サマリー
- dbt-trino アダプターを使って dbt を TD で使えるか試したら動いた。
- これで dbt のエコシステムを使っていろいろ出来そう
背景
以前 dbt の presto アダプターである dbt-presto を試したが、コードに修正をしないと動かないことが分かった。
その後は特に何もしてなかったが、久しぶりに dbt 周りのコードを眺めていたときに dbt-presto がアーカイブされていることを発見し、と同時にその代替の trino アダプターである dbt-trino だと動きそうなことが分かったので試してみた。
あーdbt-trinoはauto-commitしかサポートしないっぽくてtransactionの実装落としたっぽいからTDでも動きそうだな。Drop transaction queries by hovaesco · Pull Request #30 · starburstdata/dbt-trino https://t.co/vAluUJDmgR
— 🐘 (@satoshihirose) 2022年2月26日
動作確認
インストール
以前の記事と一緒、と思ったら ImportError: cannot import name 'soft_unicode' from 'markupsafe' というエラーが出たので、とりあえず今のところは markupsafe を 2.1.0 から 2.0.1 に戻して先に進む。
$ python3 -m venv venv $ source venv/bin/activate $ pip install dbt-trino $ pip install MarkupSafe==2.0.1 $ dbt --version installed version: 1.0.1 latest version: 1.0.3 Your version of dbt is out of date! You can find instructions for upgrading here: https://docs.getdbt.com/docs/installation Plugins: - trino: 1.0.1
~/.dbt/profiles.yml を修正する。ほぼ以前の記事通りだが、dbt-trino では http_scheme でプロトコル指定できるのでそこで https を指定する。
td:
target: dev
outputs:
dev:
type: trino
method: none # optional, one of {none | ldap | kerberos}
user: <your td api key>
password: dummy
database: td-presto
host: api-presto.treasuredata.com
port: 443
schema: satoshihirose
threads: 1
http_scheme: https
プロジェクトの作成
$ dbt init sample 12:28:39 Running with dbt=1.0.1 Which database would you like to use? [1] trino (Don't see the one you want? https://docs.getdbt.com/docs/available-adapters) Enter a number: 1 12:28:41 Your new dbt project "sample" was created! For more information on how to configure the profiles.yml file, please consult the dbt documentation here: https://docs.getdbt.com/docs/configure-your-profile One more thing: Need help? Don't hesitate to reach out to us via GitHub issues or on Slack: https://community.getdbt.com/ Happy modeling!
接続テスト
$ dbt debug --profile td 12:29:42 Running with dbt=1.0.1 dbt version: 1.0.1 python version: 3.9.6 python path: /Users/satoshi.hirose/work/dbt-trino-test/venv/bin/python3.9 os info: macOS-11.2.3-x86_64-i386-64bit Using profiles.yml file at /Users/satoshi.hirose/.dbt/profiles.yml Using dbt_project.yml file at /Users/satoshi.hirose/work/dbt-trino-test/dbt_project.yml Configuration: profiles.yml file [OK found and valid] dbt_project.yml file [ERROR not found] Required dependencies: - git [OK found] Connection: host: api-presto.treasuredata.com port: 443 user: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx database: td-presto schema: satoshihirose cert: None Connection test: [OK connection ok] 0 checks failed:
dbt run の実行
作成したプロジェクトに作られた dbt_project.yml の中で、 view と指定されている箇所を table に変更してから、dbt run の実行をする。
models:
sample:
# Config indicated by + and applies to all files under models/example/
example:
+materialized: table
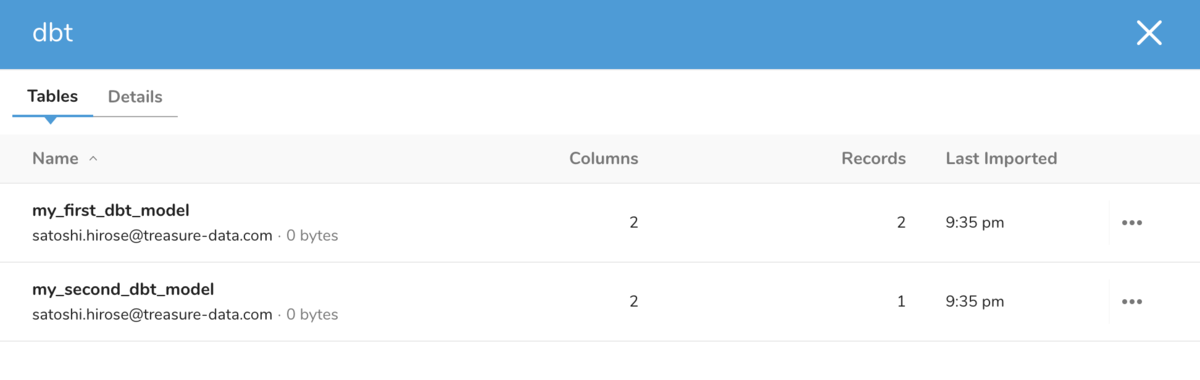
$ cd sample $ dbt run --profile td 12:35:08 Running with dbt=1.0.1 12:35:08 Unable to do partial parsing because a project config has changed 12:35:08 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics 12:35:08 12:35:13 Concurrency: 1 threads (target='dev') 12:35:13 12:35:13 1 of 2 START table model satoshihirose.my_first_dbt_model....................... [RUN] 12:35:19 1 of 2 OK created table model satoshihirose.my_first_dbt_model.................. [SUCCESS in 6.57s] 12:35:19 2 of 2 START table model satoshihirose.my_second_dbt_model...................... [RUN] 12:35:26 2 of 2 OK created table model satoshihirose.my_second_dbt_model................. [SUCCESS in 6.18s] 12:35:26 12:35:26 Finished running 2 table models in 17.31s. 12:35:26 12:35:26 Completed successfully 12:35:26 12:35:26 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
実行に成功した。UI からサンプルテーブルが作成されていることを確認できた。