> select * from aws_cost_usage limit 10;
dimension_1 | Amazon Route 53
dimension_2 | AAAA
granularity | DAILY
search_start_time |
search_end_time |
dimension_type_1 | SERVICE
dimension_type_2 | OPERATION
period_start | 2022-03-19 00:00:00+00
period_end | 2022-03-20 00:00:00+00
estimated | f
blended_cost_amount | 0.000136
blended_cost_unit | USD
unblended_cost_amount | 0.000136
unblended_cost_unit | USD
net_unblended_cost_amount | 0.000136
net_unblended_cost_unit | USD
amortized_cost_amount | 0.000136
amortized_cost_unit | USD
net_amortized_cost_amount | 0.000136
net_amortized_cost_unit | USD
usage_quantity_amount | 340
usage_quantity_unit | N/A
normalized_usage_amount | 0
normalized_usage_unit | N/A
partition | aws
region | global
_ctx | {"connection_name": "aws"}
...
ということで、steampipe で取得した aws のコストデータがこのように dbt の出力先の postgres にテーブルとして追加されたのを確認した。
さいごに
データの変換は dbt を使って DWH で実行するようになってきているが、 steampipe を使って各種データソースからのデータ取得も dbt 上で管理できるようになったら便利かもしれないと思い、検証してみた。Salesforce、Zendesk、Slack、Jira、Google Sheet などのプラグインはあるのでシンプルな用途では使えそうだが、実際にどんなデータがサポートされているかは要確認かな。Redditとか LinkedIn とかのプラグインがあるのは興味深い。ぱっと見、 steampipe のプラグインは developer 向けのサービスが多いため、real world な用途にはもうちょっとプラグインが拡充されて欲しい気がしなくもない。
一方で、各種データソースのためのプラグインは dbt にもそれぞれ存在することもあるので(e.g. dbt-salesforce)、間に steampipe を挟むことのメリット・デメリットをどう捉えるかは議論の余地がある。エコシステムの大きさを考えると dbt プラグインの拡充に期待する方が順当かなどうかなー。