(翻訳) データエンジニアリングビギナーズガイド 第一部
訳者まえがき
原著者の Robert Chang の許可を得て以下の記事を翻訳・公開しました。
原著者は、Airbnb で Data Scientist をしています。
以下から翻訳内容です。
データエンジニアリングビギナーズガイド 第一部 データエンジニアリング: データサイエンスの似た従兄弟
 イメージクレジット:IñaquiCarniceroが建築したマタデロマドリードの美しい元屠殺場/倉庫
イメージクレジット:IñaquiCarniceroが建築したマタデロマドリードの美しい元屠殺場/倉庫
記事を書いた動機
データサイエンティストとしての経験を経るほど、データエンジニアリングはデータサイエンティストのツールキットの中で最も重要かつ基礎的なスキルの1つであると確信しています。この考えは、プロジェクトや就職機会に対する評価、そして個人の職務領域の広がりの両方に当てはまります。
以前の記事では、データを価値のあるものに変換するデータサイエンティストの能力は、自社のデータ・インフラストラクチャーの段階とデータウェアハウスの成熟度と大きく関連していると指摘しました。これは、データサイエンティストが、自分のスキルが企業の段階と必要性に揃っているかを慎重に評価するために、データエンジニアリングについて十分に知っておく必要があることを意味します。さらに、私が知っている偉大なデータサイエンティストの多くはデータサイエンスに強いだけでなく、そうでなければ到達できないより大きく野心的なプロジェクトを行うための隣接する分野としてデータエンジニアリングを活用することに対して戦略的でもあります。
その重要性にもかかわらず、データエンジニアリングに対する教育は限られていました。生まれたばかりの分野であることもあり、多くの点でデータエンジニアリングの訓練を受ける唯一の実現可能な道は仕事上で学ぶことであり、時には遅すぎることもあります。私はこの科目を忍耐強く教えてくれたデータエンジニアと一緒に働いていたことは大変幸運です。しかし、誰もが同じ機会を得られるわけではありません。その結果として、私はこのビギナーズガイドを書き、そのギャップを埋めるために学んだことをまとめることにしました。
このビギナーズガイドの構成
私の議論の範囲は決して網羅的ではなく、Airflow、バッチデータ処理、およびSQL-like言語を中心にするつもりです。つまり、読者がデータエンジニアリングの基本的な理解を得るのを妨げないでしょう。この急速に成長しつつある新しい分野についてもっと学ぶために興味をそそられることを願っています。
第一部(この記事)は、高度な入門記事として作成されています。個人的な逸話と専門家の洞察を組み合わせて、データエンジニアリングが何であるか、それがなぜ難しいのか、それがどのようにしてあなたやあなたの組織が拡大するのを助けることができるのかを具体的に説明します。この記事の主な読者は、就職の機会を評価するための基礎を学ぶ必要のある野心のあるデータサイエンティスト、もしくは最初のデータチームを構築しようとしている初期段階の創業者です。
第二部は本質的な技術に関するものです。この記事は、ワークフローをプログラムで作成、スケジュール、および監視するためのAirbnbのオープンソースツールであるAirflowに焦点を当てています。具体的には、AirflowでHiveバッチ・ジョブを作成する方法、スター・スキーマなどの手法を使用してテーブルのスキーマを設計する方法、最後にETLを構築するためのベスト・プラクティスについて説明します。この記事は、データエンジニアリングスキルを磨こうとしている初期段階のデータエンジニアおよびデータエンジニアに適しています。
第三部ではこのシリーズの最後の記事となる予定しです。ここでは、高度なデータエンジニアリング・パターン、より高いレベルの抽象化、およびETLの構築をより簡単かつ効率的にする拡張フレームワークについて説明します。これらのパターンの多くは、難解な方法を学んだAirbnbの経験豊富なデータエンジニアから教えを受けたものです。これらの洞察は、ワークフローをさらに最適化しようとしている経験豊富なデータサイエンティストやデータエンジニアにとって特に役立ちます。
現在私が隣接する分野としてデータエンジニアリングを学ぶことについて影響力を持った支持者であることを考えると、数年前は正反対の意見であったことに驚くかもしれません。私が最初の職に就いていた間には動機付けや感情的な奮闘がありました。
大学院を出た私の最初の仕事
大学院を出た直後、私はワシントンポストに所属する小さなスタートアップで最初のデータサイエンティストとして雇われました。無限の願望と共に、最も洗練されたテクニックを使用して最も難解なビジネス問題に取り組むための分析に準備されたデータが提供されると確信していました。
仕事を始めてすぐ、私の主な責任は想像したほど魅力的ではないことを知りました。代わりに、私の仕事はより基礎的なものでした。自分のサイトにアクセスしたユーザーの数、各ユーザーがコンテンツの閲覧に費やした時間、およびユーザーが記事をライク、リツイートした頻度を追跡するという重要なパイプラインを維持することでした。質の高いコンテンツを無料で提供してくれる代わりに、私たちが所属する出版社に読者に関わる洞察を伝えたので、確かに重要な仕事でした。
公にはしていませんでしたが、私は近い将来にその仕事を完了させることで、ここで説明するように、次は素晴らしいデータ製品を作る仕事に移れるようになることをいつも願っていました。結局のところそれがデータサイエンティストに期待されていることだ、と自分に言い聞かせていました。チャンスが巡ってくることはなく、数ヶ月後、私は失望と共に会社を辞めました。残念なことに、私の個人的な体験は、新しい労働市場で経験の浅い初期のスタートアップ(需要側)または新米のデータサイエンティスト(供給側)に馴染みが薄い人々すべてには共感されないかもしれません。
 イメージクレジット:ETLパイプラインを一生懸命に構築している私(真ん中の青い男性)
イメージクレジット:ETLパイプラインを一生懸命に構築している私(真ん中の青い男性)
この経験の結果、私の不満は現実世界のデータプロジェクトが実際にどのように機能しているかをほとんど理解していないことに根ざしていることに気付きました。私は生データのワイルド・ウェストに放り出されました。あらかじめ処理され整頓された.csvファイルが存在する快適な土地とは程遠いものでした。それが平常状態である環境においては、私はなすすべがなく、居心地の悪さを感じていました。
多くのデータサイエンティストは、キャリアの早い段階で同様の道のりを経ていました。上級者たちは、この現実とそれに関連する課題を迅速に理解していました。私自身も、ゆっくりと徐々にこの新しい現実や仕事に適応しました。時間がたつにつれて、計装のコンセプトを発見し、マシン生成のログと奮闘し、多くのURLとタイムスタンプをパースしました。その中で最も重要なのは、SQLを学習したことです(気になっている読者用に。最初の仕事に先立ってSQLへの私の唯一触れたJennifer Widomの素晴らしいMOOCはこちら)
現在では、私は、慎重かつ思慮深く計測することが分析が主に対象としていることであることを理解しています。このタイプの基礎的作業は、生まれ続ける流行語やハイプで満たされた世界に住んでいるときには特に重要です。
分析の階層
退屈なデータサイエンスの一面とメディアが時に切り出すバラ色の描写との間に矛盾があることを指摘した多くの提唱者の中で、特にモニカ・ロガティ氏はAIを採用しようとしている企業に対して警告しました。
人工知能を欲求のピラミッドの頂点と考えてください。もちろん自己実現(AI)は素晴らしいですが、まずは食料、水、シェルター(データリテラシー、データ収集、データインフラストラクチャー)が必要です。
このフレームワークは物事を大局的に捉えさせてくれます。企業がビジネスをより効率的に最適化したり、データ製品をより賢く構築したりするには、基礎的作業のレイヤーを最初に構築する必要があります。このプロセスは、将来的に自己実現する前には食糧や水のような生存の必需品を気にすなければならないという道のりに似ています。このルールは、企業がニーズの順番の通りにデータ人材を雇うべきであることを意味します。スタートアップ企業において災害を引き起こす原因の1つに、最初のデータ人材としてデータモデリングに特化し、他のすべての前提条件である基礎レイヤーを構築する経験がほとんどない人材を雇うことがあります(私はこれを「不適当な採用順序問題」と呼んでいます)。
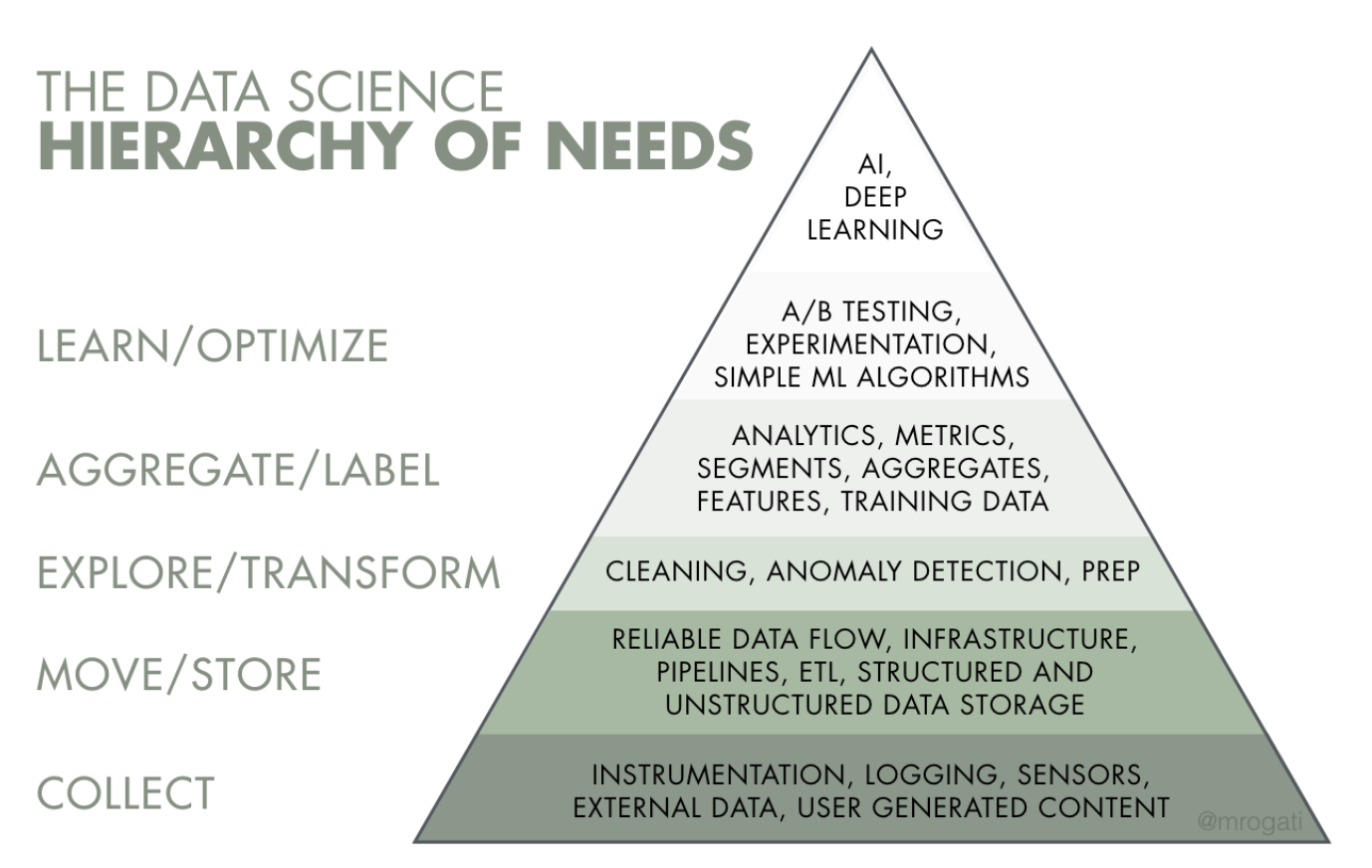 出典:モニカ・ロガティの素晴らしいミディアム上の記事「AIにおける欲求の階層」
出典:モニカ・ロガティの素晴らしいミディアム上の記事「AIにおける欲求の階層」
残念なことに、多くの企業では、既存のデータサイエンストレーニングプログラムのほとんどは学術的または専門的であり、ピラミッドの知識の頂点に集中する傾向にあることに気付きません。パブリックAPIを使用して生データをスクレイプし、用意、またはアクセスすることを学生に奨励する最新のコースでも、ほとんどの場合、テーブルスキーマを適切に設計する方法やデータパイプラインを構築する方法を学生に教えるわけではありません。その結果、現実のデータサイエンスプロジェクトの重要な要素の一部が翻訳で失われました。
幸いなことに、ソフトウェアエンジニアリングが職業としてフロントエンジニアリング、バックエンドエンジニアリング、サイト信頼性エンジニアリングに区別されているように、私たちの分野も同様により成熟したものになると予測しています。人材構成は時間が経つにつれてより専門化し、データ集約型アプリケーションの基礎を構築するスキルと経験を持つ人材が増えるでしょう。
この将来の眺望はデータサイエンティストにとって何を意味するでしょう?私は、すべてのデータサイエンティストがデータエンジニアリングの専門家になる必要があるとまでは主張はしません。しかし、私は、すべてのデータサイエンティストが、能力と問題の一致を最大化するために、プロジェクトと雇用機会を評価するために十分に基礎を知っているべきだと考えています。解決に興味のある問題の多くが更なるデータエンジニアリングスキルを必要としていることがわかったら、データエンジニアリングの学習にもっと投資するのに遅すぎることはありません。これは実際に私がAirbnbで取ったアプローチです。
データ基盤とウェアハウスの構築
データエンジニアリングを学ぶ上での目的や興味のレベルにかかわらず、データエンジニアリングが何であるかを正確に知ることが重要です。AirflowのクリエーターであるMaxime Beauchemin氏は、彼の素晴らしい記事「The Rise of Data Engineer」(訳注: 拙訳「データエンジニアの始まり」)でデータエンジニアリングを特徴づけました。
データエンジニアリング分野は、ソフトウェアエンジニアリングから多くを受け継いだBIやデータウェアハウスの上位集合と考えられるかもしれません。この学問は、拡張されたHadoopエコシステム、ストリーム処理、および大規模計算に関する概念とともに、いわゆる「ビッグデータ」分散システムの運用周りの専門性を統合しています。
データエンジニアが行うたくさんの価値ある仕事の中で、とても求められるスキルの1つは、データウェアハウスの設計、構築、および保守の能力です。小売倉庫のように消耗品がパッケージ化されて販売されているのと同様に、データウェアハウスは生データが変換され、クエリ可能な形式で格納される場所です。
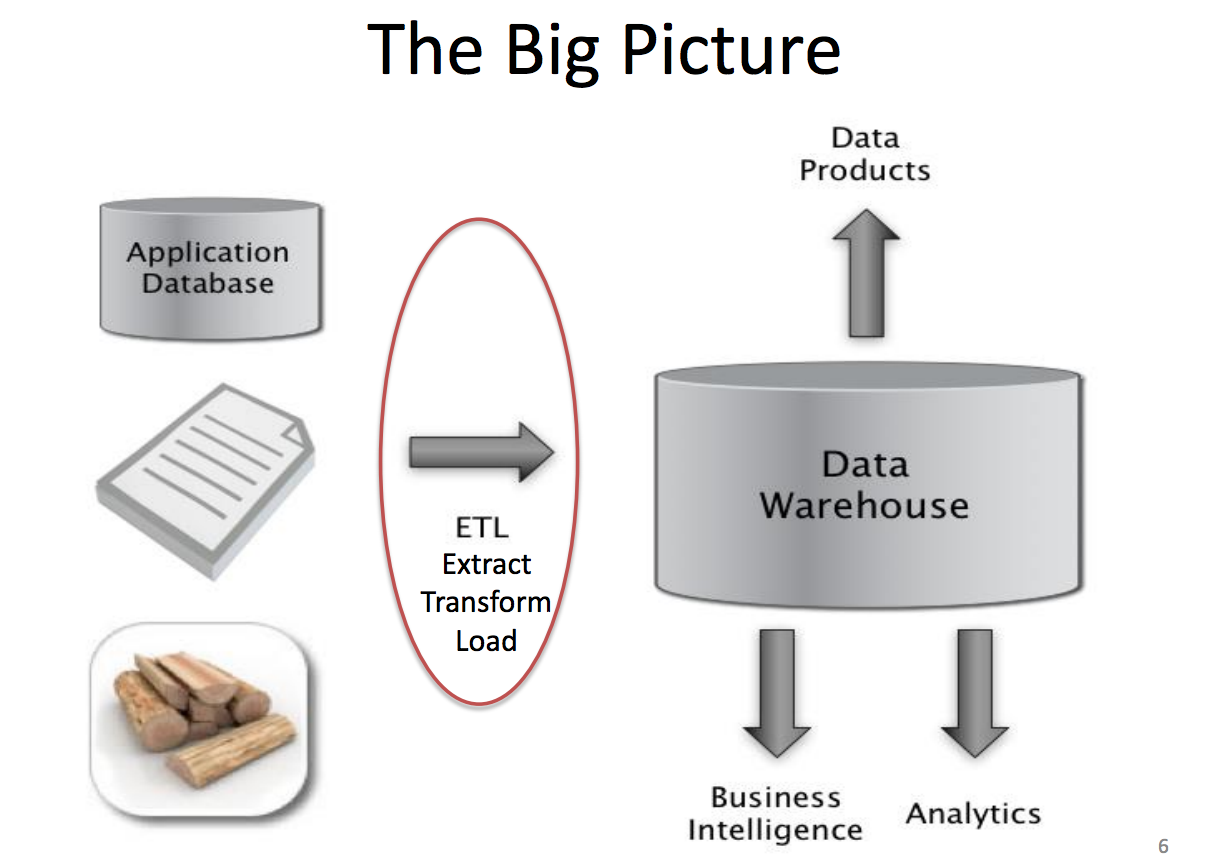 出典:UC Berkeley CS 194コースからのJeff Hammerbacherのスライド
出典:UC Berkeley CS 194コースからのJeff Hammerbacherのスライド
多くの点において、データウェアハウスは、高度な分析、ビジネスインテリジェンス、オンライン実験、機械学習などを可能にするエンジンであり、燃料でもあります。以下は、さまざまな段階の異なる企業のデータウェアハウスの役割を強調する具体的な例です。
500pxにおける分析環境の構築:この記事では、Samson Huが500pxが製品市場の範囲を超えて成長しようとした際に直面した課題について説明します。同氏は、データウェアハウスをどのようにゼロから構築したかを詳しく説明しています。
Airbnbの実験プラットフォームの拡張:Jonathon Parksは、Airbnbのデータエンジニアリングチームが、実験レポートフレームワークのような内部ツールにパワーを供給する専門的なデータパイプラインを構築した方法を説明しています。この仕事は、Airbnbの製品開発文化の形成と拡大に不可欠です。
Airbnbで家の価値を予測するための機械学習の利用:私自身によって書かれたものですが、なぜバッチ学習を構築するのか、なぜオフラインスコアリングの機械学習モデルは前もって多くのデータエンジニアリング作業を必要とするのかにつちえ説明しています。特に、特徴量エンジニアリング、構築、および学習データのバックフィルに関連する多くのタスクは、データエンジニアリングの仕事に似ています。
これらの基礎的なウェアハウスがなければ、データサイエンスに関連するすべての活動は高価になるか、またはスケーラビリティに欠けます。たとえば、適切に設計されたビジネスインテリジェンスウェアハウスがなければ、データサイエンティストは、よく尋ねられる同じ基本的な質問に対して異なる結果を報告することがあります。最悪の場合、誤って本番データベースに直接問い合わせをし、遅延やシャットダウンを引き起こします。同様に、実験レポートパイプラインがなければ、深い調査が必要な実験は甚だ手作業を繰り返し行うことになるでしょう。最終的にはラベル収集または特徴量計算をサポートするデータインフラストラクチャがなくても、トレーニングデータの構築には非常に時間がかかるかもしれません。
ETL:抽出、変換、およびロード
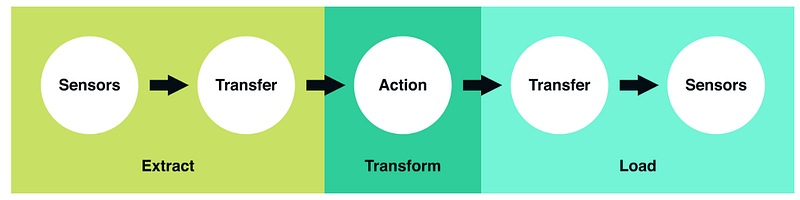
上で参照したすべての例は、Extract、Transform、およびLoadを表すETLという共通のパターンに従います。これらの3つの概念的なステップは、ほとんどのデータパイプラインがどのように設計され、構造化されているかを表しています。生データが分析可能データに変換される方法の青写真として機能します。このフローをより具体的に理解するために、Robinhoodのエンジニアリングブログから引用した次の画像が非常に有用であることに気づきました。
 出典:Vineet GoelのMedium上の記事「RobinhoodがAirflowを使用する理由」
出典:Vineet GoelのMedium上の記事「RobinhoodがAirflowを使用する理由」
抽出:センサが上流のデータソースが到着するのを待つステップです(上流のソースは、マシンまたはユーザが生成したログ、リレーショナルデータベースのコピー、外部データセットなどです)。利用可能になると、ソースの場所からさらなる変換に向けてデータを転送します。
変換:これがETLジョブの中心です。このステップではビジネスロジックを適用し、フィルタリング、グルーピング、および集計などのアクションを実行して、生データを分析可能データセットに変換します。このステップには、多くのビジネスの理解とドメインの知識が必要です。
ロード:最後に、処理されたデータをロードして最終的な目的地に転送します。多くの場合、このデータセットはエンドユーザーによって直接消費されるか、別のETLジョブの上流の依存性として処理され、いわゆるデータ系列を形成します。
すべてのETLジョブはこの共通のパターンに従いますが、実際のジョブそのものは使用方法、効用、および複雑さの点においてかなり異なるでしょう。これは、Airflowのジョブの非常にシンプルで簡単な例です:
出典:DataEngConf SF 2017のArthur Wiedmerのワークショップ
上記の例は、実行日時になってから1秒後に毎日bashで日付を出力するだけですが、現実のETLジョブははるかに複雑になる可能性があります。たとえば、本番データベースから一連のCRUD操作を抽出し、ユーザーの非アクティブ化などのビジネスイベントを導出するETLジョブがあるかもしれません。別のETLは、いくつかの実験設定ファイルを取り込み、その実験に関連するメトリックを計算し、最後にUIでp値および信頼区間を出力して、製品の変更がユーザーの解約を妨げているかどうかを知らせることができます。さらに別の例としは、数日後にユーザーが解約するかどうかを予測するために、機械学習モデルのための特徴を日次計算するバッチETLジョブがあります。可能性は無限大です!
ETLフレームワークの選択
ETLの構築に関しては、さまざまな企業が異なるベストプラクティスを採用する可能性があります。長年にわたり、多くの企業がETLを構築する際の共通の問題を特定する上で大きな進歩を遂げ、これらの問題をよりエレガントに解決するためのフレームワークを構築しました。
バッチデータ処理の世界では、いくつかの明白なオープンソースの競合があります。いくつか例を挙げると、Linkedinがオープンソース化したAzkabanは、Hadoopのジョブ依存関係を簡単に管理できるようにします。Spotifyが2014年にオープンソース化したPythonベースのフレームワークLuigi、同様に2015年にPinterestがPinballを、AirbnbがAirflow(こちらもPythonベース)をオープンソース化しました。
異なるフレームワークにはそれぞれ長所と短所があり、多くの専門家がそれらを幅広く比較しています(こちらとこちらを参照ください)。採用するフレームワークにかかわらず、いくつかの機能を検討することが重要です。
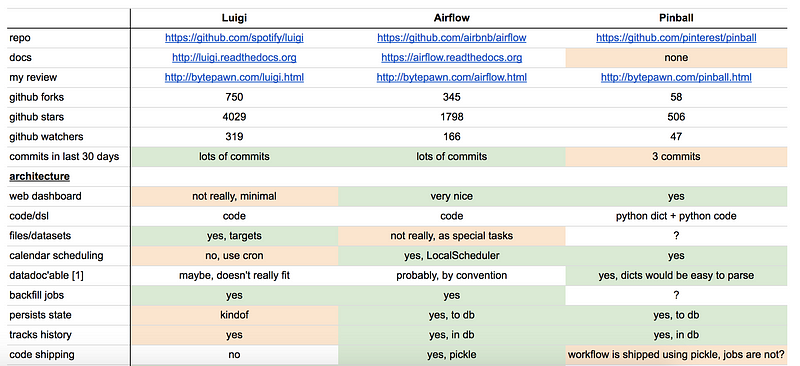 出典:Marty TrencseniのLuigi、Airflow、およびPinballの比較
出典:Marty TrencseniのLuigi、Airflow、およびPinballの比較
設定:元来ETLは複雑であり、データパイプラインのデータフローを簡潔に記述できる必要があります。その結果として、ETLがどのように作成されるかを評価することが重要となります。 UI、ドメイン固有の言語、またはコードで設定を行いますか?今日では、「Configuration as Code」の概念は普及し続けています。なぜなら、ユーザーがプログラム可能、カスタマイズ可能なパイプラインを表現できるよう構築できるためです。
UI、モニタリング、アラート:ジョブ自体にバグがない場合でも、長時間実行されるバッチ処理は必然的にエラー(クラスタ障害など)に陥る可能性があります。その結果、長時間実行されているプロセスの進行状況を追跡するには、監視とアラートが不可欠です。フレームワークは仕事の進捗状況に関してどんな視覚的情報を提供しますか?適時かつ正確にアラートや警告は表示されますか?
バックフィル:データパイプラインが構築されたら、時間を遡って過去のデータを再処理する必要があることがよくあります。理想的には、過去のデータをバックフィルするためのジョブと現在または将来のメトリックを計算するジョブの2つの別々のジョブを構築することは理想的ではありません。フレームワークはバックフィルをサポートしていますか?標準化され、効率的でスケーラブルな方法でこれを行うことができますか?これらはすべて重要な検討事項です。
私は、もちろんAirbnbで働く人としてAirflowを楽しんでいて、データエンジニアリングの仕事で遭遇した多くの一般的な問題に見事に対処してくれることを本当に感謝しています。デファクトのETLオーケストレーションエンジンとしてAirflowを正式に使用している120社以上の企業があることを考えると、Airflowは新世代のスタートアップ企業向けのバッチ処理の標準となる可能性があると主張するまであるかもしれません。
2つのパラダイム:SQL中心のETL v.s. JVM中心の ETL
上記からわかるように、企業ごとにETLを構築するためのツールとフレームワークは大幅に異なるため、新しいデータサイエンティストとしてどのツールに投資するかを決定するのは非常に混乱することがあります。
Washington Post Labsでは、ETLは主にCronで最初にスケジュールされ、ジョブはVerticaスクリプトとしてまとめられていました。 Twitterでは、ETLジョブはPigで構築されていましたが、最近はTwitterの独自のオーケストレーションエンジンScaldingによって書かれ、スケジュールされています。 Airbnbでは、データパイプラインは主にAirflowを使ってHiveで書かれています。
最初の数年間、私はデータサイエンティストとして働いていましたが、組織が選んだものをそのまま受け取り、従っていました。私がJosh Willの話に出会った後に、ETLのパラダイムは2つあり、データ・サイエンティストは会社に入社する前にどちらのパラダイムが好むのかを真剣に考えなるべきだと気づきました。
 ビデオソース:Josh WillsのKeynote @ DataEngConf SF 2016
ビデオソース:Josh WillsのKeynote @ DataEngConf SF 2016
JVM中心のETLは、通常JVMベースの言語(JavaやScalaなど)で構築されます。これらのJVM言語のデータパイプラインに対するエンジニアリングは、しばしば命令的な方法でデータ変換を考えることを伴います(例えば、キーと値のペアなど)。ユーザー定義関数(UDF)の作成には、あまり苦労はしません。なぜなら、異なる言語で記述する必要がなく、同じ理由でテストジョブを簡単に行うことができるためです。このパラダイムはエンジニアにとって非常に一般的です。
SQL中心のETLは、通常、SQL、Presto、またはHiveなどの言語で作成されます。 ETLジョブはしばしば宣言的な方法で定義され、ほとんどすべてがSQLとテーブルを中心としています。 UDFの作成は、異なる言語(JavaやPythonなど)で記述する必要があるため、時には面倒であり、これによりテストがさらに難しくなる可能性があります。このパラダイムはデータサイエンティストに人気があります。
両方のパラダイムの下でETLパイプラインを構築したデータサイエンティストとして、私はもちろんSQL中心のETLが好きです。実際、私は、新しいデータサイエンティストとして、SQLパラダイムで操作するときに、データエンジニアリングについてもっと迅速に学ぶことができると主張しています。なぜでしょうか? SQLの学習はJavaやScalaを習得するよりもはるかに簡単です(すでに慣れていない場合)。新しい言語の上に新しいドメインを構築するよりも、データエンジニアリングのベストプラクティスの学習に力を注ぐことができます。
ビギナーズガイドまとめ - 第一部
この記事では、分析がいくつかのレイヤーの上に構築されていることを学びました。そして、成長する組織をスケールさせるためには、データウェアハウスの構築などの基礎的な作業が不可欠です。 ETLを構築するためのさまざまなフレームワークとパラダイムについて簡単に説明しました。しかし、学習することや議論することはまだまだあります。
このシリーズの二つ目の記事では、具体的な内容に触れ、AirflowでHiveバッチジョブを構築する方法をお見せします。具体的には、Airflowジョブの基本的な分析を学び、パーティションセンサやオペレータなどの構成要素を介してアクションの抽出、変換、ロードを確認します。スタースキーマなどのデータモデリング手法を使用してテーブルを設計する方法を学習します。最後に、非常に有用ないくつかのETLベストプラクティスについて説明します。