(翻訳) データエンジニアの始まり
訳者まえがき
原著者 Maxime Beauchemin の許可を得て以下の記事を翻訳・公開しました。
原著者は、Apache Airflow や Apache Superset のクリエーターで、現在は Lyft で Data Engineer をしています。
データエンジニアの始まり(翻訳)
私は 2011 年にBIエンジニアとしてFacebookに入社しました。2013年に退職するときには、私はデータエンジニアでした。
昇進もしくは新しい役割に就いたわけではありません。そうではなく、Facebookは、私たちが行っていた仕事が伝統的なBIを超えていたことに気づいたのです。私たち自身のために作り出した役割は、まったく新しい専門分野でした。
私のチームはこの変革の最前線にいました。私たちは新しいスキル、新しいやりかた、新しいツール開発し、そして-- たいていの場合は--これまでの手法に背を向けていました。
私たちはパイオニアであり、データエンジニアだったのです!
データエンジニアリング?
学問分野としてのデータサイエンスは自己肯定や境界を定義する青年期を経ていました。同時期に、データエンジニアリングはやや若い兄弟でしたが、同様のものを経ていました。データエンジニアリングの学問はその兄弟に習う一方で、それ自身を対称的に位置づけ、アイデンティティーを見出していました。
データサイエンティストと同じく、データエンジニアはコードを書きます。彼らは高度に分析的で、データの可視化に関心があります。
データサイエンティストと異なり--ソフトウェアエンジニアリングという円熟した両親からの触発を受け--データエンジニアはツールやインフラストラクチャチーム、フレームワークやサービスを開発します。データエンジニアリングはデータサイエンティストよりもソフトウェアエンジニアに近いとも言えるでしょう。
過去から存在してるロールに関して言うと、データエンジニアリング分野は、ソフトウェアエンジニアリングから多くを受け継いだBIやデータウェアハウスの上位集合と考えられるかもしれません。この学問は、拡張されたHadoopエコシステム、ストリーム処理、および大規模計算に関する概念とともに、いわゆる「ビッグデータ」分散システムの運用周りの専門性を統合しています。
小さな企業--データインフラストラクチャチームが正式に存在しないような--では、データエンジニアリングの役割は、組織のデータインフラの設定と運用に関する作業もカバーする場合もあります。これには Hadoop/Hive/HBase、Spark などのプラットフォームの設定や運用のようなタスクも含まれます。
小規模な環境では、人々はAmazonやDatabricksなどが提供するホスティングサービスを使用する、もしくはClouderaやHortonworksなどの企業からのサポートを受ける傾向にあります--基本的にはデータエンジニアリングの役割を他の企業に委託します。
大規模な環境では、データインフラストラクチャチームの必要性が高まるにつれて、このワークロードを管理するための専門化と正式な役割の作成が行われる傾向があります。これらの組織では、データエンジニアリングのプロセスの一部を自動化する役割は、データエンジニアリングチームとデータインフラストラクチャチームどちらともに委ねられており、これらのチームはより高いレベルの問題を解決するために協力することが一般的です。
その役割におけるエンジニアリングの側面は領域を拡大していますが、元のビジネスエンジニアリングの役割における他の側面は二次的になものとなっています。レポートやダッシュボードについてのポートフォリオの制作やメンテナンスなどの領域は、データエンジニアの主要な焦点ではありません。
現在私たちは、アナリストやデータサイエンティスト、一般的な「情報労働者」がデータに親しみ自律的にデータ消費を処理することの可能な優れたセルフサービスツールを持っています。
ETLの変革
私たちは、ドラッグ・アンド・ドロップ ETL(Extract Transform and Load)ツールから、よりプログラミング可能な方式への移り変わりも見てきました。Informatica, IBM Datastage, Cognos, AbInitio もしくは Microsoft SSIS などプラットフォームの製品知識は、現代のデータエンジニアの間では共有されておらず、Airflow, Oozie, Azkabhan, Luigi のような、プログラミング可能もしくは設定駆動なプラットフォームの理解とともに、より一般的なソフトウェアエンジニアリング技術により置き換えられています。
何故ドラッグ・アンド・ドロップツールを使用して複雑なソフトウェアのピースが開発されない理由は多数あります。それは、最終的にはコードがソフトウェアのための最良の抽象であるということです。このトピックで議論することは本記事の範囲を超えますが、その他のソフトウェアに当てはまるように、同様の理由が ETL を書くことにも当てはまると推測するのは簡単です。コードは、任意のレベルの抽象化を可能にし、慣れた方法で全ての論理操作ができ、ソース管理と上手く統合し、バージョン管理や共同作業も容易に行えます。ETLツールがグラフィカルインターフェースを触れさせるように進化したという事実は、データ処理の歴史における回り道のようなものであり、確かにそれ独自で興味深いブログ記事になるでしょう。
従来のETLツールによって公開された抽象化が的外れであるという事実を強調しましょう。もちろん、データ処理や演算処理、記憶装置の複雑さを抽象化する必要があります。しかし、解決策は ETL の基礎(ソース/ターゲット、集約、フィルタリングなど)をドラッグ・アンド・ドロップ方式で公開することではないと私は主張します。
例えば、現代のデータ環境で必要とされる抽象化の例として、A/B テストフレームワークにおける検証の構造があります。全ての試行は?関連している手法は何?どんな割合のユーザに公開する?各検証で影響がある期待される指標は何?いつその検証は効果を発揮しする?この例では、私たちは正確で高水準のインプットを受け取り、複雑な統計学的計算を実行し、計算結果をもたらすフレームワークを用います。私たちは新規の検証のためのエントリを追加することで余分な計算と結果を得られることを期待します。この例で注意する重要なことは、この抽象化のインプットパラメータは従来の ETL ツールにより提供されるものではなく、ドラッグ・アンド・ドロップインターフェースでそのような抽象化を行うのは、扱いやすくはありません。
現代のデータエンジニアにとっては、ロジックがコードにより表現出来ないため、従来の ETL ツールは大抵の場合使われません。結果として、必要な抽象化はそれらのツールで直感的に表現することは出来ません。現在、データエンジニアの役割は主に ETL を定義することからなり、完全に新しいツールセットや手法が必要とされていることは現在認識されており、それこそがその学問を根本から再構築させると言えるでしょう。新しいスタック、新しいツール、新しい制約、そして多くの場合、新しい個人の世代です。
データモデリングの変革
スタースキーマのような典型的なデータモデリングの技術は、一般的にデータウェアハウスに紐づく分析作業データモデリングに対する私たちのアプローチを定義しますが、かつてほど関連してはいません。データウェアハウスを構築するための従来のベストプラクティスは、スタックの移り変わりにより立場がなくなっています。ストレージや計算はこれまでより安価で、そして線形にスケールアウトする分散データベースの出現もあり、不足しているリソースはエンジニアリングの時間となっています。
以下は、データモデリング技術において見られる変化の一例です。
さらなる非正規化: ディメンションにおけるサロゲートキーのメンテナンスは扱いにくい可能性があり、ファクトテーブルをより読みにくくします。ファクトテーブルにおける人が判別可能なナチュラルキーやディメンションの属性の使用はより一般的になってきており、分散データベースで重く高コストなジョインの必要性を減らします。また、ParquetやORCのようなシリアライゼーションフォーマットやVerticaのようなデータベースエンジンでのエンコーディングと圧縮のサポートは、通常は非正規化に関連するパフォーマンスの損失のほとんどを埋め合わせます。これらのシステムは、独自にストレージ用のデータを正規化するようになっています。
ブロブ: 現代のデータベースはネイティブ型や関数を通じてブロブをサポートするものが多くなっています。これによりデータモデラーのプレイブックに新しい動きが生まれ、必要に応じてファクトテーブルに複数の性質のものを一度に保存できるようになります。
動的スキーマ: MapRecue の誕生以来、ドキュメントストアの普及とデータベースにおけるブロブのサポートにより、DML(訳注: DDL?)を実行することなくデータベーススキーマを発展させることが容易になりました。これにより、ウェアハウスの構築に対して反復的なアプローチを取ることが容易になり、開発が始まる前に完全なコンセンサスや買い入れを行う必要性がなくなります。
徐々に変化するディメンション(slowly changing dimension: SCD)を処理する一般的な方法として、計画的にディメンションのスナップショットを作成する(各ETLのスケジュールサイクルごとのディメンションの完全コピーは、通常は別個のテーブルパーティションに格納する)ことは、エンジニアリングの労力をほとんど必要としない単純で一般的なアプローチです。この方法は古典的アプローチと異なり、同等のETLやクエリーを書くときに容易に理解ができます。また、ディメンションの属性をファクトテーブルにて非正規化し、トランザクション発生の際にその値を追跡することは、簡単で比較的安価です。逆に、複雑なSCDモデリング手法は直感的ではなく、アクセシビリティを低下させます。
対応付けられたディメンションとメトリックのような対応付けは現代のデータ環境では依然として非常に重要です。しかしながら、データウェアハウスの迅速な移行が必要であり、多くのチームや役割がこの作業に寄与するように求められるような状況では、緊急性は高くなく、それらはトレードオフとなります。分岐によるペインポイントが手に負えなくなった箇所では、合意と収斂がバックグラウンドプロセスとして生じる場合があります。
また、より一般的には、コンピューティングサイクルのコモディティ化と、以前と比べデータに精通している人が増えているため、結果を事前に計算してウェアハウスに保存する必要性は低いと言えるでしょう。たとえば、オンデマンドでのみ実行する複雑な分析を実行できる複雑なSparkジョブを作成し、ウェアハウスの一部としてスケジュールせずにおくことが可能です。
役割と責任
データウェアハウス
データウェアハウスは、クエリと分析用に特別に構成された、トランザクションデータのコピーです。 - ラルフ・キンボール
データウェアハウスは、経営陣の意思決定プロセスを支援する、主題指向の、統合された、時系列で不揮発性のデータの集合です。 - ビル・インモン
データウェアハウスはそれまでそうだったようにただの関連性であり、データエンジニアはその構築と運用の多くの面を担当しています。データエンジニアの焦点はデータウェアハウスであり、その周りに重力を与えます。
歴史的に見たよりも現代のデータウェアハウスは公共機関のようであり、データサイエンティスト、アナリスト、ソフトウェアエンジニアがその構築と運用に参加することを歓迎しています。どのロールがそのフローを管理するかの制限を掛けるには、データは実際に会社の活動の中心に位置し過ぎているのです。これにより組織のデータニーズに合わせたスケーリングが可能になりますが、それはしばしば混沌とした安定しない不完全なインフラストラクチャをもたらします。
データエンジニアリングチームには、多くの場合、データウェアハウスにおいて高品質で公認の領域があります。たとえば、Airbnbでは、データ・エンジニアリング・チームによって管理される一連の「コア」スキーマがあります。それについて、サービス水準合意(SLA)は明確に定義・測定され、命名規則は厳格に適用されます。事業に関するメタデータとドキュメンテーションは最高品質で、関連するパイプラインコードは、よく定義されたベストプラクティスのセットに従います。
また、データエンジニアリングチームの役割は、データオブジェクトの標準やベストプラクティスおよび認証プロセスを定義することを通じて、「卓越性の中心」となることです。チームは、他のチームがデータウェアハウスのより良い市民になるのを助けるために、コアコンピテンシーを共有する教育プログラムを共にするか導くように展開できます。たとえば、Facebookには「データキャンプ」教育プログラムがあり、Airbnbはデータエンジニアがセッションをリードし、データに習熟する方法を教えるよう同様な「データ大学」プログラムを開発しています。
データエンジニアは、データウェアハウスの「図書館員」でもあり、メタデータの登録と編成を行い、ウェアハウスからファイルを抽出またはファイルごとに行う処理を定義します。急速に成長・発展しているやや混沌としたデータエコシステムにおいて、メタデータ管理とツールは現代のデータプラットフォームの重要なコンポーネントになります。
パフォーマンスのチューニングと最適化
データがこれまで以上に戦略上重要なものになるにつれて、企業はデータインフラストラクチャにとって驚異的な予算を増やしています。これにより、データエンジニアがパフォーマンスのチューニングとデータ処理とストレージの最適化を繰り返していくことがますます合理的になります。この領域で予算が縮小することはめったにないため、リソース使用量とコストの指数関数的な増加を線形化しようとする、もしくは同じ量のリソースでより多くを達成するという視点から最適化が行われることがよくあります。
データエンジニアリングスタックの複雑さが拡大していることを知ることで、そのようなスタックやプロセスの最適化における複雑さがやりがいのある課題であるがわかります。少しの労力で大きな得を得られることが簡単な場合は、通常は収穫逓減の法則が適用されます。 データエンジニアは、会社と共に規模を拡大しリソースを常に意識したインフラストラクチャを構築することは間違いありません。
データ統合
データのやりとりを通じたビジネスとシステムの統合の背後にある実践であるデータ統合は重要であり、これまで同様に課題となります。 SaaS(Software as a Service)が企業の新しい標準的な運用の方法となるにつれて、システム間で参照データを同期させる必要性がますます高まっています。 SaaSは機能するために最新のデータを必要とするだけでなく、SaaSサイドで生成されたデータをデータウェアハウスに持ち込んで、残りのデータと共に分析できるようにしたいことがあります。確かにSaaSには独自の分析機能が提供されていますが、残りのデータが提供する視点が系統的に欠けてしまうため、この一部データを引き戻す必要がある場合もあります。
これらのSaaS製品が、共通のプライマリキーを統合や共有することなく参照データを再定義することは、犠牲を払って回避すべき災害です。誰も2つの異なるシステムで2つの従業員リストまたは顧客リストを手動で維持することは望んでおらず、最悪な場合にはHRデータをウェアハウスに戻す際にファジー・マッチングを行う必要があります。
企業の経営幹部はデータ統合の課題を本当に考慮せずに、SaaSプロバイダーと契約を交わすことがあり、それは最悪の状況です。統合作業はベンダーによって販売を促進するために計画的に軽視され、データエンジニアは帳簿外の感謝されるべき仕事の下に張り付いたままになります。言うまでもなく典型的なSaaS APIはしばしば設計が不十分であり、明確に文書化されておらず、「アジャイル」(断りもなく変更されるという意味)です。
サービス
データエンジニアは抽象度の高いレベルでの運用をしており、場合によっては、データエンジニア、データサイエンティスト、アナリストが手動で行う種類の作業を自動化するためのサービスとツールを提供することを意味します。
データエンジニアとデータインフラストラクチャエンジニアが構築・運用するサービスの例をいくつか示します。
データの登録:データベースの「スクレイピング」、ログのロード、外部ストアやAPIからのデータを取得するようなサービスとツール
メトリック計算:エンゲージメント、成長率またはセグメンテーション関連のメトリックを計算して要約するためのフレームワーク
異常検出:データの消費を自動化して、異常なイベントが発生したときもしくは傾向が大きく変化したときに警告する
メタデータ管理:メタデータの生成と消費を可能にするツールにより、データウェアハウス内およびその周辺の情報を見つけやすくする
実験:A / Bテストおよび実験フレームワークは、しばしば会社の分析の重要な部分であり、重要なデータエンジニアリングコンポーネントである
計測:分析は、イベントとそのイベントに関連する属性を記録することから始まる。データエンジニアは高品質のデータが上流に取り込まれることを確実にすることに関心をおく
セッション化:ある時間の中での一連のアクションを理解するのに特化したパイプラインで、アナリストがユーザーの行動を理解できるにする
ソフトウェアエンジニアのように、データエンジニアは作業負荷を自動化し、複雑なはしごを登れるように抽象化を構築するよう常に気をつけなければなりません。自動化できるワークフローの性質は環境によって異なりますが、自動化の必要性は全面的に共通しています。
必要なスキル
SQLの熟達:英語がビジネスの言語だとしたら、SQLはデータの言語です。あなたが良い英語を話せないとしたら、ビジネスマンとして成功できるでしょうか?同世代の技術が時代遅れになる一方で、SQLはデータに関わる共通言語として未だに強力です。データエンジニアは、「相関サブクエリ」やウィンドウ関数などの手法を使用して、どんなレベルのSQLの複雑さでも表現することができます。 SQL / DML / DDLプリミティブは、データエンジニアにとって不思議なことがないほど単純です。 SQLの宣言的な性質以外にも、データベースの実行計画を読んで理解し、すべてのステップが何であるか、インデックスがどのように機能するか、さまざまなジョイン・アルゴリズム、および計画内の分散したディメンションを理解する必要があります。
データモデリング手法:データエンジニアにとって、実体関連モデルは正規化を明確に理解した上での認知的な思考様式でなければならず、非正規化とのトレードオフに対する鋭い直感をもつ必要があります。データエンジニアは、ディメンション・モデリングとそれに関連した概念やレキシカルフィールドに精通している必要があります。
ETL設計:効率的で弾力性のある「進化できる」ETLを書くことが鍵となります。私は今後のブログ記事でこのトピックを展開する予定です。
アーキテクチャーの推定:特定の専門分野の専門家と同様に、データエンジニアは、ツール、プラットフォーム、ライブラリおよびその他のリソースの大半を高いレベルで理解する必要があります。データベース、計算エンジン、ストリームプロセッサ、メッセージキュー、ワークフローオーケストラ、シリアライズフォーマット、およびその他の関連技術の異なる特色の背後にある特性やユースケースおよび細かな差異など。ソリューションを設計する際には、どのテクノロジーを使用するか良い選択ができなければならず、またどのようにそれらを連携させるかについてのビジョンを持てなければなりません。
何よりも大事なこと
過去5年間、シリコンバレーの Airbnb、Facebook、Yahoo! で働いていて Google、Netflix、Amazon、Uber、Lyft、あらゆる規模の企業数十社のデータチームと深く関わり、「データエンジニアリング」が何を進化させているかコンセンサスが増していることを観察することで、私の知見の一部を分かち合う必要があると感じました。
この記事がデータエンジニアリングのための何らかの声明の役目を果たすことができることを願っています。そして、関連分野で活動しているコミュニティからの反応を喚起することを願います!
分散システムについての学習
基本
まずはkumagi-sanのスライドを読む
www.slideshare.net
合意アルゴリズムとアプリケーション
2PC (Two Phase Commit), 3PC (Three Phase Commit)
- アルゴリズムは単純
- 2PCはFail-Recovery発生時にバグる
- 2PCではCoordinatorからのリクエストにCohortが返答しない限りブロックが発生してしまうので、ノンブロッキングな3PCが考えられた
- 3PCでは時間制限を設け、タイムアウトが発生した場合に異なるフェーズに移行する
- 余談: 翻訳: スターバックスは2フェーズコミットを使わない|Ouobpo
Paxos
ZAB (ZooKeeper Atomic Broadcast)
- Zookeeper (Google Chubbyのクローン?)
- HBaseはZookeeperを使っている
Raft
めちゃくちゃこのページがよく出来ている。アニメーションやら解説スライドなど理解への導入が素晴らしい。 https://raft.github.io/
- Consul by HashiCorp
- MongoDB by Tokutek
- etcd
- etcd/raft at master · coreos/etcd · GitHub
- DockerのCoreOSで使われている軽量KVS
- etcd総選挙を眺めてみる - Qiita
- Kudu
- CockroachDB
その他
FLP impossibility
Fail-Stop(非同期通信)より厳しい故障モデルでは「全ての壊れていないサー バが有限の時間で確実に合意に至るアルゴリズムは存在しえない」という 事を理論的に証明した論文があり、著者の頭文字を取ってその不可能性が命名されたもの
- 解説: A Brief Tour of FLP Impossibility - Paper Trail
- 元論文: https://groups.csail.mit.edu/tds/papers/Lynch/jacm85.pdf
「合意アルゴリズムは一定の時間内で必ず合意に至れる」っていうのはどこの定義か知らないけれど、Paxosだって2つのプロポーザが競合し合ったら永久に合意に至らないしRaftもリーダー変えまくれば永久にコミット進まないしFLPも「有限時間での合意は絶対保証できないよ」って言ってる。
— KUMAZAKI Hiroki (@kumagi) August 24, 2017
ちなみに上記は以下のブログ記事に対するコメント
Bitcoinは合意アルゴリズムではない – The Third of May
その他、
分散システムにおける合意問題っていうのは「合意結果は覆らない」っていう大前提があって、FLP Impossibilityも「覆らない合意のためには絶対にこういう仕組みになる」っていう前提で証明が立てられているので、bitcoinのPoWは覆る点で合意ではないしFLPも関係ない。
— KUMAZAKI Hiroki (@kumagi) August 23, 2017
CAP定理
Takeru Ohtaさんによる証明論文の抄訳がとても分かりやすい
ConsensusとQuorumの違い
- Achieving consensus means that all the participants in the discussion agree (on a proposal/result/plan etc).
- Achieving quorum means that a majority of the participants in the discussion agree.
- Therefore - if there are N participants, if all N of them agree, a consensus is achieved. If (N/2 + 1) or more participants agree, a quorum is achieved.
What is the difference between a consensus and a quorum? - Quora
中田 敦『GE 巨人の復活 シリコンバレー式「デジタル製造業」への挑戦 』を読んだ
TLで複数の人がおすすめしていたので読了した。
GE巨人の復活、読了。今年読んだ本の中で、現時点で最高の本だ。
— ところてん (@tokoroten) August 4, 2017
これは、クラウド、機械学習、IoT、リーンスタートアップ、の実践における最高の一冊。
それらが統合された、本当のデジタル社会がどのようなものかを教えてくれる。
これ、書籍名がマジで損している。 pic.twitter.com/QXxuOh9zuz
7月末でCEOを退任するイメルト氏が、製造業としてのGEを復活させ、デジタル化に挑戦した歩みは、多くの日本企業にとって参考になるものだと確信しています。是非、読んでみてください! https://t.co/PkzIr5RxpP
— Atsushi Nakada (@Nakada_itpro) July 1, 2017
個人の感想
GE巨人の復活を読了。自社の事業でドッグフーディングしながらそのノウハウをPaaSとして提供する事例はAmazonなりGoogleなり事欠かないが、それを創立125年社員数30万人の企業がトップダウンで企業カルチャーを変えながら推し進めているってのが凄まじい。
— 🐘 (@satoshihirose) August 6, 2017
全体的な書評はhido-sanの記事が参考になる。
重工産業は規模が大きいので 1 % の削減が大きなコスト圧縮になる。
燃料管理にFESを利用すれば、年間の燃料コストを最大で2%下げることができるはず。つまり、2014年に52.7億ドルの燃料を購入していたサウスウェスト航空ならば、毎年1億500万ドルの燃料経費削減の可能性があるということを示唆しています。
ビッグデータを活用した航空燃料コストの削減 | GE Reports Japan
GEは、自社の事業に適用してきた生産プロセスのデジタル化による効率化のノウハウを、PaaSとして提供することを推し進めているようだ。 しかしながら、デジタル製造業への展開の旗振り(その辣腕振りは書籍を参照)を行ったCEOイメルトは 2017/6 に退任しており、市場からは評価されていなかったようにも感じる。
イメルト氏退任、もはや「主流」でない米GEの現実 :日本経済新聞
イメルト氏の改革は成功事例として後世に残って貰いたいものである。
マイケル・ルイス「かくて行動経済学は生まれり」を読んだ
マイケル・ルイス氏のファンならば、と訳書が出たと聞いて読了した。

- 作者: マイケルルイス,Michael Lewis,渡会圭子
- 出版社/メーカー: 文藝春秋
- 発売日: 2017/07/14
- メディア: 単行本
- この商品を含むブログを見る
ダニエル・カーネマンとエイモス・トベルスキーの半生(人生)を描き、彼らが発展させた行動経済学について書かれていた。 マイケル・ルイス氏の著作はどれも対象のテーマ以上に関係者の人間ドラマが良く書かれていて読んでいて退屈しない。
ダニエル・カーネマンはファスト&スローで知っていたが、その著作は上巻で投げてしまっていた。読み始めた当時はその心理学的なアプローチが読んでいてもやもやしていて、コーナーケースを突く様な質問の結果、認知バイアスがあったとしても日常に何の影響があるんだみたいな気持ちだった気がする。けれども、この新作を読んで、彼らが明らかにしたかったことが何となくわかったような気がした。
彼らは人の判断や予測、意思決定に関わる原理について研究をしていた。人間が合理的な判断をいつも出来る気はしないが、それがどのような理由で合理から離れてしまっているかを紐解こうとしていた。本の中ではその調査に使ったアンケート用の質問も豊富に登場し、自身でその回答を行った理由を考えてみるのも面白い。確かに、自分は無意識に何らかの原則に基いて判断をしている。自分が陥りやすい認知バイアスの知識は今後の判断で役に立つこともありそうである(しかし、これも彼らが言う代表性の認知バイアスとして働きそうではある)。
彼らはイスラエルで交流を深め研究を行っていた。彼ら心理学者は戦時中の軍隊で重宝されており、彼らのような大学の教授が戦場に赴いていた事実は驚いた。人間の判断についての疑問は、人の命や国の命運に関わるような境遇から生まれた実際的なテーマであった。
これらの研究は1970年代とか大分古い話のようなので、現代にはさらに面白い研究結果が出ていそうである。
3級FP技能検定を受験した話
もういい大人なので社会制度やマニーの知識を付けようと思ったため、試験を受けた。
合格のボーダーラインが6割のところ、自己採点の結果は以下だったので、合格したでしょう。
学科: 44/60
実技: 19/20
書店で物色して下記の参考書と問題集を購入したのは Amazon によると 2016/11/24.

はじめてまなぶFP技能士3級テキスト〈’16‐’17受検対策〉
- 作者: 資格の大原FP講座
- 出版社/メーカー: 大原出版
- 発売日: 2016/06
- メディア: 単行本
- この商品を含むブログを見る

はじめてまなぶFP技能士3級問題集〈’16‐’17受検対策〉
- 作者: 資格の大原FP講座
- 出版社/メーカー: 大原出版
- 発売日: 2016/06
- メディア: 単行本
- この商品を含むブログを見る
試験日が 2017/01/22 だったので大体二ヶ月くらい。平均してそのうち半分の日数で1-2時間程度勉強したとすると総勉強時間は30-50時間程度か。 参考書を一周、問題集を二周と後は適当にザッピングした。このような試験にありがちだが、過去問と類似の問題が多いので、過去問を一通り抑えて理解すれば合格出来る(ただし問題は二択とかなのでややニッチな問題も差し込まれている印象を受けた)。2級は、3級の内容をやや強化した問題でその選択肢数が増えるだけらしいので、同様の方法で合格できそう。
3級の合格率は70%くらいある。
【FP3級は楽勝!】たった2千円の投資で一日2時間・2週間の独学で楽々と200%合格できる勉強法 - ひかる人財プロジェクト
2級になると選択問題も四択になり、合格率は35%とかになる。
FP・ファイナンシャルプランナーの合格率・難易度は? | FP・ファイナンシャルプランナーの通信教育・通信講座ならフォーサイト
自己啓発に終始した試みだったが、まあ税制などは知っておくに越したことはないだろう。 この世で避けて通れないものは死と税金である。
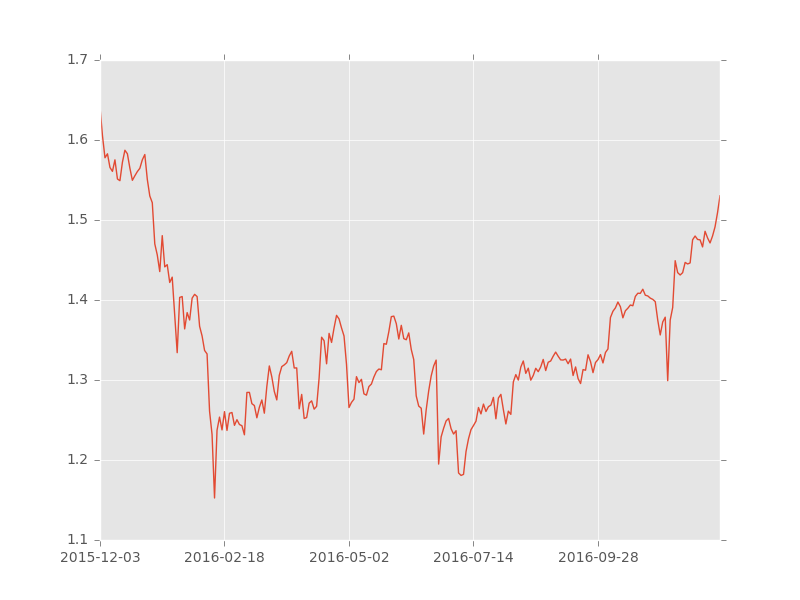
株価間倍率を確認するスクリプトを書いた
似た株や指標は似た動きをすることが多いので、その価格差が生まれた時を狙って取引をする手法があり、それは裁定取引の一種です。特に、日経平均とTOPIXの倍率を指してNT倍率と呼んだりします。
今日のレンジ展望 相場見通しとここまでの市況。 個人投資家の相場観をサポート
各種株価間の倍率(これ何か呼び名はあるのだろうか)を確認しようと思いスクリプトを書きました。株価データは 株価データサイト k-db.com から取得しています(もっと良い方法あるだろうか)。
PythonとかPandasに慣れていなく雑です。
データダウンロードするスクリプト
計算してプロットするスクリプト
こんなグラフが出力されます。
finch+twirlでのhtmlレスポンスの返し方
finchでtwirlのテンプレートの出力を返したかった。
Endpoint[Text.Html]って感じでレスポンスのcontent typeを指定出来そうだが、ドキュメント読んでもText.plainの例はあったのだがText.htmlの例が無く、わからなかった。
結局これで解決はした。
val helloApi: Endpoint[Response] = get("hello") { val content = html.index().toString() val res = Response() res.content = Buf.Utf8("text/html") res.contentType = typ res }
参考