背景
基本的に情報はSNSから取得していて、特にXを利用している。最近はAI関連の論文に触れる機会を増やしていて、気になるタイトルの論文や記事は一旦はお気に入りはしているが、数も多くあらためてそれを開き直すことがなかなか億劫になってしまっている状況だった。勝手にお気に入りしたポストのリンク先の論文や記事を要約して取り掛かりやすくするような仕組みが欲しいなと思ったので作った話をまとめる。
仕組み
データ取得
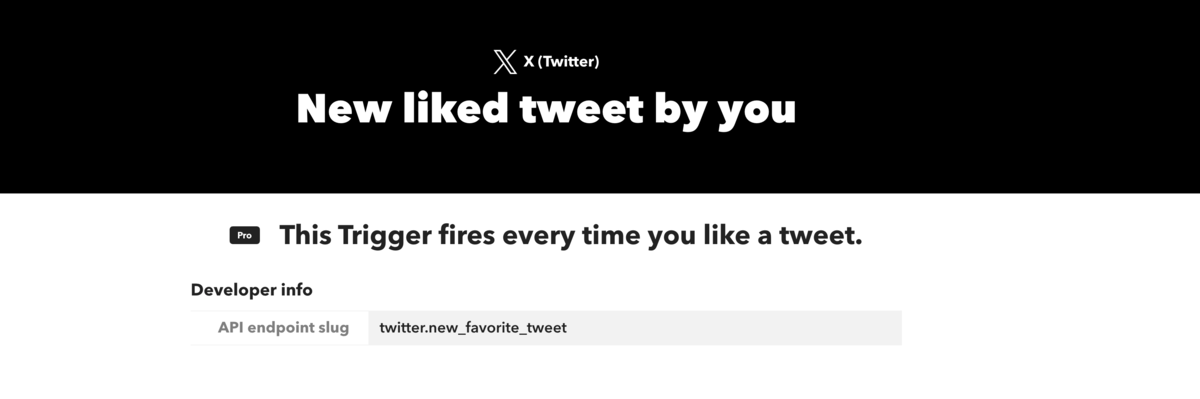
まず、Xでお気に入りした情報をAPIを使って取得しようとすると毎月のサブスクリプションが必要で $200 などかかる。
IFTTTなら月額 $2.99 でイベントドリブンな連携ができたので、それを使うことにした。
ポストをお気に入りしたイベントをトリガーにできる。
LLMの処理
取得したXのポストの情報をLLMに渡して要約させたい。ChatGPTやGeminiで試してみたが、XのURLからそのポストの内容を読み取ることはXが制限しているからかできないようだった。 ポストのテキスト情報をそのまま渡す、もしくは画面のスクリーンショットを撮って渡す、といった方法も考えたが下記のような状況も考慮したいので断念した。
- お気に入りしたポストに論文や記事のURLが含まれておらずスクリーンショットのみが含まれており、URLはそのポストへのリプライに含まれている
- お気に入りしたポストだけでなく、そのスレッドに複数連投された投稿全てを渡したい
- お気に入りしたポストだけでなく、その引用元のRTも参照させたい
Xが開発しているGrokならば上記の状況も対応できるか試したところ、ポストのURLを渡すだけで、その引用・リプライポストも勝手に情報として取得してくれていそうなので、Grokを使うことにした。
IFTTTにはカスタムコードを実行できる仕組みがなさそうなので、何かを用意する必要がある。 お金もかからないし、Google Sheetにお気に入りしたポストのデータを溜めてApps ScriptでGrokを呼び出してメールすることにした。
Apps Script
コードはLLMに適当に要件を伝えて書いてもらった。
スクリプト実行のトリガーは時間主導で5分ごとに実行する。シートの編集をトリガーにするような設定もあったが、調べたところIFTTTによる更新ではトリガーできないみたいなので断念して定期実行にした。
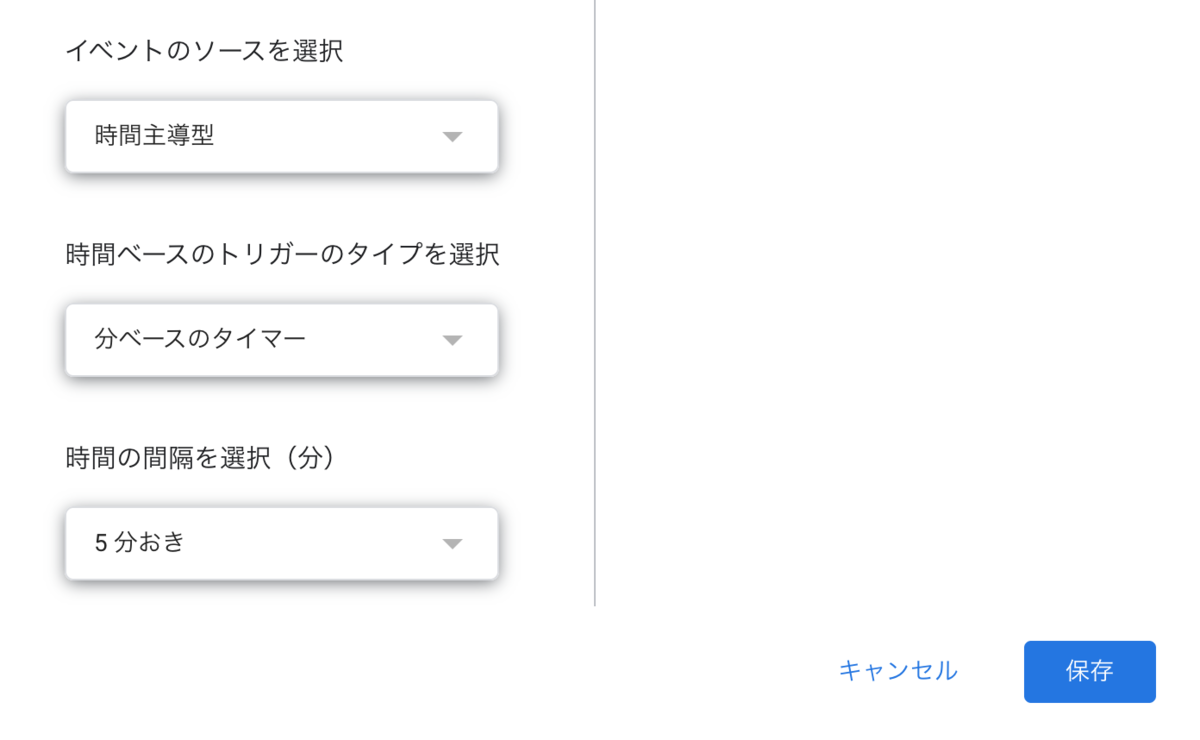
最後に処理した行を状態としてスクリプトプロパティに持たせて、定期実行で追加された行だけ処理させるようにする。
const props = PropertiesService.getScriptProperties();
const lastProcessedStr = props.getProperty(PROP_KEY_LAST_ROW);
プロンプトは適当に設定した。
const systemPrompt =
'あなたは有能なAI・LLMのResearcher・Engineerです。' +
'与えられたURLのリンク先の内容や、その周辺情報をWeb検索ツールを用いて理解し、' +
'「何が興味深い情報か」を日本語でわかりやすく要約してください。';
const userPrompt =
'次のURLはX(旧Twitter)のポストのURLです。内容を確認し、そこに含まれるリンク先の情報や周辺情報をWeb検索ツールで調べるなどして、情報を日本語でまとめてください。' +
'原文が英語だったら翻訳したものを出力に含めてください。情報全体をまとめたタイトルを出力の最初にしてくだい。一連のthreadに含まれるポストの場合は、そのURLのポストを特に取り上げてください。一連のthreadに含まれる外部URLは関連情報として出力に含めてください。YouTubeなど動画コンテンツの場合は、文字起こし情報がないか、動画をまとめた記事がないかを検索し、なければその周辺情報をまとめるだけで良いです。\n' +
'出力はURLリンクの記述方法を含めてHTML形式でお願いします。画像はHTMLで表示できるように埋め込んでください。\n' +
'URL: ' + url + '\n';
toolは、ウェブ検索とX検索を有効にして、reasoning_effortを高く設定。
const payload = {
model: XAI_MODEL_NAME,
input: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userPrompt }
],
tools: [
{ type: 'web_search' },
{ type: 'x_search' }
],
reasoning_effort: 'high'
};
Apps Script普段使わないから知らなかったけど、メール送信が簡単に実行できるのが嬉しい。
MailApp.sendEmail({
to: MY_EMAIL,
subject: subject,
body: body,
htmlBody: body
});
どんなメールになるか
結果、Xのポストをお気に入りしたら5分程度で下記のようなメールが送られてくるようになった。

元のポストはこちら
Beyond Memorization
— DailyPapers (@HuggingPapers) 2025年12月25日
Exposes popularity bias in VLMs: 34% higher accuracy on famous vs ordinary buildings, showing memorization trumps understanding. YearGuessr benchmark with 55K building images from 157 countries reveals critical reasoning flaws. pic.twitter.com/sS4FSSFWeL
最後に
これで、論文や気になった記事を読む心理的ハードルが下がって、過去に気になった記事をメールボックスで検索できるようになり、便利になった。このGrokの呼び出しセットアップだと、一回のAPI実行に10円くらいかかり、ちょっと高く感じるので、コスト削減が次の課題か。上記の方法より良いやり方があれば教えてください。
最後に気になる論文を見つけるのに参考になるXアカウントを紹介して終わりにします。





: シリコンバレー式ずけずけ言う力")



 マーケティング・インサイドセールス・営業・カスタマーサクセスの共業プロセス")




の教科書 良い市場を見つけ、ニーズを満たす製品・サービスで勝ち続ける")
")
")


")
")

")
")


")


")

")
")

")
")


:「老いない」科学の最前線 (NewsPicksパブリッシング)")

