プロダクトをマネージしたい話
先月から某 SaaS スタートアップで Product Manager の副業をさせていただいている。
今月から副業PdMを始めたが果たしてうまくいくか
— 🐘 (@satoshihirose) July 17, 2022
本業でも最近は Product チームと一緒に働いたり、Product Management 領域の仕事をしており、その中でプロダクトをマネージすることに興味が湧いてきている。なので、これまでの経験を活かして Product Manager にトランスファーができるか少しずつ検討している(この意思決定は特段急いではいない)。
Product Manager 業を体験するのに一番早いのは、プロダクトを自分で作ることかなと思ったので、サイドプロジェクトで何か出来ないものかと考え始めている。
億万長者が身分を隠して100ドルの所持金といくつかの持ち物だけで100万ドルを稼ぐチャレンジ番組
— 最速配信研究会 山崎大輔 (@yamaz) April 15, 2022
1. いきなりビジネスをはじめず、生活費のまずは確保
2. 売るものを見つける前に買い手を先に探す
とか参考になりまくる。https://t.co/1I9gjkNc5l
プロダクトを作る前に実際に引き合いがあるかを確認するのには基本のようなので、コンサルとかで入って悩みを聞いたりするのが良いのかなと思い、まずは個人事業用のサイトを作って公開した。
まず個人サイトをnotionで作ってみて出来そうなことを書いてみた。https://t.co/XZdFZmMZTN https://t.co/NVdIv5Iqhq
— 🐘 (@satoshihirose) August 12, 2022
作るプロダクトのテーマとしてはできれば、システム運用を楽にしてひとりのエンジニアにレバレッジをかけられるようなサービスがいいかな。何か新しいことをしようとしているスタートアップは好きだし、SaaS も好き。人手が少ないそういう会社を手助けできれば嬉しい。特に自分の出自周りのクラウドインフラ、データエンジニアリングあたりに関連したもので。
コストやリソースをモニタリングできるだけじゃなくて個別機能のユースケースごとにlinterみたいなことが出来ると良いのになと思っている。自動Technical Account Manager。
— 🐘 (@satoshihirose) August 13, 2022
いまいま考えたアイディアとしては、クラウドリソースのコスト管理やアセスメントができるサービス。例えば、企業によってはAWS のリソースにタグを付けてチームごとコンポーネントごとのインフラコストを算出してコスト管理をしていたりする。きちんとルールを策定して運用できている企業ばかりではないと思うので、その運用やコスト分配の設定を楽にできたり可視化やwarningが自動でできたり、サービスの利用状況や設定を見て適切なインスタントタイプや使い方をサジェストしてくれるようなサービス。無駄なリソースや微妙な設定を見えやすくしてITや開発部の作業時間の削減とシステムコストをスリム化して良いプラクティスを適用する。ってのをAWS以外のクラウドサービスにも対応できたら嬉しそう。
作ったら買っても良いよって人がもしいたらご連絡ください。 もしくは、話を聞きたいよ、困ってることがあって相談したいよ、ってのでも良いのでご連絡ください。
勉強会でモダンデータスタックの話をした
先週、Data Engineering Study という勉強会でざっくりとモダンデータスタックの話をした。
イベント参加登録者は400人超で最大同時接続数は180くらいだったそうな。
こちら第14回 #DataEngineeringStudy の発表資料です。Overview of The Modern Data Stack / モダンデータスタック概論 - Speaker Deck https://t.co/k4GK5QQcBq
— 🐘 (@satoshihirose) June 7, 2022
感想
発表のために調査して自分も色々勉強になった。良い反響もいただけて、準備したかいがあったと感じられた。 本当は、プロダクトの紹介のみならず、実際の使用感や活用事例を含めて紹介できれば良かったのだが、そこまで調べ切ることはできなかった。
今回紹介したようなプロダクトが全てうまくいくとは思っていないけれど、その試行錯誤で得られたプラクティスはその他のプロダクトや現場の運用にも徐々に反映されていくのだろうとは思う。日本においてもデジタル化が進んでデータ活用・管理の機会が増える一方でエンジニアの供給はそこまで増えていないだろうから、ツールの進化で成果をレバレッジできるような世の中になれば良いなと思う。
Q&A
1 どうやって情報を仕入れているか?
基本的に Twitter で流れてきた意見や記事を読んでいるだけ。気になる記事の author なんかを探してフォローしたりしている。やっぱりトレンドということもありデータスタートアップ界隈で議論は活発になされている。
e.g. Modern Data Stack (@moderndatastack) | Twitter
2
リバースETLをどういう責務の組織が担うかはすごく難しいなとずっと思っている
— えさ (@0610Esa) June 8, 2022
ビジネスサイドで入れたMAツールの仕様までデータエンジニアがキャッチアップするのは大変だし、一方でデータアナリストにそのエンジニアリング要件求めるのもちょっと大変だし#DataEngineeringStudy
組織の状況によって分かれるかなと思う。DWH にデータが存在することが Reverse ETLの前提なので、データエンジニア的なロールの人がいる組織という前提ではある。
- ある程度リテラシーがある非エンジニアリング部門の人が、エンジニアの手間を減らしてデータ活用を行うために Reverse ETL を活用するケース
- データエンジニアが、データ連携の実装・運用コスト軽減のために自分でデータの用意から Reverse ETL の設定までを行うケース
1 の場合はマーケターとかが必要なデータを調べて、データエンジニアにテーブル作成までを依頼するようなフローになると思うし、2 の場合は、データエンジニアが全部自分で実装してきた処理を一部 Reverse ETL に任せるようなフローになるかな。
3
Reverse ETLしたデータをアプリケーションで使う場合、データ品質をどう担保するのかが気になります。要求される品質が高そう。 #DataEngineeringStudy
— Hiroki Uchide (@hanon52_) June 8, 2022
んー、Reverse ETL の有無にかかわらず、DWH 上のデータ品質を上げる方法を実施していく感じじゃないかしら。Reverse ETL の利用者が誤ったデータの使い方をしてしまうような場合は、ドキュメントやメタデータを充実させるなどして地道にエデュケーションするしかなさそう。
4
Reverse ETL(Data Activation)とMDMとの関連性はどう思われますか?#DataEngineeringStudy
— 業務寄りの人 (@danakamura256) June 8, 2022
MDMを意識的に組織で実践したことがないからわからないけれど、MDM的なものはDWH上で引き続き実施されて、Reverse ETL的な処理はマスターデータやファクトデータのその時々のスナップショットを同期するみたいなイメージを持っている。
5
AWS DMSのCDCはあんまりこういう時話題にならないな🥲 確かに事例少なそうだけども #DataEngineeringStudy
— 黒椅子 (@fuc6w) June 8, 2022
へーAWS DMSがCDCしてくれるの知らなかった。
AWS Database Migration Service による Change Data Capture: 前編 - public note
6
CDCをナイーブにやるとDBの中のデータを全部吸い出すことになっちゃって、データ基盤とデータソースが必要以上に結合することになっちゃう気がする
— saka1 (@saka1_p) June 8, 2022
例えばカラムを落としたり適宜ハッシュ化したりの支援機能も入ってるのかなあ #DataEngineeringStudy
調べたらとりあえず debezium は Transformation とか Filtering には対応しているっぽいですね。 Transformations :: Debezium Documentation
7
#DataEngineeringStudy 主婦だけでもなく、小さい子供持ちで保育園行かせている家庭にとっては今日はありがたい時間帯な気はしますw
— Penguin lover engineer (@kimutansk) June 8, 2022
運営の方いわく、アンケートをとったところ発表者には昼間の開催が人気の一方、参加者には夜の発表が人気だったとのこと。個人的には昼間の方が嬉しいですねー。
8
メトリック、使い捨ても多くなりがちなので、そこと集中管理するかどうかのトレードオフに悩みそうではある。それがなくなる世界を見てみたい#DataEngineeringStudy
— 阿部 昌利 (@ABE_Masatoshi) June 8, 2022
やっぱり Airbnb みたいな、かなりデータ活用が組織に広がって管理が大変になってきた大きい企業じゃないとメリットだしにくそうな感じはしますよねー。dbt で管理して活用先に Reverse ETL するくらいの形が一番運用しやすいかもですね。
組織のカルチャーを維持する方法について
背景
この前、Openness というカルチャーに関する記事を書いた。
Openness について - satoshihirose.log
組織のカルチャーについてこれまで思いを馳せることも多く、何となく考えを文章にしてすっきりしたくなったので記事にする。
組織のカルチャーとはどういうものか
自分が想定する「組織のカルチャー」ってのは、ざっくり「組織にとって好ましい振る舞いを規定することで生産性を向上させるためのもの」だ。人によってそうでない捉え方をする人もいるかもしれないが、ここでは無視する。
カルチャーは、その個別の内容に関わらず、メンバーに共通の価値観を与えることで共通のプロトコルを用意し、コミュニケーションをスムーズにするという効果がある。 組織内の多様性が求められる昨今においても、まあ人間が自分と似た人を好きになるのは避けられないので、ますますカルチャーを作って維持する重要性は大きくなっていくかもしれない。そのような性質のものであるので、強いカルチャーというのは、規範として人々の行動を変える、つまりそれにより人々の意志決定に影響を与えるものだ。 逆に言うと、それによって人々の日々の意志決定が左右されないものなら、それは組織のカルチャーではないと個人的には思う。
また、組織が大きくなるにつれ、カルチャーがどれだけ組織の生産に貢献したかROIを測ることは難しくなると思うので(探せば研究なんかは出てくるかもしれないが)、カルチャーを維持する行為は一種のカルトみたいなものだとは思う。そのような集団がどうやって形成・維持されるかってところに自分の興味が惹かれる理由があるのかもしれない。それもあり、今回の記事では、どうやって組織に合ったカルチャーを規定するかには言及せず、ただ維持するための一般的な方法について考えていく。
ちなみに、自分が初めて本物の企業文化とはこういうものなのだなと強く実感したのは AWS Japan で働いたときで、自分の考えはそこでの体験に大きく影響を受けているので悪しからず。 (更に言うと、自分は企業の経営者でもマネージャーでもなく、企業文化の研究者でもない。ここで述べる理解はただのICの感想でしかないので、それも悪しからず)
組織のカルチャーを維持する方法
組織のカルチャーを維持する方法として、「明文化する」「日常的に繰り返し言及する」「評価の軸とする」でまとめた。
明文化する
明文化されていないカルチャーは社内外関わらず参照できず、理解が進まない。人々が同じものを目指していると思える原典として、その定義が必要だ。社外に対しても公開していると採用前に候補者の心構えになるし、フィルタリングをする役割にもなるだろう。
定義は具体的すぎず、適用範囲がある程度は広くなければならない。抽象的になることで解釈の余地があるとメンバー間での議論を生む。異なる運用が発生する可能性を生むので善し悪しではあるが、そのような議論は真剣にカルチャーが捉えられていて意志決定に取り入れられている証でもあり、そこまで問題視する必要はないと思う。
キャッチーで使いやすいくらい短いエイリアスがあると良い。日常で言及しやすくなる。
日常的に繰り返し言及する
人は日常的に言及しないと忘れてしまうので、しつこいと思うくらいに日常で言及する必要がある。特にリーダーシップ層が日々繰り返し言及することが大事だ。企業の責任ある人が重要視しないものはもちろん大事にはされない。これは All Hands なんかでカルチャーを交えた個人の体験を語るでも良いと思う。
カルチャーを維持するには仕組みで担保する必要がある。大小色々考えられるが、例えば、
- オンボーディング時にカルチャーに的を絞った説明会を設ける
- マネージャー向けの研修を用意する
- カルチャーに関するノベルティを用意する(リッツカールトンのクレドカードみたいなものなど)
- カルチャーを表したSlackのスタンプを用意する
みたいなものだ。まあともかく、日常的に意識される仕組みが無いと、ただ掲げられているだけのカルチャーは形骸化してしまう。形骸化したカルチャーはそれに惹きつけられた人を落胆させるし、それはロイヤルティの低下に繋がる。
評価の軸とする
人の行動は、賞罰によって変わる。カルチャーに沿った行動を称揚することで、人の行動を変えることはまあ出来るだろう。 例えば、
- 面接時に「○○のような行動をとった時のエピソードを訊かせてください」のような質問をし評価に使う
- 定期評価時、もしくは昇格評価時に、カルチャーに沿った行動によるアチーブメントを軸に評価をつける
- カルチャーに従った行動を表彰する制度を用意する
など。もちろん程度も問題であり、評価に10%程度の影響しかなければその効果は少ないだろう。
さいごに
もうちょっと書けるかと思っていたが、こんなもんか。
カルチャーが強く表れているからと言ってすべての人が働きやすいわけではなく、そのカルチャーが自分に合うかもどうかは別問題である。ある種のカルト的な集団は合わない人には合わない。また、強いカルチャーがある組織に所属する経験がないと、その効果や機微は中々理解しにくいとも思う。
自分はそのような組織でとても働きやすかったと感じた経験があり、カルチャーの色が強そうな組織を見ると応援したくなる。IC とマネージャーとでもちろん違いはあるが、カルチャーを組織内で涵養させるためにできることは少なからずあるので、自分の気に入った組織の気に入ったカルチャーがあるならそれを大事にしたいものだ。
Openness について
"不必要なコミュニケーションを制限する"
チームトポロジーを読んでいる。
一環して、逆コンウェイの法則に従うように、つまり理想のシステムアーキテクチャに沿うように組織設計をしようと主張する本である。
チャプター2 で、不必要なコミュニケーションを制限する という節がある。
コンウェイの法則の示す重要な点は、すべてのコミュニケーションとコラボレーションがよいとは限らないということだ。したがって「チームインターフェイス」を定義し、どんな仕事には強力なコラボレーションが必要で、どんな仕事には必要ないのかという期待値を設定することが重要になる。多くの組織はいつでもコミュニケーションは多いほうがよいと考えるが、実際にはそうではない。
必要とされるのは、特定のチーム間における集中的なコミュニケーションだ。予期せぬコミュニケーションを探し、その原因に取り組むことが必要なのだ。
ソフトウェアエンジニアとしては、まあどんなインターフェイスやデータを公開するべきかをしっかり考えて API 設計するって発想はとても自然に感じる。すべてのメソッドや変数がオープンになっていると困るので、情報の流れに制限をかけて、振る舞いを制御する。そういう組織設計も経験的にまったく理にかなっているように感じられる。
一方で、その制限のついたコミュニケーションってものは、組織文化において良く尊ばれる「オープンなカルチャー」みたいなものを阻害したりしないのかな、って疑問が沸いた。その辺をどう整理して整合性をとれば良いか、今回考えたことをまとめる。
オープンなカルチャー
各社の Culture Doc からオープンネスに関する箇所を引用する。
「無私の心」の項目には、「大切な仲間をサポートするために時間を割ける。情報はオープンかつ積極的に共有できる」とあります。私たちは新しくチームに加わる仲間を心から歓迎し、存分に能力を発揮できるようにあらゆる面でサポートします。
メルカリは相互の信頼関係を大切にしています。信頼を前提にしているからこそ、情報の透明性が保たれ、組織もフラットに構築。メンバーを縛るルールも必要以上に設けていません。一人ひとりの自発的な思考や行動が、個人の成長や組織の強さにつながると信じているからです。私たちは、このカルチャーを“Trust & Openness”と呼び、メルカリらしい人と組織の理想のあり方を追求していきます。
# 率直、建設的にオープンな場で議論する 誰かがそれを既に知っていたり、同じ検討をしてたり、活用したいかも知れない。集合知のインプットを活用しやすくし、議論のアウトプットを利用しやすくし、議論の組織ROIを最大化する
Ubie Discovery カルチャーガイド (社外公開版)
As One Team チームの成果に集中しよう 人、チームに対し、オープンさを貫こう
とまあ、こんな感じだ。
オープンネスは「信頼を育み、成果を最大化するため、意志決定の過程なんかの情報を積極的に公開すること」を示していそうだ。
DACI フレームワーク
ちょっと考えて、DACI フレームワークを使って「不必要なコミュニケーション」と「オープンなカルチャー」みたいなものをつなげられそうだと思った。
DACI フレームワークは意志決定における各人の役割の決め方についてのフレームワークで、関係者を Driver / Approver / Contributors / Informed に割り当て、意志決定を円滑にするためのものだ。 (DACI フレームワークの詳細は、この記事あたりを参照ください)
たぶん、逆コンウェイの法則で整理される「不必要なコミュニケーション」は Driver / Approver / Contributors を最小減にしてコミュニケーションを減らしましょうみたいな話であり、「オープンなカルチャー」で尊ばれる積極的な情報の公開は、Informed な関係者を積極的に広げましょうという話だ。
ということで、両立は可能であるし、またどちらも同時に損なうことも可能である。組織が小さいうちはすべての人が Driver / Approver / Contributors で良いが、組織が大きくなってくるとそうもいかなくなり、誰がどこまで Informed になるかを決めなきゃ行けなくなる。それを決める仕組みが必要になるので、まあそれが Driver / Approver / Contributors は逆コンウェイの法則で、Informed はオープンなカルチャーと呼ばれる何かなんだろう。
まとめ
ソフトウェア設計のアナロジーだと、変数の隠蔽みたいなクローズな情報の発生を連想してしまってナイーブな発想をしてしまったが、ちゃんと考えるとそりゃ違うことを言っているよなという話だった。
情報を公開できる形に整えるのもコストだし、反響に応えるにもコストが掛かる。そのコストに見合うだけの何らかの価値があるとする信念が組織のカルチャーであるのでしょう。やっぱり組織が大きくなるにつれて、伝える情報を制限して混乱を招かないようにしたり人を操作したりするムーブはどうしても増えいく一方なので、オープンという価値観を重視するなら、この辺の情報公開のポリシーやメッセージングについて振り返って考え続けることは大事だ。
なるべくオープンにやっていきたいものだ。
dbt on Treasure Data with dbt-trino の動作確認をした
サマリー
- dbt-trino アダプターを使って dbt を TD で使えるか試したら動いた。
- これで dbt のエコシステムを使っていろいろ出来そう
背景
以前 dbt の presto アダプターである dbt-presto を試したが、コードに修正をしないと動かないことが分かった。
その後は特に何もしてなかったが、久しぶりに dbt 周りのコードを眺めていたときに dbt-presto がアーカイブされていることを発見し、と同時にその代替の trino アダプターである dbt-trino だと動きそうなことが分かったので試してみた。
あーdbt-trinoはauto-commitしかサポートしないっぽくてtransactionの実装落としたっぽいからTDでも動きそうだな。Drop transaction queries by hovaesco · Pull Request #30 · starburstdata/dbt-trino https://t.co/vAluUJDmgR
— 🐘 (@satoshihirose) 2022年2月26日
動作確認
インストール
以前の記事と一緒、と思ったら ImportError: cannot import name 'soft_unicode' from 'markupsafe' というエラーが出たので、とりあえず今のところは markupsafe を 2.1.0 から 2.0.1 に戻して先に進む。
$ python3 -m venv venv $ source venv/bin/activate $ pip install dbt-trino $ pip install MarkupSafe==2.0.1 $ dbt --version installed version: 1.0.1 latest version: 1.0.3 Your version of dbt is out of date! You can find instructions for upgrading here: https://docs.getdbt.com/docs/installation Plugins: - trino: 1.0.1
~/.dbt/profiles.yml を修正する。ほぼ以前の記事通りだが、dbt-trino では http_scheme でプロトコル指定できるのでそこで https を指定する。
td:
target: dev
outputs:
dev:
type: trino
method: none # optional, one of {none | ldap | kerberos}
user: <your td api key>
password: dummy
database: td-presto
host: api-presto.treasuredata.com
port: 443
schema: satoshihirose
threads: 1
http_scheme: https
プロジェクトの作成
$ dbt init sample 12:28:39 Running with dbt=1.0.1 Which database would you like to use? [1] trino (Don't see the one you want? https://docs.getdbt.com/docs/available-adapters) Enter a number: 1 12:28:41 Your new dbt project "sample" was created! For more information on how to configure the profiles.yml file, please consult the dbt documentation here: https://docs.getdbt.com/docs/configure-your-profile One more thing: Need help? Don't hesitate to reach out to us via GitHub issues or on Slack: https://community.getdbt.com/ Happy modeling!
接続テスト
$ dbt debug --profile td 12:29:42 Running with dbt=1.0.1 dbt version: 1.0.1 python version: 3.9.6 python path: /Users/satoshi.hirose/work/dbt-trino-test/venv/bin/python3.9 os info: macOS-11.2.3-x86_64-i386-64bit Using profiles.yml file at /Users/satoshi.hirose/.dbt/profiles.yml Using dbt_project.yml file at /Users/satoshi.hirose/work/dbt-trino-test/dbt_project.yml Configuration: profiles.yml file [OK found and valid] dbt_project.yml file [ERROR not found] Required dependencies: - git [OK found] Connection: host: api-presto.treasuredata.com port: 443 user: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx database: td-presto schema: satoshihirose cert: None Connection test: [OK connection ok] 0 checks failed:
dbt run の実行
作成したプロジェクトに作られた dbt_project.yml の中で、 view と指定されている箇所を table に変更してから、dbt run の実行をする。
models:
sample:
# Config indicated by + and applies to all files under models/example/
example:
+materialized: table
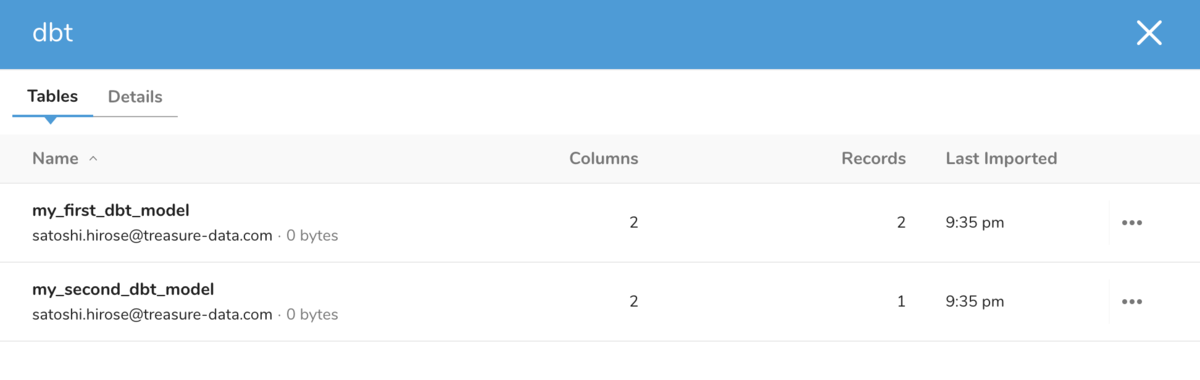
$ cd sample $ dbt run --profile td 12:35:08 Running with dbt=1.0.1 12:35:08 Unable to do partial parsing because a project config has changed 12:35:08 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics 12:35:08 12:35:13 Concurrency: 1 threads (target='dev') 12:35:13 12:35:13 1 of 2 START table model satoshihirose.my_first_dbt_model....................... [RUN] 12:35:19 1 of 2 OK created table model satoshihirose.my_first_dbt_model.................. [SUCCESS in 6.57s] 12:35:19 2 of 2 START table model satoshihirose.my_second_dbt_model...................... [RUN] 12:35:26 2 of 2 OK created table model satoshihirose.my_second_dbt_model................. [SUCCESS in 6.18s] 12:35:26 12:35:26 Finished running 2 table models in 17.31s. 12:35:26 12:35:26 Completed successfully 12:35:26 12:35:26 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
実行に成功した。UI からサンプルテーブルが作成されていることを確認できた。
Customer Reliability Engineering in Action
What's this?
Customer Reliability Engineering の方法論について考えたことをまとめる。
CREing
Google の提唱した CRE 職の新規性は、SRE の発想を自社プラットフォームのみならずその上で動く顧客アプリケーションにも適用したことにある。 基本的にはその発想に従えば良い。
SRE の方法論は、ざっくり言うと、SLA やエラーバジェットなるもので信頼性を定量的に定義しそれをモニタリングしながら改善可能性を探っていく、みたいなものだ。 それを顧客アプリケーションにも適用するのが CRE だと思えば良いだろう。
つまり、例えば現職の Treasure Data のプラットフォームには、それを取り巻く様々な顧客アプリケーションが存在する(Scheduled Query, Workflow, Source などなど)が、それらコンポーネントについて、顧客ごとまたは全体のエラー率、もしくはそれに準ずるメトリクスを計算して、それらをモニタリングしながら、改善可能性を追求していけば良い。特定の顧客の Scheduled Query のエラー率が極端に高かったら、その原因を調査し、エラーの解消に導く。原因が判明したなかで、プラットフォーム側で対応が不能な場合は、みずから顧客とコミュニケーションをとるか、カスタマーサクセスやサポートチームに協力を仰ぎ、それを解決していく。結果として、顧客側はサービスキャパシティの消費量を減らしたり気づいていない問題を発見したりアプリケーションを正常化することができ、プラットフォーム側は無駄に消費されるリソースコストを削減でき、みなハッピーというわけだ。
基本的には、適切な KPI を決めてそれを改善するという一般的な所作を顧客アプリケーションのエラー率に対してやっていきましょう、という話である。
何を改善していくか
上で述べた CRE の活動がどう実を結ぶかは、選んだメトリクスに大きく依存する。例えば、特定の顧客アプリケーションのエラーが極端に高いことを発見し、それを長時間かけて調査し人々のリソースを使って解消しようとしても、それは顧客にとってエラーが起こっていても問題ない何ら重要ではないアプリケーションかもしれない。つまりそのようなケースでは、エラー率の改善度合いは顧客へのインパクトの大きさと相関しない。
また、SRE 的な発想にこだわると改善対象のメトリックはエラー率かもしれないが、そこは所属するチームの職責やオーナーシップを持つシステム、組織のステージなどに応じて変わってくるだろう。ドキュメントシステムを改善しているなら結果 0 件リターン率がそのメトリックでも良いかもしれないし、会社 OKR が profit margin の改善なら顧客ごとの profit margin がそのメトリックでも良いかもしれない。そして、そのメトリックは一つである必要もない。対象のメトリックに何を選び、何を改善していくかを決定するかは、チームや会社の目標を元に、合意を経て決めるのが良いだろう。
具体例
以下は、現職であった事例である。
Treasure Data のサービスは、顧客のアプリケーションから Treasure Data が用意したエンドポイントに送信されたデータを、プラットフォームに蓄積する。エンドポイントはリージョンごとに存在しており、顧客アカウントは特定のリージョンに属する。
あるとき、たまたまログデータを確認していた同僚が、ある顧客が自身のアカウントの属するリージョンのエンドポイントではなく、異なるリージョンのエンドポイントに対して大量にデータを送信しているのを見つけた。 そのようなリクエストで送信されたデータは破棄されてしまい、結果としてデータは顧客アカウント上に残らない。 一日に数千万レコードが継続的に送信されつづけており、顧客アプリケーションにおいて本来蓄積されるべきそれだけの量のデータが破棄されているのも無視できなかろうということで、対策を講じようという話になった(プラットフォームにとっても意味のないリソースを消費していることになる)。
調べてみると、その他の顧客アカウントでも同様に異なるリージョンのエンドポイントにリクエストを送信していることも分かった。 はじめに、そのようなレコードがどのアカウント、リージョン、ユーザーから送信されているかを可視化してモニタリングできるダッシュボードを作成した。 そして、そのダッシュボードをカスタマーサクセスチームにシェアし、顧客とのコミュニケーション方法について相談した。 そのようなリクエストを送信している特定のユーザーに通知を送る方法も検討したが、最終的に、そのようなリクエストを送信しているアカウントのカスタマーサクセスマネージャー宛に定期的に Slack でリクエスト数などのステータスを通知し、その担当が顧客とコミュニケーションを取り削減に努めるというフローになった。 通知はリクエスト数に適当に閾値を設け自動化することで、今後にそのようなリクエストを送信するユーザーが発生したら担当メンバーまで通知が飛び、詳細をダッシュボードで確認することで顧客とコミュニケーションを取れるフローが構築できた。
以上は、スポット対応によるオペレーションフローの構築の例であり、継続的にメトリック改善施策を行っている例ではないが、ストーリーは同様なものになる思う。 この例の改善対象メトリックとは、アカウントの属するリージョンと異なるリージョンへのリクエスト数(率)だ。 メトリックが改善することで、顧客アプリケーションの瑕疵もなくなり、プラットフォームも無駄なリソース消費がなくなる。
まとめ
以上では、CRE の方法論についてまとめた。
何をしたら顧客のためになるかを考え、計測し、ひとつずつ解決していきましょう。
Superset で TD に接続できるか動作確認をした
サマリー
- Superset から TD に接続する方法として pyhive、trino-python-client、sqlalchemy-trino を試したがどれも現時点までの実装だと対応が難しそう。
- pyhive にパッチを当てることで接続でき、クエリが実行できることを確認した。
- [2022-02-08 追記] 最新の trino-python-client をインストールすることでクエリが実行できることを確認した。
Superset を localhost で動かす
こんな感じの Dockerfile を用意して、
FROM apache/superset:1.4.0
USER root
RUN superset db upgrade && \
superset init && \
superset fab create-admin \
--username superset-admin \
--password superset-admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com
build して run する。
docker build . -t superset-td-example docker run -d -p 8088:8088 superset-td-example
http://localhost:8088/ にアクセスして、Dockerfile で指定したユーザー名とパスワードを入力し、ログインできることを確認。
TD への接続確認
PyHive で動作確認
PyHive は Python から Hive/Presto に接続する際に使われる一番ポピュラーなライブラリであり、sqlalchemy の Hive/Presto dialect である。 上記の Superset の用意した docker image にもすで含まれており、デフォルトでは Hive/Presto への接続ではこれが使われる。
Superset のコンソール上から database を作成し、接続テストする。 設定はこんな感じ。<<TD_API_KEY>> は実際の API key に置換する。
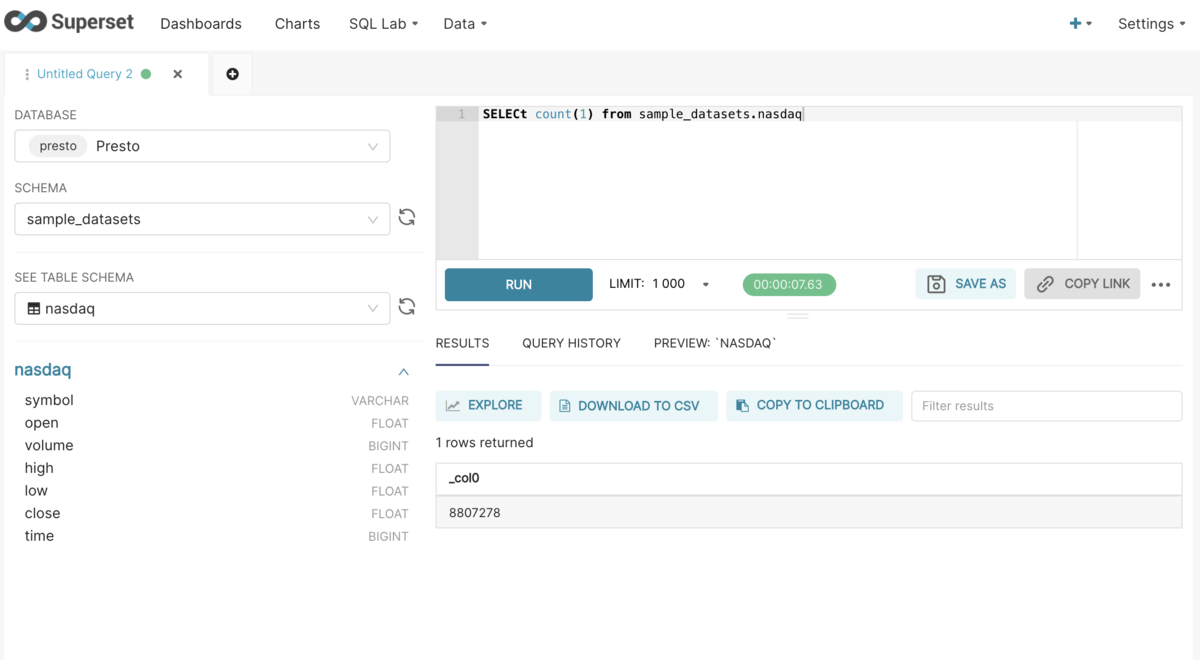
# SQLALCHEMY URI presto://api-presto.treasuredata.com/td-presto/sample_datasets
# ADVANCED > Others > ENGINE PARAMETERS
{
"connect_args": {
"username": "<<TD_API_KEY>>",
"port": 443,
"protocol": "https"
}
}
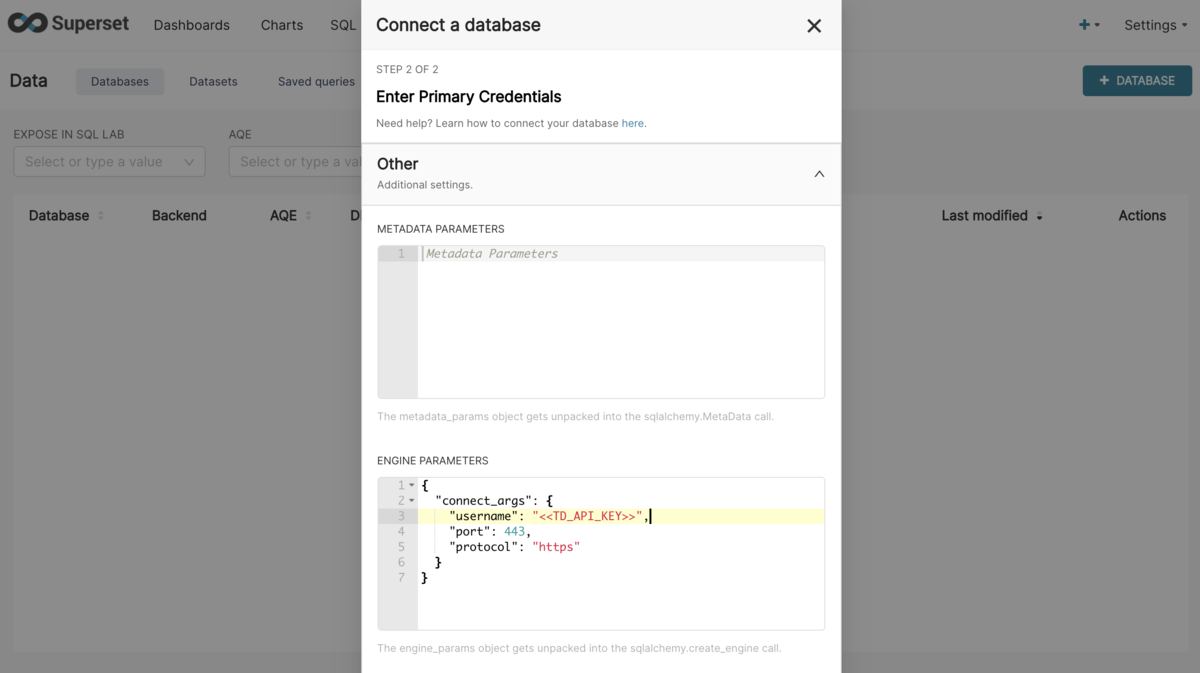
Test Connection を実行すると、Connection looks good! と表示され成功するが、 Connect を実行すると An error occurred while creating databases: Fatal error と表示され失敗する。docker のエラーログを確認すると Missing X-Presto-User header が原因であることが分かる。
sqlalchemy.exc.OperationalError: (pyhive.exc.OperationalError) Unexpected status code 401
b'{"id":"20220206_075652_49433_c4j75","infoUri":"http://not_accessible","stats":{"state":"FAILED","queued":false,"scheduled":false,"nodes":0,"totalSplits":0,"queuedSplits":0,"runningSplits":0,"completedSplits":0,"cpuTimeMillis":0,"wallTimeMillis":0,"queuedTimeMillis":0,"elapsedTimeMillis":0,"processedRows":0,"processedBytes":0,"peakMemoryBytes":0,"spilledBytes":0},"error":{"message":"Missing X-Presto-User header","sqlState":"FAILED","errorCode":4,"errorName":"PERMISSION_DENIED","errorType":"USER_ERROR","errorLocation":{"lineNumber":1,"columnNumber":1},"failureInfo":{"type":"com.treasuredata.prestobase.core.PrestobaseException","message":"[InvalidArgument] Missing X-Presto-User header","suppressed":[],
同様の Issue は PyHive に報告されており、当該 PR は close はされているが問題は解消していないようだ。
更に、今年 2022年 に入り、PyHive は unsupported であるというという明記がされてしまったため修正が取り入れられることはなさそうだ。
Mention that project is unsupported
Update README.rst by bkyryliuk · Pull Request #423 · dropbox/PyHive · GitHub
PyHive では trino の dialect もサポートしていたようだがベースは presto のものであり問題は解消されない。
trino-python-client で動作確認
trino-python-client では trino の sqlalchemy の dialect をサポートしている。 と言うことで、上記の Dockerfile に
pip uninstall -y pyhive && \ pip install trino
を追加して build & run する。 再度、Superset のコンソール上から database を作成し、接続テストする。
# SQLALCHEMY URI trino://api-presto.treasuredata.com/td-presto/sample_datasets
# ADVANCED > Others > ENGINE PARAMETERS
{
"connect_args": {
"user": "<<TD_API_KEY>>",
"port": 443,
"http_scheme": "https"
}
}
Test Connection を実行すると ERROR: line 1:8: Function 'version' not registered が表示され失敗する。
元の実装であった sqlalchemy-trino の issue を確認すると、どうやら当該 trino の dialect でサポートしている trino のバージョンは 352 以降らしい。エラーの元となっている select version(); がどこかの時点でライブラリで使用されるようになり、それをサポートしている trino が 352 以降ということのようだ。
TD のサポートする trino のバージョンは 350 が最新であり、アップグレードによる問題の解消はできない。
[2022-02-08 追記]
と twitter でつぶやいたところ、ebyhr さんに補足され、trino-python-client の修正パッチを書いていただいた!
このパッチでもSupersetとしては問題なさそうでしょうか?https://t.co/30ylmCd9Vf
— Yuya Ebihara (@ebyhr) 2022年2月7日
server_version_info: Optional[Tuple[Any, ...]] """a tuple containing a version number for the DB backend in use. This value is only available for supporting dialects, and is typically populated during the initial connection to the database. """
[https://github.com/sqlalchemy/sqlalchemy/blob/main/lib/sqlalchemy/engine/interfaces.py#L518-L522:title]
どうやら server_version_info は dialect の実装補助のための情報で、trino-python-client では使っていなく、必須ではないようだ。 ということで、
pip uninstall -y pyhive && \ pip install trino==0.310.0
みたいな感じで最新のものを使うとクエリを実行できることを確認した。Happy!
[追記ここまで]
sqlalchemy-trino で動作確認
それではと、上記の select version(); の導入前の sqlalchemy-trino を使うことで問題が解消されるか確認する。
Dockerfile の pip 実行部を trino から sqlalchemy-trino に修正して、改めて build & run する。
pip uninstall -y pyhive && \ pip install git+https://github.com/dungdm93/sqlalchemy-trino.git@d343c46b79475b577c8a1fa166dfec30112c10e3
再度 Database を作成し、Test Connection を実行すると ERROR: Access Denied: Cannot select from table runtime.nodes が表示され失敗する。
これは、TD が runtime.nodesというシステム用テーブルへのアクセスを許可していないことに起因するため、こちらも解消は厳しそうだ。
誰も心当たりのないPrestoクエリについて - PLAZMA by Treasure Data
PyHive にパッチを当てて動作確認
pyhive、trino-python-client、sqlalchemy-trino の現時点までの実装だと対応が難しそうなので、パッチを当てることで接続できるか確認する。 pyhive を fork して下記 Toru-san の PR の修正をそのまま pyhive に適用し、適当に push する。
Dockerfile の pip 実行部を下記のように修正して、再度 build & run。
pip uninstall -y pyhive && \ pip install git+https://github.com/satoshihirose/pyhive.git@develop
Superset にログインし、上記 pyhive のセクションの設定のまま Database を作成すると、成功した。
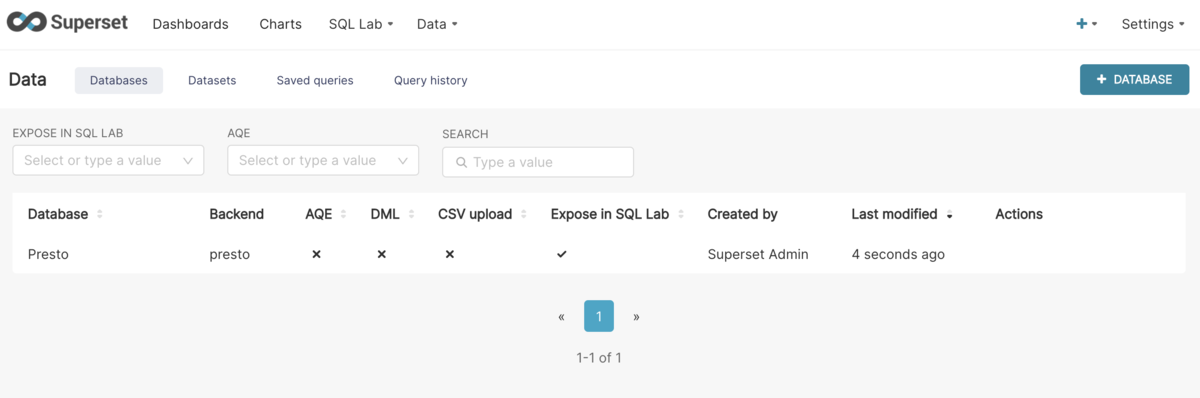
クエリエディターから実際にクエリを実行できることを確認した。