リバースETLはデータパイプラインの何を変えるのか
はじめに
リバース ETL という概念が提起されて、そのための SaaS も生まれており、面白いと思うので所感をまとめる。
Reverse ETL ?
自分が最初に Reverse ETL という言葉に触れたのは、Redpoint Ventures の Astasia Myers が 2021-02-23 に書いたこの記事だった。
彼女はどんなものをリバース ETL と呼んでいるかというと
Now teams are adopting yet another new approach, called “reverse ETL,” the process of moving data from a data warehouse into third party systems to make data operational.
とまあ難しいことはなく、データウェアハウスからサードパーティシステムにデータを移動させるプロセスのことをそう呼んでいる。 記事を参照すると、すでに Hightouch, Census, Grouparoo(open source), Polytomic, Seekwell などのリバース ETL 用のサービスが生まれているうようだ。
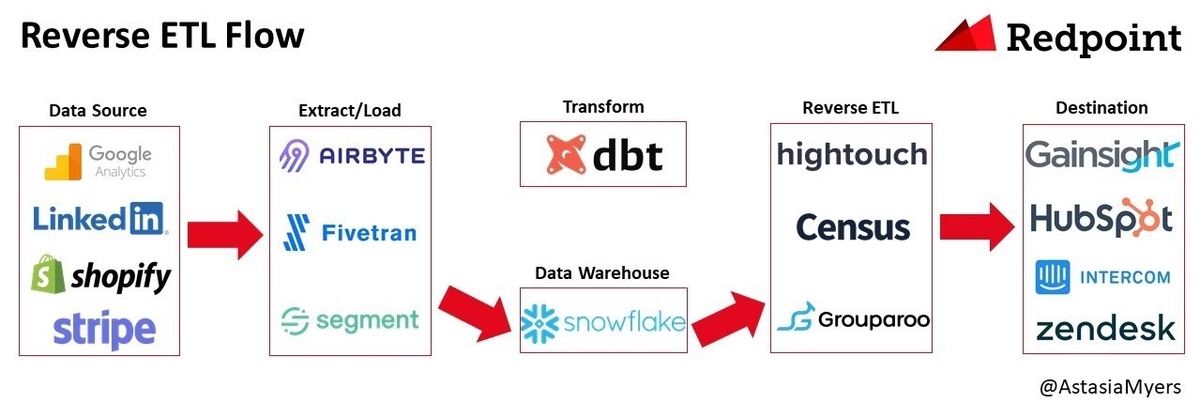
リバース ETL が提起された背景には、各事業者においてデータウェアハウスやさまざまな SaaS 活用が進んだため、データウェアハウスのデータを SaaS に活用するためのデータパイプラインが複雑化、多様化したという状況があるだろう。そのため、そのようなパイプラインを用意しようとすると、データエンジニアがさまざまな SaaS の API を調べて個別に実装する必要があり、コストが大きかった。
その integration は Embulk や Airlfow などではプラグイン化され、取り回しはそれまでよりしやすくなったが、Reverse ETL を謳うサービスを使うことで状況はより良くなるかもしれない。
拡張された ETL パイプライン
Census のブログ記事中の、データ活用サイクルを表現した図が面白い。
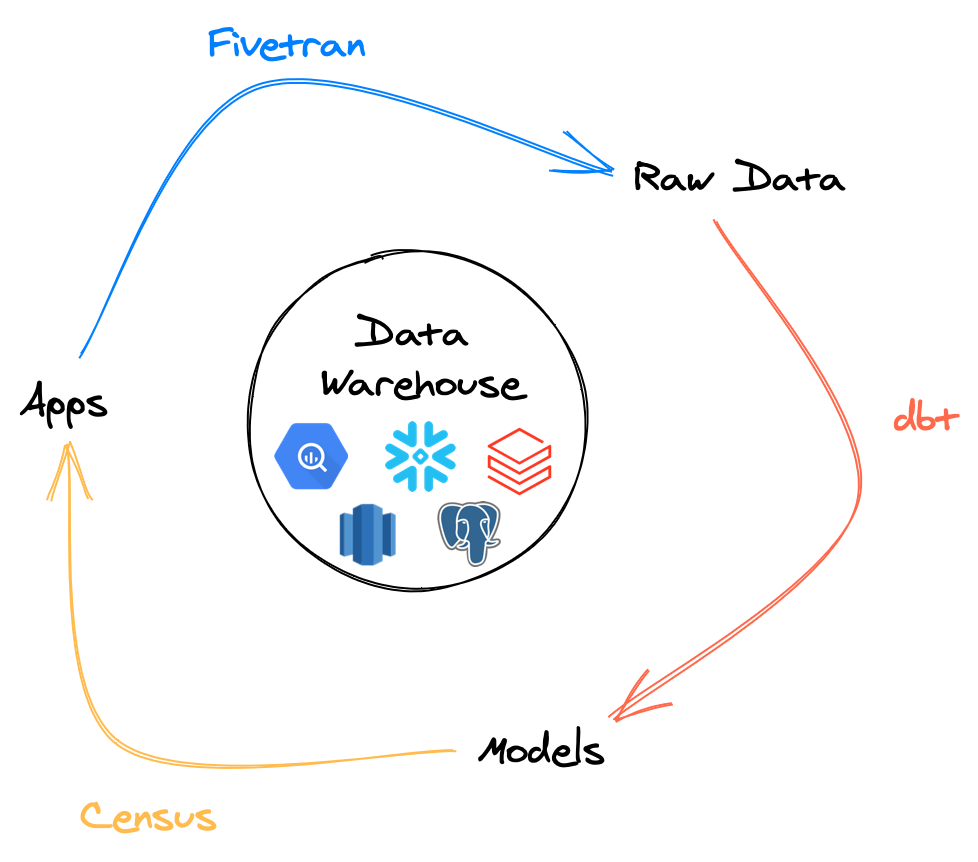
それぞれの矢印が
- Forward ETL: Fivetran による、App(データソース)からデータウェアハウスまでデータを ETL するプロセス。(Forward ETLは今自分が考えた用語)
- Transform: dbt による、データ変換プロセス
- Reverse ETL: Consus による、データウェアハウスから App(データ活用アプリケーション)までデータを ETL するプロセス。
を表現している。
従来の ETL では、データ活用の手続きにおいて、データソースからデータウェアハウス上の最終成果物までの移行過程が ETL として表現されていた。 上記の図では、それがデータソース(App)から SaaS 上の最終成果物(App)までのひと続きの ETL として表現されている。この表現はシンプルでわかりやすく、良く抽象化されている気がする。これまでの、データウェアハウスまでで完結していた ETL は、上記のサイクルにおける特殊形にすぎない。
ETL パイプラインの発展過程
上述の ETL パイプラインのサイクルに関して、その進化の過程を実装者の観点から考えてみると、このような感じだろうか。
- 第一段階(全て自前実装)
- Forward ETL: エンジニアが実装する
- Transform: エンジニアが実装する
- Reverse ETL: エンジニアが実装する
- 第二段階(in/outのプラグイン化やアプリ側の対応が進む)
- 第三段階(in/outのサービス化)
- Forward ETL: サービスを利用し、データ利用者が設定する
- Transform: エンジニアが実装する
- Reverse ETL: サービスを利用し、データ利用者が設定する
すんなりとこんなに綺麗には分かれないとは思うが、この最後の段階の何が嬉しいかというと、それぞれの責任分界点とインターフェイスがはっきりすることだと思う。
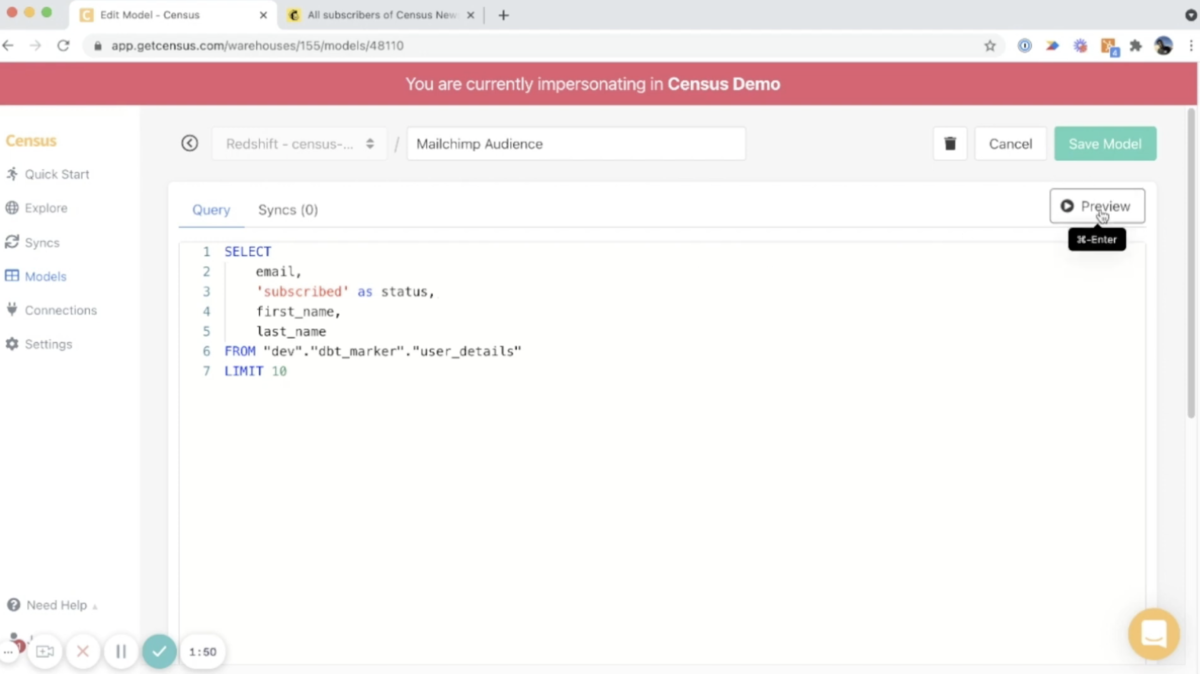
たとえばリバース ETL サービスのひとつである Census は、この写真のように、接続したデータウェアハウスのテーブルを使って Model を定義することで、それを元にリバース ETLの設定(データウェアハウスからアプリへの ETL の設定)を行うことができる。
つまり、データエンジニアは、データウェアハウス内にテーブルを用意するだけで済むようになる。あとはデータ利用者が良しなに活用してくれる。必死に各社 SaaS の API 使用を調べて実装する必要はない。Forward ETL の設定は、データ利用者が設定する動機がなさそうなので、データエンジニアがオーナーになるかもしれない。しかし、理想的にはデータエンジニアはデータウェアハウスへのインプットおよびアウトプット処理を実装せずに済むようになり、データウェアハウスの中だけで完結する世界に生きられるというわけだ(そしてそれは dbt を使うだけで十分ということだ)。
さいごに
リバースETLの概念とデータパイプラインにおけるリバース ETL の意義を紹介した。個人的には、このようなサービスが成立することが驚き(現職の Treasure Data はデータプラットフォームの一部としてそれら input/output どちらの integration も提供している)であり、嬉しくもある(データエンジニアリングの仕組みや知見にニーズがあることだと思うので)。
また、Forward ETL と Reverse ETL はひとつのサービスとして統合できないのだろうかという疑問がある(メンテコストが大きすぎるのだろうか)。
なんにせよ食いっぱぐれないようにやっていきましょう。