(翻訳) データエンジニアリングビギナーズガイド 第二部
訳者まえがき
原著者の Robert Chang の許可を得て以下の記事を翻訳・公開しました。
第一部の翻訳はこちら。
以下から翻訳内容です。
データエンジニアリングビギナーズガイド 第二部 データモデリング、データパーティショニング、Airflow、ETLのベストプラクティス
 イメージクレジット:マドリード(CortesíadeIñaquiCarnicero Arquitectura)のHangar 16で改装された現代の倉庫
イメージクレジット:マドリード(CortesíadeIñaquiCarnicero Arquitectura)のHangar 16で改装された現代の倉庫
復習
データエンジニアリングビギナーズガイド 第一部では、組織の分析能力はレイヤー状に構築されることを説明しました。そして、生データの収集とデータウェアハウスの構築から機械学習の適用まで、これらの分野すべてでデータエンジニアリングが重要な役割を果たす理由を知りました。
データエンジニアの最も強く求められるスキルのひとつに、データウェアハウスの設計、構築、および保守の能力があります。そこで、データウェアハウスとは何かを明確にし、ETLという名前の由来となる抽出、変換、およびロードの3つの一般的な要素について説明しました。
ETLプロセスに馴染みがない人向けにLinkedIn、Pinterest、Spotifyなどの企業によって作られたオープンソースのフレームワークをいくつか紹介し、AirbnbのオープンソースツールのAirflowを紹介しました。最後に、データサイエンティストがSQLベースのETLパラダイムを使用することで、データエンジニアリングをはるかに効果的に学べると述べました。
第二部概要
第一部の議論はやや抽象的でした。第二部(この記事)では、優れたデータパイプラインを構築する方法に関する技術的な詳細を紹介し、ETLのベストプラクティスを見ていきます。議論では主にPython、Airflow、SQLを使用します。
まず、ビジネスメトリックとディメンションを捉えるためのテーブルスキーマとデータの関連性を注意深く定義する設計プロセスであるデータモデリングの概念を紹介します。そして、より効率的なクエリとデータのバックフィルを可能にする方法であるデータパーティショニングについて学習します。この章を終えれば、読者はデータウェアハウスとパイプライン設計の基礎を理解するでしょう。
その後の章では、Airflowジョブの詳細な構造を解説します。読者は、抽出、変換、およびロードの概念を操作するために、センサー、オペレーター、およびトランスファーをどのように使用するかを学習します。 Airbnb、Stitch Fix、Zymergenなどの実例をもとに、ETLのベストプラクティスを紹介します。
この記事の最後で、読者はAirflowの多才さとConfiguration as Codeの概念を理解するでしょう。実際、Airflowにはこれらのベストプラクティスの多くが既に組み込まれていることがわかります。
データモデリング
 イメージクレジット:スタースキーマを正しく使用すると、現実の空と同じくらい美しくなります。
イメージクレジット:スタースキーマを正しく使用すると、現実の空と同じくらい美しくなります。
あるユーザーがMediumのようなサービスを使うと、その自身のアバター、保存された投稿、閲覧回数などの情報はすべてシステムに保存されます。これらの情報を正確かつ時間通りにユーザに提供するためには、オンライントランザクション処理(OLTP)のための本番データベースを最適化することが重要です。
オンライン分析処理システム(略してOLAP)を構築する場合は、目的はかなり異なります。設計者は洞察を生むことに対して焦点を当てる必要があります。つまり、分析推論を簡単にクエリに変換し、統計を効率的に計算しなければいけません。この分析ファーストなアプローチには、データモデリングと呼ばれる設計プロセスが多くの場合に必要となります。
データモデリング、正規化、およびスタースキーマ
設計上の意思決定の例を示すために、どのテーブルを正規化するかその範囲を決定する必要性がよく発生します。一般に、正規化されたテーブルは、スキーマが単純で、標準化されたデータが多く、冗長性が少ないものです。しかし、小さなテーブルが増えると、データの関連性を追跡するには努力する必要が増え、クエリパターンはより複雑になり(JOINが増えます)、メンテナンスするETLパイプラインが増えます。
一方で、すべてのメトリックとディメンションがすでに事前結合されているような非正規化されたテーブル(別名ワイドテーブル)に問合せを行う方がはるかに簡単です。ただし、サイズが大きい場合は、ワイドテーブルのデータ処理は遅くなり、より上流の依存関係が必要となります。それに伴い、作業単位がモジュール化されず、ETLパイプラインのメンテナンスがより困難になります。
このバランスを取ろうとする数多くのデザインパターンの中で、最も一般的に使用されるパターンの一つであり、Airbnbで使用されるパターンにスタースキーマと呼ばれているものがあります。スタースキーマで編成されたテーブルは星のような型に視覚化することができるため、この名前が生まれました。この設計では、特にファクトテーブルとディメンションテーブルなどの正規化されたテーブルの構築に重点を置いています。必要に応じて、これらの小さな正規化されたテーブルから非正規化テーブルを構築することができます。この設計は、ETLの保守性と分析の容易さの両立を目指しています。
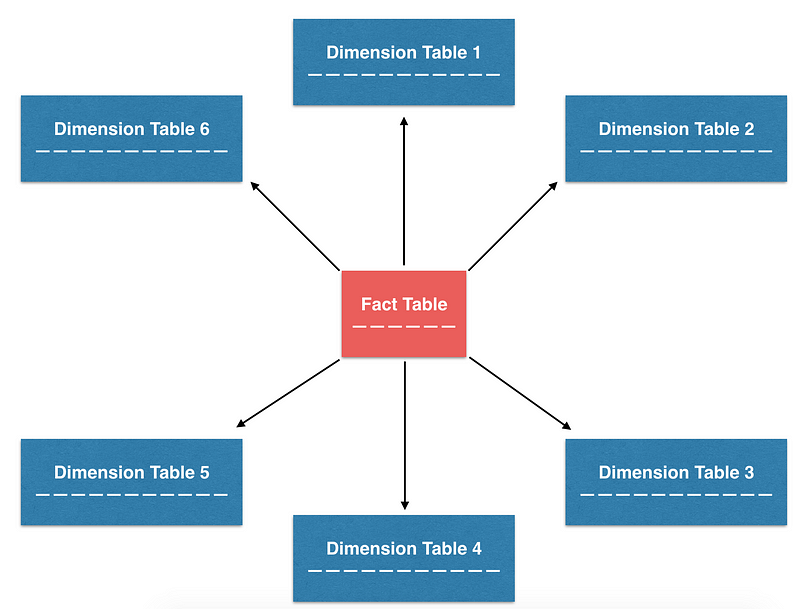 星のような型に構成されたスタースキーマは、中心にファクトテーブルがあり、ディメンションテーブルに囲まれています。
星のような型に構成されたスタースキーマは、中心にファクトテーブルがあり、ディメンションテーブルに囲まれています。
ファクトテーブルとディメンションテーブル
ファクトテーブルとディメンションテーブルから非正規化テーブルを作成する方法を理解するには、それぞれの役割についてさらに詳しく説明する必要があります。
ファクトテーブルには通常、ポイントインタイムのトランザクションデータが含まれています。テーブルの各行は非常にシンプルで、多くの場合トランザクションの単位として表されます。シンプルさのために、ビジネスメトリクスを導出するための「信頼できる唯一の情報源」となることがよくあります。たとえば、Airbnbでは、契約、予約、変更、キャンセルなどのトランザクション同様のイベントを追跡するさまざまなファクトテーブルがあります。
ディメンションテーブルは一般的には、緩やかに変化する特定のエンティティの属性を含み、その属性は階層構造で編成されることがあります。ファクトテーブルで使用可能な外部キーが存在するかぎり、これらの属性は多くの場合「ディメンション」と呼ばれ、ファクトテーブルと結合できます。 Airbnbでは、ユーザー、リスティング、マーケットなどのさまざまなディメンションテーブルを作成しており、データの分割、区分に役立っています。
以下は、ファクトテーブルとディメンションテーブル(どちらも正規化されたテーブル)を結合し、各マーケットで過去一週間に何回の予約が発生したかなどの、基本的な分析に関する質問に答える方法の簡単な例です。追加のメトリックm_a, m_b, m_cおよびディメンションdim_x, dim_y, dim_zが最後のSELECT句に投影されるとどうなるか、正規化されていない表をこれらの正規化された表から簡単に作成できることを鋭いユーザーはなら分かるでしょう。
正規化されたテーブルは、アドホックな質問への回答、もしくは非正規化テーブルの構築に使用することができます。
データのパーティショニングと履歴データのバックフィル

データストレージコストが低く、計算コストが低い時代においては、企業は過去のデータをすべて捨てるのではなく、ウェアハウスに保存する余裕があります。このようなアプローチの利点は、企業が新しい変化に対応して履歴データを適切に処理し直すことができることです。
データスタンプによるデータのパーティショニング
非常に多くのデータを安易に利用すると、クエリの実行と分析の実行は時間の経過とともに非効率になります。 「早期および頻繁にフィルタリング」、「必要なフィールドのみを射影する」などのSQLベストプラクティスに従うことに加え、クエリのパフォーマンスを向上させる最も効果的な手法の一つは、データをパーティショニングすることです。
データのパーティショニングの背後にある基本的な考え方はどちらかというと単純です。すべてのデータをひとかたまりに格納するのではなく、独立し自己充足なかたまりに分割します。同じかたまりのデータには同じパーティションキーが割り当てられます。つまり、データのサブセットを極めてすばやく検索できます。この手法で、クエリのパフォーマンスは大幅に向上します。
特に、よく使用するパーティションキーは、日付スタンプ(datestamp)(dsと略される)であり、それにはきちんとした理由があります。第一に、S3のようなデータストレージシステムでは、生データはしばしば日付スタンプによって編成され、時間によりラベルされたディレクトリに保存されます。さらに、バッチETLジョブの作業単位は通常一日です。つまり、毎日の実行ごとに新しい日付パーティションが作成されます。最後に、多くの分析に関する質問には、指定された時間範囲内で発生したイベントのカウントが含まれるため、日付スタンプによるクエリは非常に一般的なパターンです。 日付スタンプはデータパーティショニングにおけるよくある選択肢です!
dsでパーティション化されたテーブル
履歴データのバックフィル
パーティションキーとして日付スタンプを使用するもう一つの重要な利点は、データのバックフィルの容易さです。 ETLパイプラインが構築されると、メトリックとディメンションが過去にではなく未来にむかって計算されます。たびたび、過去の傾向や動きを再確認したいと思うかもしれません。そのような場合は、過去のメトリックとディメンションを計算する必要があります。この処理のことをデータのバックフィルと呼びます。
バックフィルは非常に一般的です。Hiveは動的パーティションの機能を組み込みました。これは、多数のパーティションで同じSQL操作を実行し、複数の挿入を一度に実行する機能です。動的パーティションの有用性を示すために、各マーケットにおける予約数をearliest_dsからlatest_dsまでダッシュボードにバックフィルする必要があるタスクを考えてみましょう。その際にはこのような感じにするでしょう:
上記の操作は、同じクエリを何度も実行しているが異なるパーティションで実行しているので、やや退屈です。時間範囲が広い場合、すぐに繰り返しの作業となります。ただし、動的パーティションを使用すると、この作業を一つのクエリとして大幅に簡素化できます。
SELECT句とGROUP BY句に追加されたds、WHERE句の展開された範囲におけるPARTITION(ds = '{{ds}}')からPARTITION(ds)への構文の変化に注目してください。動的パーティションの美しさは、GROUP BY dsで必要とされているのと同じ作業をすべてラップし、その結果を関連するdsごとのパーティションに一度に挿入することにあります。このクエリパターンは非常に強力で、多くのAirbnbのデータパイプラインで使用されています。後のセクションでは、Jinjaを使用してバックフィルロジックを組み込んだAirflowジョブのコントロールフローをどのように記述できるかを示します。
Airflowパイプラインの詳細

ファクトテーブル、ディメンションテーブル、日付パーティションの概念、データのバックフィルを行うことの意味について学んだので、これらの概念を具体化し、実際のAirflow ETLジョブに入れてみましょう。
Directed Acyclic Graph (DAG)の定義
以前の記事で述べたように、ETLジョブは、抽出、変換、ロードの3つの部品の上に構築されています。概念的に聞こえるほど単純かもしれませんが、現実のETLジョブは複雑で、E、T、Lタスクの大量の組み合わせから構成されています。その結果、グラフを使用して複雑なデータフローを視覚化することは多くの場合に有効です。視覚的には、グラフのノードはタスクを表し、矢印はタスクの依存関係を表します。データがタスクで一度だけ計算される必要がありその後順次進められるものの場合、グラフは方向性があり非周期的です。このため、Airflowジョブは一般に「DAG」(Directed Acyclic Graphs)と呼ばれます。
 出典:Airbnbの実験レポートフレームワーク用のDAGのスクリーンショット
出典:Airbnbの実験レポートフレームワーク用のDAGのスクリーンショット
Airflow UIに関する巧妙なデザインの一つは、コードを設定として使用して、どのユーザーもグラフビューでDAGを視覚化できるということです。データパイプラインの作成者は、タスクを可視化するためにタスク間の依存関係の構造を定義する必要があります。この仕様は、多くの場合、Airflowジョブの構造を示すDAG定義ファイルと呼ばれるファイルに記述されます。
演算子:センサー、オペレーター、およびトランスファー
DAGはデータパイプラインが実行される方法を記述する一方で、演算子はデータパイプラインが何をするかを記述します。通常、演算子には3つの大きなカテゴリがあります。
センサー:特定の時間、外部ファイル、または上流のデータソースを待機する
オペレーター:特定のアクション(たとえば、bashコマンドの実行、Pythonの関数実行、Hiveクエリの実行など)をトリガーする
トランスファー:データをある場所から別の場所に移動させる
鋭い読者は、これらの演算子のそれぞれが、前述した、抽出、変換、およびロードの各ステップにどのように対応しているのかが分かるでしょう。センサーは、一定時間が経過した後、または上流のデータソースで発生するデータが使用可能になった後に、データフローのブロックを解除します。 Airbnbでは、ほとんどのETLジョブにHiveクエリが含まれていることから、NamedHivePartitionSensorsを使用して、Hiveテーブルの最新パーティションがダウンストリーム処理に使用可能かどうかを確認することがよくありました。
オペレーターはデータの変換をトリガします。これは変換ステップに対応します。 Airflowはオープンソースなので、コントリビューターはBaseOperatorクラスをextendして、適切なカスタムオペレーターを作成できます。 Airbnbでは、HiveOperator(Hiveクエリを実行する)が使用される最も一般的なオペレーターですが、PythonOperator(Pythonスクリプトを実行するなど)やBashOperator(たとえばbashスクリプトを実行する、または思いつきのSparkジョブを実行するなど)も使用しています。ここでは可能性は無限大です!
最後に、ある場所から別の場所へデータをトランスファーする特別な演算子もあります。この演算子は、多くの場合ETLのロードステップに変換されます。 Airbnbでは、MySqlToHiveTransferまたはS3ToHiveTransferを使用する頻度はかなり高いですが、これは主にデータインフラストラクチャやデータウェアハウスの場所に強く依存します。
簡単な例
以下は、DAG定義ファイルを定義し、AirflowのDAGをインスタンス化し、上で説明したさまざまな演算子を使用してそれに対応したDAG構造を定義する方法を示す簡単な例です。
DAGがレンダリングされると、次のグラフビューが表示されます。
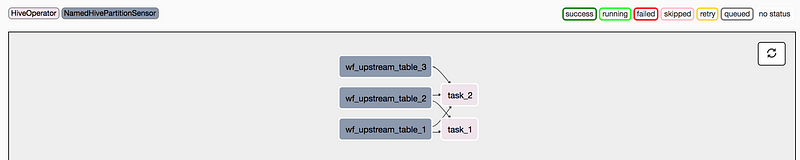
DAGのグラフビューの仮想的な例
従うべきETLのベストプラクティス

イメージクレジット:あなたの技術を磨くには練習が必要であり、そのためにはベストプラクティスに従うことが賢明です
あらゆる技術と同様に、簡潔で読みやすくスケーラブルなAirflowのジョブを書くには練習が必要です。私の最初の仕事では、ETLは私がやらなければならなかった一連の日々の機械的な仕事に過ぎませんでした。それを技術として捉えたり、ベストプラクティスを知ることをしませんでした。 Airbnbでは、ベストプラクティスについて多くのことを学び、良いETLとその美しさを理解し始めました。以下は、網羅的ではありませんが、良いETLパイプラインが従うべき原則の一覧です。
- データテーブルのパーティショニング:前述したように、データのパーティショニングは、長い履歴を持つ大規模なテーブルを処理する場合に特に役立ちます。データが日付スタンプを使用してパーティショニングされるとき、動的パーティションを活用することでバックフィルを並列化できます。
- データをインクリメンタルにロードする:この原則により、特にファクトテーブルからディメンションテーブルを作成する場合に、ETLはモジュール化し、管理しやすくなります。各実行では、ファクトテーブルの履歴全体をスキャンするのではなく、以前の日付パーティションのディメンションテーブルに新しいトランザクションを追加するだけです。
冪等性を強制する:多くのデータサイエンティストは、実績分析を実行するためにポイントインタイムスナップショットを頼ります。これは、基礎となるソーステーブルが時間の経過とともに変更可能であってはならないことを意味します。そうでなければ、異なる回答が得られることになってしまいます。同一のビジネスロジックと時間範囲に対して実行された同じクエリが同じ結果を返すように、パイプラインを構築する必要があります。この性質には、冪等性という奇抜な名前があります。
ワークフローをパラメータ化する:テンプレートがHTMLページの構成を大幅に簡略化するように、JinjaはSQLと組み合わせて使用できます。前述のように、Jinjaテンプレートの一般的な使用法の一つは、バックフィルロジックを典型的なHiveクエリに組み込むことです。Stitch Fixは、このテクニックをETLにどのように使用するかを要約したとても良い記事です。
- 早期および頻繁にデータをチェックする:データを処理する場合、ステージングテーブルにデータを書き込み、データ品質をチェックしてから、ステージングテーブルを最終的な本番テーブルと交換する方法は有用です。Airbnbでは、これをステージ・チェック・エクスチェンジのパラダイムと呼んでいます。この三ステップのパラダイムでのチェックは、重要な保護機構です。レコードの総数が0より大きい場合や、見えないカテゴリや異常値をチェックする異常検出システムなど複雑な場合に、単純なチェックが可能です。
ステージ・チェック・エクスチェンジ操作の骨組み(データパイプライン用の「ユニットテスト」とも呼ばれる)
- 有用なアラートと監視システムを構築する:ETLジョブは実行に時間がかかることが多いため、DAGの進行状況を常に監視しなくてもすむように、アラートを追加して監視すると便利です。さまざまな企業がDAGを多様で創造的な方法で監視しています。Airbnbでは、規則的にEmailOperatorsを使用して、SLAを逸したジョブのアラートメールを送信しています。他のチームは、実験の不均衡を警告するためにアラートを使用しています。もう一つの興味深い例に、ZymergenがSlackOperatorでR-squaredなどのモデルパフォーマンスメトリクスをレポートしているといったものがあります。
これらの原則の多くは、経験豊かなデータエンジニアとの会話、Airflow DAGの構築経験、Gerard ToonstraによるAirflowを使用したETLのベストプラクティスなどの全てからインスピレーションを受けています。好奇心旺盛な読者のために、私はMaximeの次のトークを強く勧めます:
出典:Airflowの原著者、Maxime、ETLベストプラクティスについて語る
第二部のまとめ
シリーズ二つ目のこの記事では、スタースキーマとデータモデリングについてさらに詳しく説明しました。ファクトテーブルとディメンションテーブルの区別を学び、特にバックフィル用に、パーティションキーとして日付スタンプを使用する利点を確認しました。さらに、Airflowジョブの詳細な構造を分析し、Airflowで利用できるさまざまな演算子を具体的に確認しました。また、ETLを構築するためのベストプラクティスを紹介し、JinjaとSlackOperatorsを組み合わせて柔軟なAirflowジョブを実行する方法を示しました。可能性は無限大です!
シリーズの最後の記事では、いくつかの先進的なデータエンジニアリングパターン、具体的には、パイプラインの構築からフレームワークの構築へどうやって移るかについて説明します。動機付けの例としてAirbnbで使用したいくつかのフレームワークの例を再び使います。
この記事が役に立った場合は、第一部をみながら第三部を楽しみにしていてください。
貴重なフィードバックを提供してくれたJason GoodmanとMichael Mussonに感謝します。