(翻訳) データエンジニアリングビギナーズガイド 最終部
訳者まえがき
原著者の Robert Chang の許可を得て以下の記事を翻訳・公開しました。
第一部と第二部の翻訳はこちら。
以下から翻訳内容です。
データエンジニアリングビギナーズガイド 最終部 ETLパイプラインからデータエンジニアリングフレームワークへ
 イメージクレジット:よく設計されたデータエンジニアリングフレームワークは、多くの扉や新しい可能性を開くことができます :)
イメージクレジット:よく設計されたデータエンジニアリングフレームワークは、多くの扉や新しい可能性を開くことができます :)
ついにフィナーレ
このシリーズの第一部では、ビジネスインテリジェンス、実験、機械学習など、分析を進める上で、堅牢なデータ基盤が重要な前提条件であることを学びました。第二部では、Airflowの詳細を深く掘り下げ、データモデリング、スタースキーマ、正規化などの技術について説明しました。さらに、データパイプラインの例を取り上げ、ETLのベストプラクティスについて学びました。これらはすべて、際立ったデータサイエンティストになるために学ぶ重要なスキルです。
通常、企業がデータ分析の階層を上って小規模なチームを拡張するにつれ、複雑さと開発コストは増加する場合が多いです。 Airbnbでは、100人以上のコントリビューターがAirflowパイプラインの作成に関っています。これにより、ETLのベストプラクティスの実施、データ品質の維持、ワークフローの標準化がますます困難になっています。幸いなことに、複雑さに対する特効薬の一つには、抽象化の力があります。もちろん、この原則はデータエンジニアリングに関しても例外ではありません。
データエンジニアリングにおいては、抽象化はユーザーのワークフローでよく見られるETLパターンの見極めと自動化を意味する場合が多いです。この最後の記事では、データエンジニアリングフレームワークの概念を定義します。このようなフレームワークを構築するための典型的なデザインパターンを分析し、最後にAirbnbで頻繁に使用する具体例をいくつか紹介します。この最後の記事の終わったところで、読者が抽象化の力を活用して独自のフレームワークを構築できるようになることを願っています。
一般的なシナリオ
あなたの会社が今、製品のそれぞれの部分を担当する複数のチームを持つ十分な大きさであるとします。各チームには、独自のOKR、製品ロードマップ、KPIがあります。あなたはチーム専属のデータサイエンティストとして、ビジネスのしくみを追跡するための分析ダッシュボードを作成する責任があります。袖をまくって働きます。
データモデリングとスキーマ設計から始めます。関連するファクトテーブルとディメンションテーブルを識別して、さまざまな有効な次元削減によって構成された意味のあるメトリックを計算します。テーブルをJOINして最終的な非正規化テーブルを作成し、最後にすべての履歴データを埋め戻します。この作業はインパクトがありますが、いくつかのダッシュボードで作業した後は、ETLワークフローは反復的になってきました。事実、あなたが会社で話す多くのデータサイエンティストは、それぞれのチームで似たワークフローを使用してダッシュボードを作成しています。
 出典:多くのETLに関する辛い仕事は、このような単純なダッシュボードに電力を供給するために必要なものです(Supersetからの参照)
出典:多くのETLに関する辛い仕事は、このような単純なダッシュボードに電力を供給するために必要なものです(Supersetからの参照)
驚くことではありませんが、製品の立ち上げの際には詳細に渡って実験をします。ユーザーレベルのメトリックを集計するために、ファクトテーブルを使用して実験に割り当てられたテーブルを慎重にJOINします。実験のp値と信頼区間を計算するために、異なる対象群からのテスト統計を計算します。いくつかの他のデータサイエンティストと話をして、これはデータサイエンティストに共通のもう一つのワークフローであることに即座に気付きました。実際、サイエンティストが日常的に行っていることの多くは、別個ではあるが一般的なワークフローに統一できるように感じられます。
これらのワークフローを(少なくとも部分的に)自動化することは可能か?と思われるでしょう。もちろん、大声で Yes と答えられます!
パイプラインからフレームワークへ
 イメージクレジット:ETLパイプラインからETLフレームワークへ
イメージクレジット:ETLパイプラインからETLフレームワークへ
第二部で既に学んだように、Airflow DAGは恣意的に複雑にすることができます。場合によっては、データの計算は制御フローのようなロジックに従うこともあります。たとえば、特定の条件付きチェックの後にデータフローを分岐する場合は、BranchPythonOperatorを使います。条件が満たされた場合にのみワークフローを続行したい場合は、ShortCircuitOpeartorを使用できます。これらの演算子は、Configuration as Codeの原則と組み合わされて、Airflow ETLを多目的かつ柔軟にするものです。しかし、Airflowはさらに多くのことをすることができます。
これまでの議論は、単一の独立したパイプラインの設計に限られていましたが、パイプライン生成にも同じ原則を適用することができます。プログラムで動的にDAGを生成する方法です。これは、基本的にデータエンジニアリングフレームワークが行うことです。それはデータワークフローを自動化するAirflow DAGに対する異なるインスタンス化の方法です。 Airflowの原著者であるMaximeがこの記事について説明しています。
コードからワークフローを動的に構築する...ひとつの非常に簡単な例は、テーブル名のリストを持つYAML設定ファイルを読み込み、各テーブルの小さなワークフローを作成し、ターゲットデータベースにテーブルをロードしたり、サンプリング、データ保存などの設定ファイルのルールを適用したり、匿名化したりする Airflowスクリプトです。この抽象化により、多くの作業をせずに新しいワークフローを作成できます。この種のアプローチには、多くのユースケースがあることがわかります。
これらのツールは、重要です。なぜなら、データサイエンティストがデータバリューチェーンをはるかに迅速に進めることができるからです。
実験報告フレームワークがユーザーレベルのメトリックを自動生成し、実験の統計を計算すると、データサイエンティストは、主要なメトリックの変化分析、ユーザーの行動解釈、製品変更の影響をハイライトするために多くの時間を費やすことができることを想像してください。
同様に、メトリックフレームワークが自動的にOLAPテーブルを自動的に生成する場合、データサイエンティストは傾向の把握、ギャップの特定、およびビジネス変更にともなう製品変更の橋渡しに多くの時間を費やすことができます。
もう一つの例は、オフラインバッチMLモデルの本番化に必要なエンジニアリング作業を抽象化するフレームワークです。データサイエンティストは、パッケージの依存関係、仮想環境の設定、またはデプロイについて心配する必要がなくなりました。代わりにモデリングに時間を費やすことができます。
これらのフレームワークの意味は、データサイエンティストの働き方を大幅に改善するため、意義深いものです。これらは、データサイエンティストが大規模に価値を提供することを可能にする技術です。
データエンジニアリングフレームワークの設計パターン
有用ではあるにしろ、DEフレームワークは何もない所からは生まれません。私はAirbnbの最初のデータエンジニアに、どのようにして皆にとって非常に多くの有用なフレームワークを作り出すことができたかを尋ねました。彼の反応は次のようなものでした。「実際には魔法はありません。十分な時間を過ごすせば、自動化できるパターンが見え始めます」ワークフローとして自分の作業を見ると、新たな可能性が生じます。
どのワークフローを自動化するか考えているとき、フレームワーク設計者はエンドユーザーの体験について考える必要があります。よく設計されたデータエンジニアリングフレームワークには一般に、入力レイヤ、データ処理レイヤ、出力レイヤの3つの層があります。
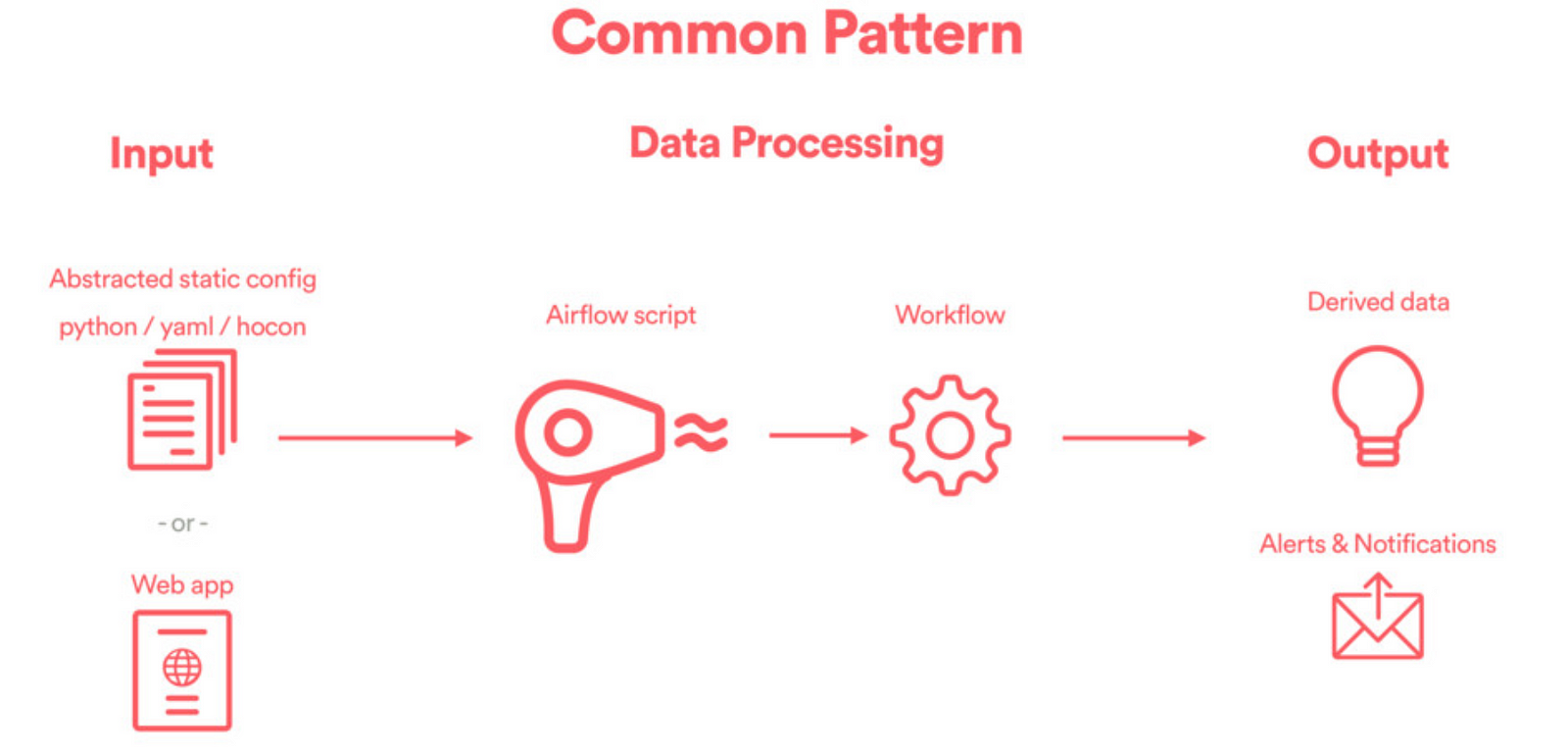 出典:ミートアップでのMaxのトーク、「Apache Airflowを使用した高度なデータエンジニアリングパターン」
出典:ミートアップでのMaxのトーク、「Apache Airflowを使用した高度なデータエンジニアリングパターン」
入力:エンドユーザーがDAGの設定方法を指定する場所です。ここではユーザー体験は重要です。通常、入力は静的な設定ファイル(YAMLやHOCONなど)でも、Web UIのようなものでもかまいません。ここでの目標は、ユーザーのニーズを把握することです。
データ処理:これは、ETLパイプラインが動的にインスタンス化されるデータエンジニアリングフレームワークの中核です。これを実現するコードは一般にDAGファクトリと呼ばれ、工場のようにDAGが一度に一つずつ作成されるという概念を酔狂で取り込んでいます。
出力:前のステップで生成されたDAGによって派生データが作成され、それは出力はしばしば下流のHiveテーブルに保存されて、適切に設計されたUI /ビジュアライゼーションレイヤーに表示されるか、下流のパイプラインまたはフレームワークで消費されます。
これはすべて抽象的に聞こえるかもしれません。したがって、今後のいくつかのセクションでは、Airbnbでこれをより具体的にするために活用する具体的な例をハイライトします。以下のセクションを読むときは、どのワークフローを各フレームワークが自動化しようとしているか、フレームワークの入出力レイヤに注意を払うことに注意してください。
1. 逐次計算フレームワーク
データサイエンティストが、最初のイベントまたは最後のイベント以降に累積した合計や時間などの計算集約型のメトリックを計算することは、とても一般的です。たとえば、新製品を使用したユーザーの総数を報告したり、ユーザーが最後に復帰してからの日数のヒストグラムを計算したいと思うでしょう。素朴なアプローチは、ファクトテーブルにクエリし、これらの望ましいメトリックを計算するために、すべての日付パーティションにわたって合計、最大、または最小値をとることです。しかし、このクエリ方法は実は非効率的です。
なぜでしょう?この方法は、必要な計算がファクトテーブル全体をスキャンするため、逐次的データ読み込みのETL原則に違反します。理想的には、これらのメトリックを事前計算するためにサマリーテーブルを作成し、エンドユーザーはサマリーテーブルの単一または最新の日付パーティション内のメトリックを参照するだけです。このパターンは、データエンジニアが逐次計算フレームワークと呼ばれるフレームワークを構築するのに、非常に一般的です。
入力:HOCON構成ファイル。ここでは、ユーザーが事前計算するメトリックまたはイベント、グループ化する主キー、サマリーテーブルを作成するためにクエリするファクトテーブルを指定します。
データ処理:サマリーテーブルを逐次的に作成するAirflowスクリプト。すなわち、当日のファクトテーブルと前の日付パーティションのサマリーテーブルを結合して、コストの大きな指標を更新します。
cumsum_metric_today = f(cumsum_metric_yesterday、metric_today)(fは合計、最小/最大、または任意の他の集約関数を含む)出力:サマリーテーブルの唯一つの日付パーティションから累積合計、最初/最後のイベント以降の日数またはその他のコストの大きなメトリックをクエリできる最適化されたサマリーテーブル。

このフレームワークはどのようなワークフローを自動化するでしょう?これは、ユーザーが非効率的なクエリパターンを回避し、使用しなければならないわずらわしい集約を一度に一つの日付パーティションへと自動化します。
2. バックフィルフレームワーク
第二部ですでに説明したように、バックフィルは、重要ですがどんなデータエンジニアリングの作業のなかでも時間のかかるステップです。 ETLパイプラインが構築されたら、履歴を再構築するために、以前のデータを遡及的に確認する必要があります。私たちが議論したバックフィル戦略の中には、ダイナミックパーティションとJinjaテンプレートを使用したSQLへのバックフィルロジックの焼き付けがあります。しかし、これらの技術を用いても、バックフィルは依然として面倒なことがあります。あるエンジニアはかつて私に「バックフィルとう単語はもう聞きたくない」と言いました。この言葉は、退屈なバックフィルがどれほど煩わしいかを教えてくれます。
たとえば、数年分のデータをバックフィルする必要がある場合、そのようなタスクを中断して小規模なバックフィルに並列化する方がはるかに効率的です。しかし、これらの長時間実行される並列プロセスを管理することは、かなり面倒なことになります。また、バックフィルされたデータを本番テーブルに挿入する前に、サニティチェックを実行する必要があることがよくあります。バックフィルが一般的だがあまりにも頻繁で不愉快な経験であることを思い、このワークフローを自動化するバックフィルフレームワークを構築しました。
入力:ユーザーがジョブ名、バックフィルジョブの
start_dateとend_date、バックフィルを並列化するプロセスの数、各プロセスがバックフィルする日数を指定できる簡単なUI。データ処理:バックフィル作業の実行方法をユーザーが指定すると、フレームワークはAirflowパイプラインを作成し、バックフィルタスクを自動的に並列化し、サニティチェックを行い、ステージングテーブルを本番テーブルと交換します。
出力:完全にバックフィルされ使用する準備が整ったテーブル。
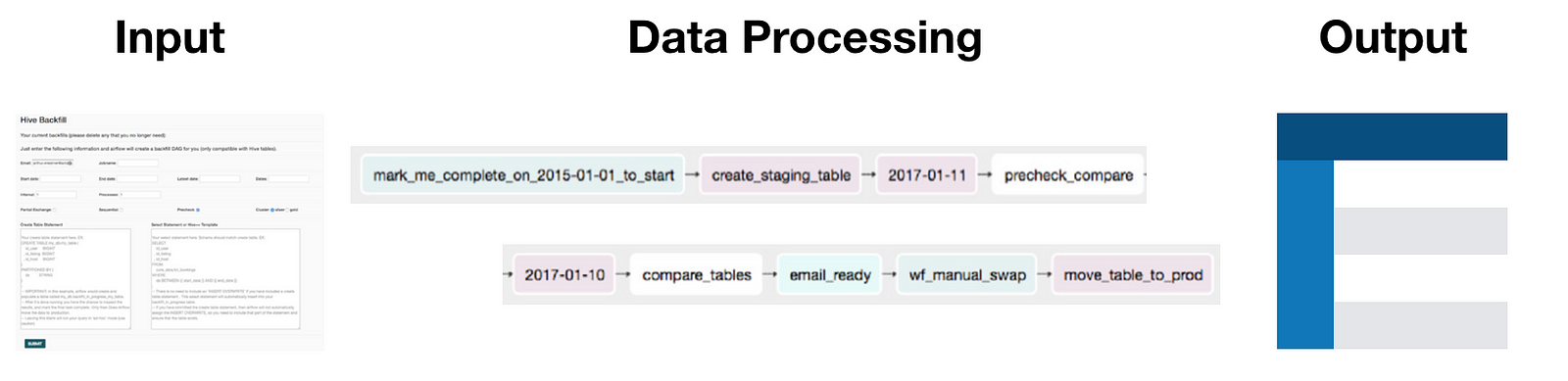
このフレームワークはどのようなワークフローを自動化するでしょう?これは、人々が自身のマシンで実行しなければならなかったアドホックなバックフィルスクリプトの多くを自動化します。自動的な比較を用意しておくことで、品質保証を自動化します。最後に、QAテスト後に、ステージングテーブルを本番テーブルと交換します。
3. グローバルメトリクスフレームワーク
最近まで、Airbnbのデータサイエンティストは、分析用のETLとダッシュボードを構築するのにかなりの時間を費やしました。前に説明したように、正しいデータソースを特定し、メトリックとディメンションを定義し、最終的な非正規化テーブルを作成するには多くの作業が必要です。異なるチームは異なるパフォーマンス指標を持つことがあります。その結果、異なるファクトテーブルが存在することもありますが、ビジネスの重要なディメンションは通常とても一貫性があり、ゆっくりと変化しています。
例えば、市場のホスト側に関する仕事をするデータサイエンティストは、通常、一覧の需要、種類、または容量などの次元削減を気にします。同様に、ゲスト側の仕事をするデータサイエンティストは、ゲストの段階、起点需要、または目的地需要などの次元を気にします。この洞察を受けて、多くのETLパイプラインで実際に多数のファクトテーブルの結合がより小さいディメンションテーブルのセットに関係していたことが明らかになりました。これが、グローバルメトリクスフレームワークの作成を動機づけた理由です。
入力:小さなファクトテーブルの一つ以上のメトリック、最終テーブルに含めることを望むディメンションの集合、結合に使用される主キーと外部キー、およびテーブルの作成を追跡するためのその他の有用な情報を指定するHOCON設定ファイル
データ処理:フレームワークは、集計およびカットするために必要なメトリックとディメンション区分を識別し、ディメンションテーブルをファクトテーブルとJOINして自動的に非正規化表を作成します。
出力:同じメトリックセットを持ち、おそらく異なるディメンションセットを持つ一つ以上のHiveテーブルが作成されます。これは、一つ以上の非正規化テーブルを即座に作成できることを意味し、これらのデータソースは、Supersetでの可視化でき、Druidでさらに活用できます。
出典:AirBnbのメトリクスフレームワークトーク、DataEngConf18 でのLauren Chircus氏
このフレームワークはどのようなワークフローを自動化するでしょう?これは、後でダッシュボードや分析などで使用する非正規化テーブルの作成に必要なよくあるデータエンジニアリング作業を自動化します。このプロジェクトのプロダクトマネージャーはそれを「非正規化マシン」と呼びました。
4. 実験報告フレームワーク
データ駆動型テクノロジー企業の多くは独自の組織内実験プラットフォームを構築しており、Airbnbも例外ではありません。私がTwitterで同様のチームに取り組んでいたことを考えると、実験パイプラインの複雑なETLがどのくらい複雑なのかを理解することができます。多くの場合、それぞれ数千のタスクで構成されたいくつものモジュール式のDAGが伴います。
その複雑さにもかかわらず、私たちの実験報告フレームワークは、実際には上で述べたものと同じデザインパターンに従います。唯一の違いは、各レイヤーがこれまで述べたすべての例で説明したものよりはるかに複雑であることです。しかし、このような投資は、企業内の製品チームが何百人何千人ものデータサイエンティストを雇うことなく、数百または数千の実験を並行して実行できるため、しばしば価値があり必要となります。
入力:単純な設定ファイルや単純なUIの代わりに、成熟したUIが組み込まれているため、ユーザーは実行するテストのタイプ、追跡するターゲットまたは二次的指標、実験バケットとその相対サイズなどを指定できます。このステップでは、実験データの開始と計算に関係するものがすべて取得されます。
データ処理:各テストごとに、サブジェクトレベルのメトリックとそれに対応するディメンションを計算するメトリクスパイプライン。これらのメトリックとディメンションの完全な組み合わせは、計算を非常に複雑にするものです。実際、実験パイプラインは企業で最も複雑なETLジョブであることがよくあります。
出力:単純な出力テーブルの代わりに、このステップに関連する多くの下流処理があります。例えば、p値、信頼区間、有意性、最小検出可能な効果などの統計がここで計算されます。報告フレームワークの成熟度に応じて、ユーザーはメトリックのキャッピングや分散の削減を行うことができます。各ステップでは、最後のUIで処理される前に個別の計算が必要です。
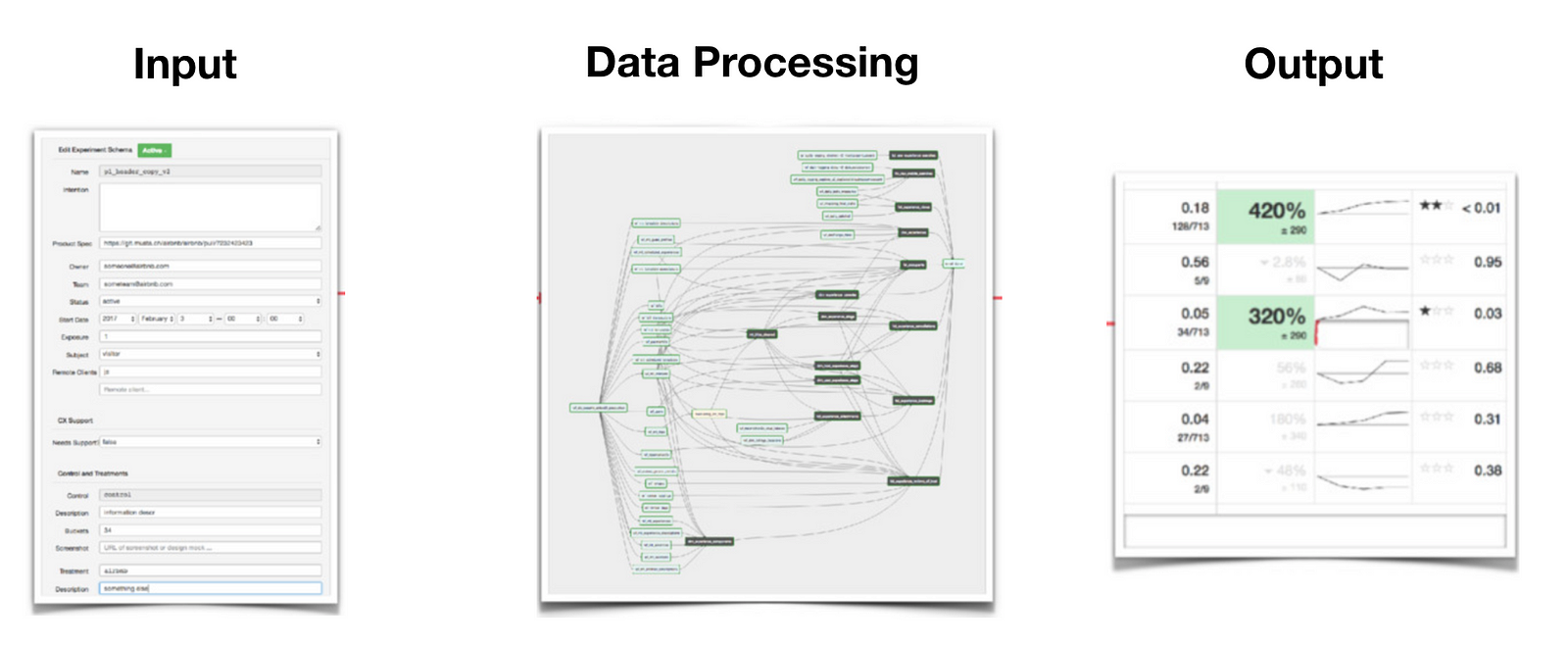
このフレームワークはどのようなワークフローを自動化するでしょう?データサイエンティストが実行しなければならないはずだった数百、数千回の実験における詳細な検証。
結論
 イメージクレジット:私たちは最終的にデータエンジニアリングトンネルの終わりまできました:)
イメージクレジット:私たちは最終的にデータエンジニアリングトンネルの終わりまできました:)
今までの議論で、DEフレームワークによる抽象化の力を理解していただければ幸いです。これらのフレームワークは、データサイエンティストの作業とワークフローに対する驚異的な増幅器です。日々の仕事のどれを抽象化することができるかを学ぶと、本当に驚くものでした。分析がレイヤー状に構築されているという哲学を強く信じるように、私はこれらのフレームワークが最初に置かれるべき基礎部分として見ています。これらのフレームワークがますます共有、議論されるにつれ、今後数年間で私たちの仕事がどのようになるかワクワクします。
これでこのシリーズも終わりです:あなたがこれまでに得たことがあるとすれば、あなたがデータエンジニアリングの基礎を学んだことをお祝いします。もっと重要なことに、読んでいただきありがとうございます。何度も言及したように、これらのアイディアのどれも私のものではありませんでしたが、今日の素晴らしいデータエンジニアリング人材からこれらの概念を学ぶのは本当に幸運なことでした。データエンジニアリングは非常に重要だがしばしば評価の低い分野、であることを考えると、私はそのために主張することで少しは役に立ったかと思います!このシリーズに興味を持ち、データエンジニアリング、特にAirflowについて学びたい場合は、これらのリソースから始めることをお勧めします。
学習を続けて、幸せなデータエンジニアリングをしていきましょう!
このシリーズのフィードバックをいただいた友人Jason Goodmanにもう一度感謝します。この記事の第三者の商標は、それぞれの所有者に帰属します。 Max、Arthur、Aaron、Michael、Laurenに感謝します。彼らはデータエンジニアリングに関連するすべてのことを(直接的または間接的に)教えてくれました。